
I saw the below picture posted on Twitter, and there has been some discussion around the de-duplication ratio (shown below as an an amazing 28.4:1) and what this should and should not include.
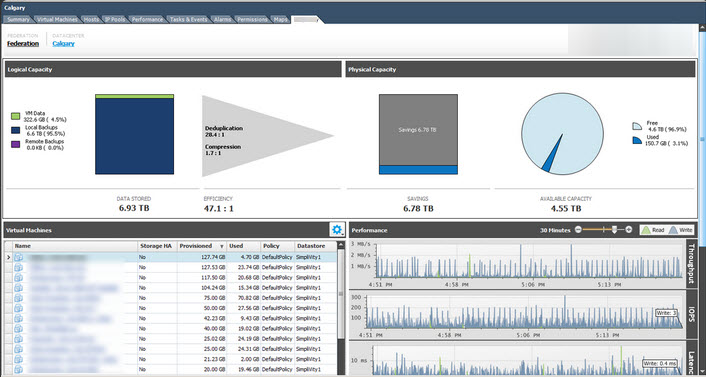
In the above case, this ratio includes VM snapshots or what some people in my opinion incorrectly refer to as “backups” (But that’s a topic for another post). In other storage solutions, things like savings from intelligent cloning may also be included.
First l’d like to briefly explain what de-duplication means to me.
I think the below diagram really sums it up well. If 12 pieces of data exist (ie: Have been written or are in the process of being written in the case of in-line de-duplication) to the storage layer, de-duplication (in-line or post process) removes the duplicate data and uses pointers to direct duplicates back to a single copy rather than storing duplicates.
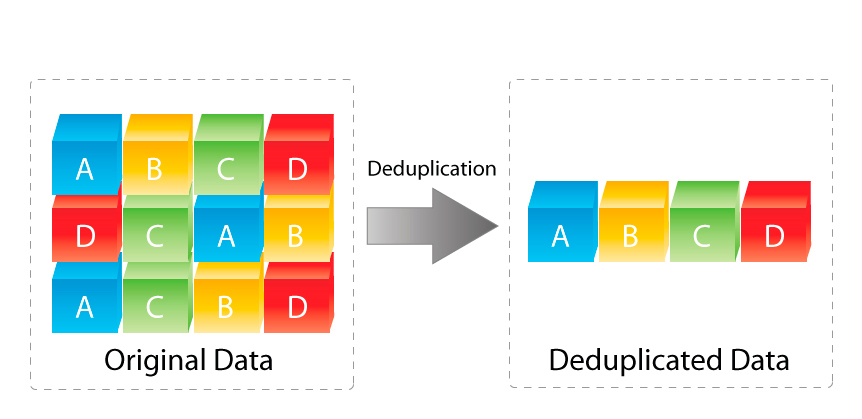
The above image is courtesy of www.enterprisestorageguide.com.
In the above example, the original data has 12 blocks which have been de-duplicated down to 4 blocks.
With this in mind, what should be included in the de-duplication ratio?
The following are some ways to reduce data consumption which in my opinion add value to a storage solution:
1. De-duplication (In-line or post process)
2. Intelligent cloning i.e.: Things like VAAI-NAS Fast File Clone, VCAI, FlexClone etc
3. Point in time snapshot recovery points. (As they are not backups until stored elsewhere)
Obviously, if data that exists or is being written to a storage system and its de-duplicated in-line or post process, this data reduction should be included in the ratio. I’d be more than a little surprised if anyone disagreed on this point.
The one exception to this is where VMDKs are Eager Zeroed Thick (EZT) and de-duplication is simply removing 0’s which in my opinion is simply putting additional load on the storage controllers and over inflating the de-duplication ratio when thin provisioning can be used.
For storage solutions de-duplicating zeros from EZT VMDKs, these capacity savings should be called out as a separate line item. (Discussed later in this post).
What about Intelligent cloning? Well the whole point of intelligent cloning is not to write or have the storage controllers process duplicate data in the first place. So based on this, VMs which are intelligently cloned are not deduped as duplicate data is never written or processed.
As such its my opinion Intelligent cloning savings should not be included in the de-duplication ratio.
Next lets talk “point in time snapshot recovery points“.
The below image shows the VM before a snapshot (a.) has blocks A,B,C & D.
Then after a snapshot without modifications, the VM has the same blocks A,B,C & D.
Then finally, when the VM makes modifications to or deletes data after the snapshot, we see the A,B,C & D remain in tact thanks to the snapshot but then we have a deleted item (B) then modified data (D+) along with net new data E1 & E2.
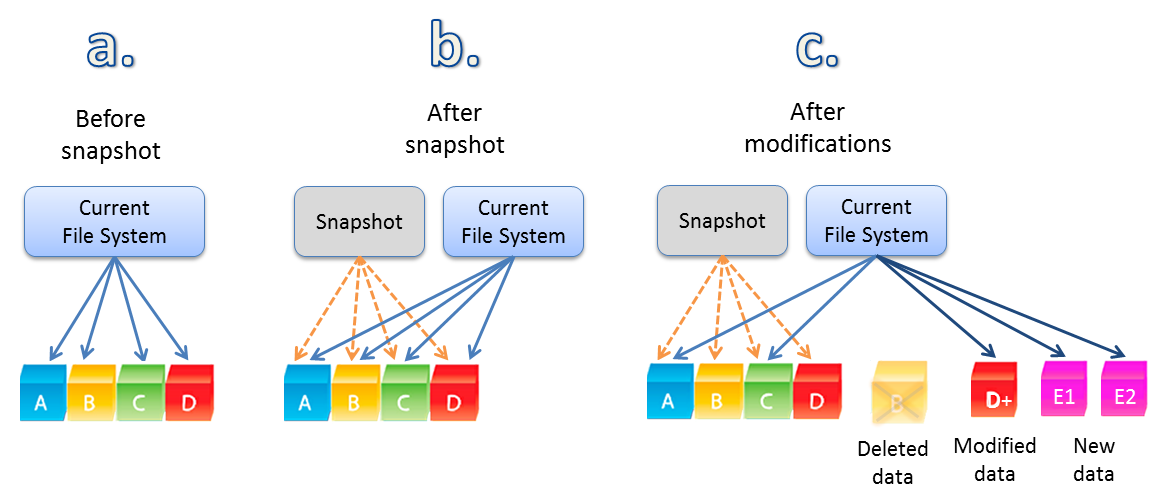
Image courtesy of www.softnas.com.
So savings from snapshots are also not “de-duplicating” data, they are simply preventing new data being written, much like intelligent cloning.
As with Intelligent cloning savings, my opinion is savings from snapshots should not be included in the de-duplication ratio.
Summary
In my opinion, the de-duplication ratio reported by a storage solution should only include data which has been written to disk (post process), or was in the process of being written to disk (in-line) that has been de-duplicated.
But wait there’s more!
While I don’t think capacity savings from Intelligent cloning and snapshots should be listed in the de-duplication ratio, I think these features are valuable and the benefits of these technologies should be reported.
I would suggest a separate ratio be reported, for example, Data Reduction.
The Data reduction ratio could report something like the following where all capacity savings are broken out to show where the savings come from:
1) Savings from Deduplication: 2.5:1 (250GB)
2) Savings from Compression: 3:1 (300GB)
3) Savings from Intelligent Cloning: 20:1 (2TB)
4) Savings from Thin Provisioning: 50:1 (5TB)
5) Savings from Point in time Snapshots: 30:1 (3TB)
6) Savings from removal of zeros in EZT VMDKs: 100:1 (10TB)
Then the Total data reduction could be listed e.g.: 60.5:1 (20.7TB)
For storage solutions, the effective capacity of each storage tiers (Memory/SSD/HDD) for example could also be reported as a result of the data reduction savings.
This would allow customers to compare Vendor X with Vendor Y’s deduplication or compression benefits, or compare a solution which can intelligently clone with one that cannot.
Conclusion:
The value of deduplication, point in time snapshots and intelligent cloning in my mind are not in question, and I would welcome a discussion with anyone who disagrees.
I’d hate to see a customer buy product “X” because it was advertised to have a 28.4:1 dedupe ratio and then find they only get 2:1 because they don’t for example take 4 hourly snapshots of every VM in the environment.
The point here is to educate the market on what capacity savings are achieved and how so customers can compare apples with applies when making purchasing decisions for datacenter infrastructure.
As always, feedback is welcomed.
*Now I’m off to check what Nutanix reports as de-duplication savings. 
Great post Josh, me and my colleagues discovered while testing thin reclaim on Nutanix nfs datastores, that if you write a stream of zeroes at the OS level (sdelete), the VMDK will automatically shrink after sometime without storage vMotion required.
Just curious if this is part of the vaai nfs primitives or some Nutanix magic going on under the hood
Hey David, Nutanix doesn’t write white space to disk so the write command will be issued and received by Nutanix and it will be acknowledged but only metadata is written. This improves performance and reduces wasted capacity.
Pingback: Newsletter: January 4, 2015 | Notes from MWhite
Full disclosure: I am an SA for SimpliVity.
Thanks for the great article Josh and the great screenshot of Trevor’s efficiency rating. I just wanted to point out some differences in our solution vs. what you’re describing as “snapshots” above. We do VM centric full backups when we run a backup, we don’t do snapshots.
Because we have accelerated inline deduplication of ALL data and because we never duplicate a block of data once stored anywhere in the federation of OmniStack systems we are able to count backups as fully deduplicated data sets. e.g. If you were to run a backup on a non-OmniStack solution you would have to account for the additional storage required to store that backup on another device. With SimpliVity you don’t. If storing backups within the local datacenter we never duplicate blocks so we don’t have to account for additional backup space. When sizing for storage we account for primary storage and change rate of primary storage. All full backups at a local site, with OmniStack, are zero bytes. When full backups are stored elsewhere, we only send unique blocks (4KB – 8KB blocks) to the destination. We size the remote destination for the data set to be protected and the change rate of that data set. (This is worst case since we have a global deduplicated pool of blocks the destination is generally smaller than the primary.) We can store hundreds of thousands of full backups in a federation today without impact to physical storage and without producing additional IO during a full backup.
I hope this clears up the differences between a SimpliVity solution, which your showing, and everyone else. We have truly changed the way that data is managed throughout the enterprise with our Data Virtualization Platform and customers love it.
Ron
Hey Ron, great to see Simplivity folks contributing to Nutanix forums. Welcome! FYI I’m an SE with Nutanix.
To me it sounds like the difference between snapshots and backups (as the word is used here) is a semantic one. Either way, zero data is being duplicated, the snapshot (or backup) is instant, and it can be restored instantly, used to make other VMs (via cloning) or replicated to other clusters or platforms. Backups are certainly one use case for snapshots but not the only one.
Also it seems odd to call the data deduplicated if it was never duplicated in the first place. It’s more like “noduplication” or something right?
Steve
Josh and all who have commented, great topic and discussion. Before I jump in, a disclaimer I’m with Pure Storage.
I’m very happy to see storing data in a highly efficient manner has become the new norm. Data reduction technologies can greatly reduce both acquisition and environmental (rack space, power, cooling, etc) costs of storage allowing organizations a means to scale the volume of data in their data centers.
With the benefits of data reduction technologies the market does not speak the same language. This is problematic and is the core of Josh’s point – and frankly, I agree with Josh.
Data reduction should be defined by the means to store more ‘data’ than the logical capacity of the medium. In my opinions this would include technologies like data deduplication, data compression, metadata or pointer based forms of data cloning, and snapshot based recovery points.
Dynamic provisioning technologies – aka thin provisioning and it’s supporting attributes including zero removal, pattern removal, and deleted data reclamation (aka unmapping) – do not reduce data capacity and in my opinion should not be reported much less marketed as such. Dynamic provisioning allows more data to be stored by replacing static capacity allocation with on-demand dynamic capacity consumption.
Thin provisioning produces completely useless data. Consider this simple example: Store 10GBs of data in a 100GB thin VMDK results in a 10:1 savings. Increase the size of the VMDK to 1TB and the savings increase to 100:1 yet the capacity of data and the capacity that can be stored on the storage system are unchanged.
See how misleading it can be to market the results from dynamic provisioning technologies? I’ve shared my view on this numerous times, with the latest being…
http://purestorageguy.com/2013/12/13/understanding-thin-provisioning-does-it-reduce-storage-capacity/
At Pure Storage we separate data reduction and dynamic provisioning in reporting FlashReduce savings. I should add – our numbers do not include data cloning or snapshots. We have recently revisited this discussion and these items may be included in a future release.
All storage vendors who offer data reduction technologies should be proud of their products. As technologists and technology advocates let’s cut through the marketing nonsense and misinformation by advocating for the exclusion of dynamic provisioning results in data reduction discussions.
As always, pardon any typos
– cheers,
v
——Disclaimer Real Nutanix Customer—–
When I talk to any storage vendor I always ask they simple question as this is a real life scenario that I have experienced.
I have 1 File Server VM with a 50GB C: Drive 20GB of that is being used and a 1TB D: drive in which zero space being used. I configure the VMDK’s to be Thin Provisioned inside of VMware.
How much space am using in your storage subsystem? As a Nutanix customer I know that I use a total of 20GB. Because this is the first VM on the system. I am also taking hourly snapshots of this VM, done at a per VM level.
I am also asynchronously replicating this VM to my other Nutanix located in London over WAN link. The snaps going over very quickly as nothing has really changed since we spun up the VM. The 20GB difference is all that is being used at the secondary system.
The next day my creative team has created a few internal commercials and saved the H.264 video files onto the file server at 10:10am. These commercials totaled 500GB worth of video.
The Nutanix now is using around 520GB of total storage and my snapshot delta between 10:00 and 11:00 has shot up to 500GB. The replication traffic between NY and London on my has shot up as well as it is trying to replicate that 500GB snapshot to the other location.
The next day my creative team does the same task and uploads them to the fileserver but only creates 200GB worth of video.
How much data does my system use now? How much has been replicated to the secondary system in London the second day and how much data is used at the secondary site?. What is my dedupe ratio? What happens if my datacenter in NY is destroyed?
PS >> I love my Nutanix and they were the only vendor that didn’t talk unicorns and rainbows but actually talked about “use-able storage” not “effective capacity” or overblown Dedupe numbers as not all data dedupes.
Hi Ray,
To ensure I get you the correct answer, flick me your details and I’ll get one of our SREs to review your system to give you a breakdown and explanation of the capacity utilization.
vcdx90@nutanix.com
Cheers
Pingback: Nutanix Platform Link-O-Rama | vcdx133.com