
Let me start by asking, What’s all this “In-Kernel verses Virtual Storage Appliance” debate all about?
It seems to me to be total nonsense yet it is the focus of so called competitive intelligence and twitter debates. From an architectural perspective I just don’t get why it’s such a huge focus when there are so many other critical areas to focus on, like the benefit of Hyper-Converged vs SAN/NAS!!!
Saying In-Kernel or VSA is faster than the other (just because of where the software runs) is like saying my car with 18″ wheels is faster than your car with 17″ wheels. In reality there are so many other factors to consider, the wheel size is almost irrelevant, as is whether or not storage is provided “In-Kernel” or via a “Virtual Appliance”.
If something is In-Kernel, it doesn’t mean it’s efficient, it could be In-Kernel and really inefficient code, therefore being much worse than a VSA solution, or a VSA could be really inefficient and an In-Kernel solution could be more efficient.
In addition to this, Hyper-converged solutions are by design scale-out solutions, as a result the performance capabilities are the sum of all the nodes, not one individual node.
As long as a solution can provide enough performance (IOPS) per node for individual (or scaled up) VMs and enough scale-out to support all the customers VMs, it doesn’t matter if Solution A is In-Kernel or VSA, or that the solution can do 20% or even 100% more IOPS per node compared to solution B. The only thing that matters is the customers requirements are met/exceeded.
Let’s shift focus for a moment and talk about the performance capabilities of the ESX/ESXi hypervisor as this seems to be argued as an significant overhead which prevents a VSA from being high performance. In my experience , ESXi has never been a significant I/O bottleneck, even for large customers with business critical applications as the focus on Biz Critical Apps really took off around the VI3 days or later where the hypervisor could deliver ~100K IOPS per host.
The below is a chart showing VMware’s tested capabilities from ESX 1, through to vSphere 5 which was released in July 2011.
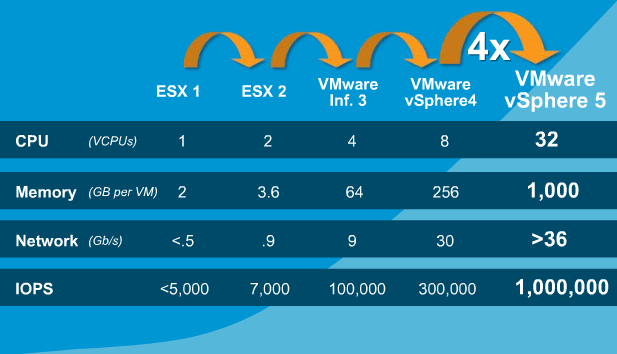
What we can clearly see is vSphere 5.0 can achieve 1 Million IOPS (per host), and even back in the VI3 days, 100,000 IOPS.
In 2011, VMware wrote a great article “Achieving a Million I/O Operations per Second from a Single VMware vSphere® 5.0 Host” which shows how the 1 million IOPS claim has been validated.
In 2012 VMware published “1 million IOPS On 1VM” which showed not only could vSphere achieve a million IOPS, but it could do it from 1 VM.
I don’t know about you, but it’s pretty impressive VMware has optimized the hypervisor to the point where a single VM can get 1 million IOPS, and that was back in 2012!
Now in both the articles, the 1 million IOPS was achieved using a traditional centralised SAN, the first article was with an EMC VMAX with 8 engines and I have summarized the setup below.
- 4 quad-core processors and 128GB of memory per engine
- 64 front-end 8Gbps Fibre Channel (FC) ports
- 64 back-end 4Gbps FC ports
- 960 * 15K RPM, 450GB FC drives
The IO profile for this test was 8K , 100% read, 100% random.
For the second 1 million IOPS per VM test, the setup used 2 x Violin Memory 6616 Flash Memory Arrays with the below setup.
- Hypervisor: vSphere 5.1
- Server: HP DL380 Gen8
CPU: 2 x Intel Xeon E5-2690, HyperThreading disabled
Memory: 256GB - HBAs: 5 x QLE2562
- Storage: 2 x Violin Memory 6616 Flash Memory Arrays
- VM: Windows Server 2008 R2, 8 vCPUs and 48GB.
Iometer Config: 4K IO size w/ 16 workers
For both configurations, all I/O needs to traverse from the VM, through the hypervisor, out HBAs/NICs, across a storage area network, through central controllers and then make the return journey back to the VM.
There is so many places where additional latency or contention can be introduced in the storage stack it’s amazing VMs can produce the level of storage performance they do, especially back 3 years ago.
Chad Sakac wrote a great article back in 2009 called “VMware I/O Queues, Microbursting and Multipathing“, which has the below representation of the path I/O takes between a VM and a centralized SAN.
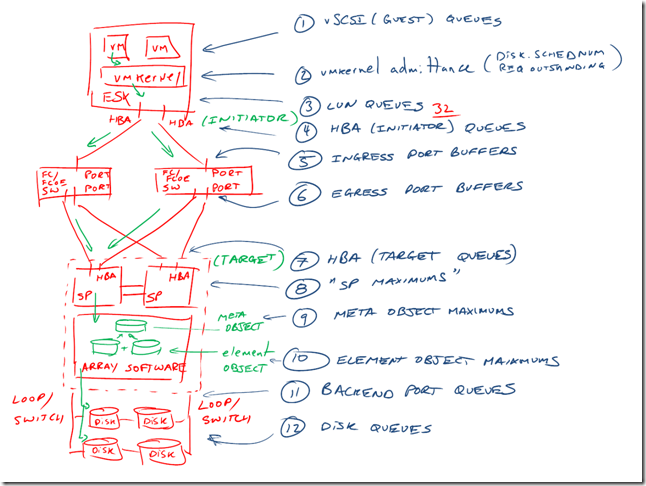
As we can see, Chad shows 12 steps for I/O to get to the disk queues, and once the I/O is completed, the I/O needs to traverse all the way back to the VM, so all in all you could argue it’s a 24 step round trip for EVERY I/O!
The reason I am pointing this out is because the argument around “In-kernel” verses “Virtual Storage Appliance” is only about 1 step in the I/O path, when Hyper-Converged solutions like Nutanix (which uses a VSA) eliminate 3/4’s of the steps in an overcomplicated I/O path which has been proven to achieve 1 million IOPS per VM.
Andre Leibovici recently wrote the article “Nutanix Traffic Routing: Setting the story straight” where he shows the I/O path for VMs using Nutanix.
The below diagram which Andre created shows the I/O path (for Read I/O) goes from the VM, across the ESXi hypervisor to the Controller VM (CVM) which then using DirectPath I/O to directly access the locally attached SSD and SATA drives.
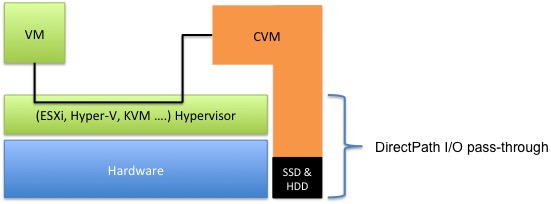
Consider if the VM in the above diagram was a Web Server and the CVM was a database server and they were running in an environment with a SAN/NAS. The Web Server would be communicating to the DB server over the network (via the hypervisor) but the DB Server would have to access it’s data (that the Web Server requested) from the centralized SAN, so in the vast majority of environments today (which are using SAN/NAS) the data is travelling a much longer path than it would compared to a VSA solution and in many cases traversing from one VM to another across the hypervisor before going to the SAN/NAS and back through a VM to be served to the VM requesting the data.
Now back to the diagram, For Nutanix the Read I/O under normal circumstances will be served locally around 95% of the time, this is thanks to data locality and how Write I/O happens.
For Write I/Os, one copy of each piece of data is written locally where the VM is running which means all subsequent Read I/O can be served locally (and freshly written data is also typically “Active data”), and the 2nd copy is replicated throughout the Nutanix cluster. This means even though half the Write I/O (of the two copies) needs to traverse the LAN, it doesn’t hit a choke point like a traditional SAN, because Nutanix scales out controllers on a 1:1 ratio with ESXi hosts and writes are distributed throughout the cluster in 1MB extents.
So if we look back to Chad’s (awesome!) diagram, Hyper-converged solutions like Nutanix and VSAN are only concerned with Steps 1,2,3,12 (4 total) for Read I/O and 1,2,3,12 as well as 1 step for the NIC at the source & 1 step for the NIC at the destination host.
So overall it’s 4 steps for Read, 6 steps for Write, compared to 12 for Read and 12 for Write for a traditional SAN.
So Hyper-converged solutions regardless of In-Kernel or VSA based remove many of the potential points of failure and contention compare to a traditional SANNAS and as a result, have MUCH more efficient data paths.
On twitter recently, I responded to a tweet where the person claims “Hyperconverged is about software, not hardware”.
I disagree, Hyper-converged to me (and the folk at Nutanix) is all about the customer experience. It should be simple to deploy, manage, scale etc, all of which constitute the customers experience. Everything in the datacenter runs on HW, so I don’t get the fuss on the Software only vs Appliance / OEM software only solution debate either, but this is a topic for another post.
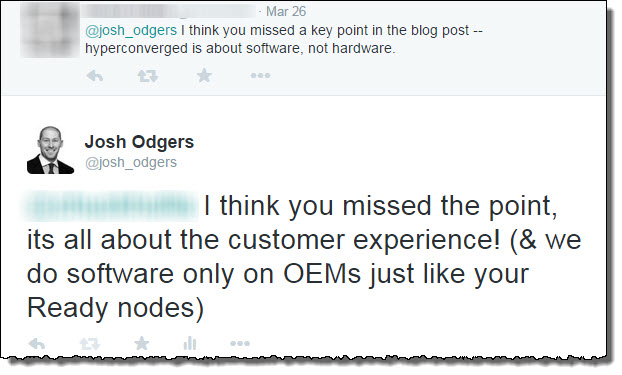
I agree doing things in software is a great idea, and that is what Nutanix and VSAN do, provide a solution in software which combines with commodity hardware to create a Hyper-converged solution.
Summary:
A great customer experience (which is what I believe matters) along with high performance (1M+ IOPS) solution can be delivered both In-Kernel or via a VSA, it’s simple as that. We are long past the days where a VM was a significant bottleneck (circa 2004 w/ ESX 2.x).
I’m glad VMware has led the market in pushing customers to virtualize Business Critical Apps, because it works really really well and delivers lots of value to customers.
As a result of countless best practice guides, white papers, case studies from VMware and VMware Storage Partners such as Nutanix, we know highly compute / network & storage intensive applications can easily be virtualized, so anyone saying a Virtual Storage Appliance can’t (or shouldn’t) be, simply doesn’t understand how efficient the ESXi hypervisor is and/or he/she hasn’t had the industry experience deploying storage intensive Business Critical Applications.
To all Hyper-converged vendors: Can we stop this ridiculous debate and get on with the business of delivering a great customer experience and focus on the business at hand of taking down traditional SAN/NAS? I don’t know about you, but that’s what I’ll be doing.
Josh, i agree this “my car is faster than yours” debate is totally pointless and a distraction.
That said, one interesting point; Nutanix uses DirectPath IO from the CVM to the underlying hardware, other VSA solutions (such as HP) dont. The other VSA solutions rely on traditional vscsi stack with vmdk’s. I would say the argument of Nutanix vs In Kernel is pointless, but the argument of In-Kernel vs VSA’s not using DirectPath is totally valid (think of the vscsi queues etc).
Regardless, all that really matters is being able to satisfy customer requirements in the most cost effective way possible, hardware always has (and always will be) just a mechanism.
Couldnt agree more. Thanks for the comment Neil.
— Disclosure NetApp Employee —
With all due respect to a good post, I think you’ve oversimplified your I/O Path, Chad’s diagram is good because it’s remarkably complete …
IMHO you’d need at least to include steps 9, 10 and 11 and for non-local I/O you should also include 4,5,6 and 7
— start TL;DR justification
in pretty much any storage software design there are meta-object and target-objects within the storage virtualisation layer each with their own limits. That’s not exactly how I’d deconstruct them in ONTAP, but I know where he’s coming from, and I’m reasonably sure that Nutanix has something that could be reasonably described as a meta-objects and element objects within the controller VM (CVM), there’s even a point where Andre in his blog mentions the use of standard device drivers which more or less corresponds to the element object, and the last time I checked device drivers usually have configured queue depth maxima. Neatly encapsulating those into one large CVM block doesn’t really allow an easy or IMHO accurate compare to Chad’s diagram.
Also for anything data traversing the ethernet network you’d need some equivalents to chads points 4,5,6, and 7 because an east-west ethernet fabric looks increasingly like a fibre channel fabric of the past (its a weak statement, but I can justify it and this TL;DR is already too TL.)
— end TL;DR justification
I’m not saying that a constructive debate outlining the benefits and tradeoffs of a hyper converged infrastructure doesn’t make sense, despite my employment by NetApp, I think there are some solid benefits of a hyper converged architecture for a broad set of use cases. but I don’t really think you’ve been as meticulous in deconstructing the Nutanix architecture as Chad did for SAN, so for me, the “we only require a quarter as many steps” statement really holds up, nor do I really think it’s relevant to the larger discussion of the business and operational benefits.
I get where you are coming from with the whole “Its in Kernel so therefore it’s better !” argument, but IMHO speeds and feeds are mostly irrelevant today, given enough flash and CPU in enough locations you can supply more performance than most people will need.
You’re downplaying kernel paths without actually documenting your own path to data. You’re just confusing the issue further. Disprove with data, not just more noise. Saying nutanix is “just 1 step” is grossly over simplifying. NFS conversion? Network traffic? Your own handling of the data? The replication mechanism before Ack’ing?
I’m not defending either side of the argument, I’m merely pointing out you haven’t “proved” anything.
Firstly, thanks for the comment – all feedback is welcome.
Unfortunately the goal of this post is not to prove In-Kernel or VSA to be better, if that’s what your after, this is not the aim of this post.
I think this post could be summed up by this tweet
https://twitter.com/quinney_david/status/582421255632109568
which says:
“Traversing the hypervisor is not a bottleneck.”
Now that statement is oversimplified but the point from my perspective is, In-Kernel & VSA are both valid ways to provide storage in the hyper-converged world and there is no point arguing over which is better, especially when it comes to performance. As per John’s comment, which I totally agree with :
“IMHO speeds and feeds are mostly irrelevant today, given enough flash and CPU in enough locations you can supply more performance than most people will need.”
Cheers
Cheers for the clarification, I too caught the argument on Twitter but VSAN in kernel had then entered the fray. Further confusing matters
I take your point on the topic of choice, but you’re diagram of the kernel paths needs a documented comparison to be a fair challenge to the stigma.
Personally I don’t think it matters how fast, faster is, so long as it’s fast enough!
it’s the offerings extra capabilities that sell the product. If you find yourself argueing hyper converged vs standard h/w or even vsan on a performance front alone, away from the other values hyper C deliver, I’d say the point has been lost!
Totally agree the value in hyperconverged systems is the customer experience, which comes from things like ease of use, feature set, value for money, data reduction etc. The outright performance is less relevant, and higher performance is great but only with equivalent data services / value for customers.
Very rarely do I talk to customers about performance compared to other products and that doesn’t matter to me or the customer – it’s about the value of the total solution not if it’s better than something else.
Tick box arguments are also a pet hate of mine.
As someone who sits on the customer side of the fence who constantly evaluates storage solutions multiple times a year for very different business needs, I don’t really care how the solution does it, be it in kernel or off kernel as long as it meets the business needs from a cost, manageability, supportability, experience, requirements, strategy etc. + my pet hate political reasons! I don’t even believe in NoSAN/NAS as there are still many use cases for them.
I vote to put the in-kernel vs off-kernel debate behind and concentrate on making your own products better!
Hi Josh — Chuck (VSAN guy) here
If I understand the gist of your argument, it’s that since the hypervisor itself does great IO and delivers great performance, any VSA or storage layer built on top of the hypervisor should also deliver great IO and performance.
Our point is that (a) there’s additional overhead required to navigate into a CVM and out again, (b) the CVM itself uses a non-trivial amount of resources (memory and CPU), and (c) unlike the hypervisor itself, the CVM can’t make smart decisions about overall resource usage and optimization within the cluster.
I would disagree that this doesn’t matter, etc. We meet plenty of customers who are concerned about performance and consolidation ratios. That’s why we’re discussing the topic.
We’ve made an initial effort to characterize VSAN performance in this recent white paper http://www.vmware.com/files/pdf/products/vsan/VMware-Virtual-San6-Scalability-Performance-Paper.pdf
You’ll notice that this isn’t a “lab queen” benchmarketing situation — it’s transparent disclosure of how VSAN performs on middle-of-the-road hardware under a variety of scenarios.
It’d be great to see something similar from the Nutanix folks — it’s the type of information customers can use to make informed decisions.
Thanks!
— Chuck
Josh. The title of your blog is in kernel vs virtual storage appliance. I personally have the opinion that in kernel is better. Nutanix uses the argument that the hypervisor is amazing and we shouldn’t be worried about a VSA sitting in the hypervisor. There have been several blogs and many comments that discuss why the VSA approach isnt the most optimal so no need for me to repeat. I think placing a workload like SQL into a vm has proven to yield great performence. I guess I just find it difficult to believe that if you run all that IO through another vm first before the direct IO path to the storage, performance would stay the same as in kernel.
Maybe a simple lab demonstration of a particular workload on a Nutanix platform vs a similarly spec’s VSAN platform measuring performance and latency would help to illustrate real results instead of “this person tweeted this, and I couldn’t agree more” type comments.
I personally have probably listened to more opinion than fact in formulating my opinion as well, so this lab exercise would be interesting.
@chuck – If in kernel is the way to go, why is NSX deployed via virtual appliances (NSX manager and controllers). Is your reasoning that only the data plane needs to reside in kernel?
Hi forbsy
I have personally performed numerous tests which you have requested however due to the VMware EULA I am not permitted to release them nor are vmware customers.
Since I cant release the results, there is no point saying anything more on the topic since i cant release the data.
However I will say, max/peak performance of a single node in a scale out archiecture is much less critical than for a centralized storage controller, so if inkernel is/was faster, how much would that even matter? The answer would be “it depends” and in most cases, id suspect peak/max performance is probably <10% of the factors which customers actually need.
As i mentioned in the post the customer experience is key and if storage is delivered inkernel or via vsa it has little/no impact on the outcome since a VSA can deliver tens of thousands of <=1ms IO. Happy to agree to disagree on this point, and thanks for your comment.
Netapp employee Yada yada
Josh, it’s almost disappointing the argument is being framed in a in-kernel vs hypervisor way, because from where I see things right now, it’s a trivial implementation detail. At some point there might be some interesting / simplified QoS integration between NSX and VSAN but AFAIK even that doesn’t neccesitate that both are in-kernel
What would be more interesting is a comparison of the impact of VSANs FULLY distributed datastores vs nutanix’s “local if practical” data path. In theory, That would in many cases have a bigger impact on steady state latency than being in memory or not, it would also be interesting to see a comparative impact during and after VM migration.
Unfortunately the industry practice preventing benchmark publication makes this really hard to do outside of theory crafting that most aren’t able to fully appreciate.
Maybe we can all use a common open source baseline to measure against like say CEPH + KVM, or good old shared NFS from a well specified Linux server.
Regards
John
Hi John
I couldnt agree more regarding inkernel and vsa both being trivial implimentation details. In fact that was the main point of the post. (I hope that came across)
I also agree NSX / VSAN (or any other HCI storage integration for that matter) doesnt neccesitate things being in-kernel.
I actually think showing solution based outcome reference architecturs / case studies is what is important rather than how they are achieved.
At the end of the day, the customer experience is what matters, not implimentation details as you mentioned.
Thanks for the comment.
Interesting article coming at a very opportune time. I’m in the middle of a head-to-head comparison of a Nutanix cluster vs vSAN 6 with a typical hardware vendor of like Nutanix hardare.
Having a lot of experience with DirectPath IO and RDMs, my own experience is there is still some level of latency introduced. The real question seems to be at what point in the cluster’s utilization does that latency start to become a problem in comparison.
Additionally, I see other scenarios where once heavy IO begins or cluster saturation begins, that is where InKernel starts to really shine as other technologies such as a vDS with NIOC are also able to step in.
But also, in-kernel has advantages in HA scenarios where the primary node & its’ CVM are down– or perhaps the disk(s) are down but the CVM isn’t.
At the end of the day though– if you stack two “like hardware” clusters where neither is overcommitted to where there is enough resources for the CVMs to run freely, I haven’t seen any difference one way or another (yet). So, as with everything else in the virtualization world– it’s all about the workload & use-case.
Totally agree it’s all about the workload and use case. Performance is only one of countless factors, and the way storage is provided is an implementation detail.
I agree Direct-Path I/O (and any abstraction layers) introduce overheads, my point would be they are insignificant, especially in a scale out architecture where performance of one VSA or node is much less critical than a dual controller SAN.
In-Kernel or VSA both use CPU/RAM to provide storage capabilities, in my testing neither is limited to a set percentage of resources and CPU usage depends on workload. vDC and NIOC work with VSA as well, which is a recommendation in our vNetworking BPG, but in most environments, even very busy ones, I rarely see NIOC actually kick in, Load Based Teaming yes, but NIOC, rarely as most of our I/O is served locally removing the network as a choke point.
Thanks for your comments.
It seems like the decision makers in your company disagree with you Josh. Looks like they want to acquire in kernel technology to speed up Nutanix IO. Clearly, the in kernel camp was correct:
http://www.theregister.co.uk/2016/07/01/hyperconverged_nutanix_could_be_buying_vmcare_cacher_pernixdata/
I approved this comment for comedy as he has no idea what he is talking about. Its funny how people make assumptions and make asses out of themselves.