
At VMware vForum Sydney this week I presented “Taking vSphere to the next level with converged infrastructure”.
Firstly, I wanted to thank everyone who attended the session, it was a great turnout and during the Q&A there were a ton of great questions.
One part of the presentation I got a lot of feedback on was when I spoke about Performance and Scaling and how this is a major issue with traditional shared storage.
So for those who couldn’t attend the session, I decided to create this post.
So lets start with a traditional environment with two VMware ESXi hosts, connected via FC or IP to a Storage array. In this example the storage controllers have a combined capability of 100K IOPS.

As we have two (2) ESXi hosts, if we divide the performance capabilities of the storage controllers between the two hosts we get 50K IOPS per node.
This is an example of what I have typically seen in customer sites, and day 1, and performance normally meets the customers requirements.
As environments tend to grow over time, the most common thing to expand is the compute layer, so the below shows what happens when a third ESXi host is added to the cluster, and connected to the SAN.
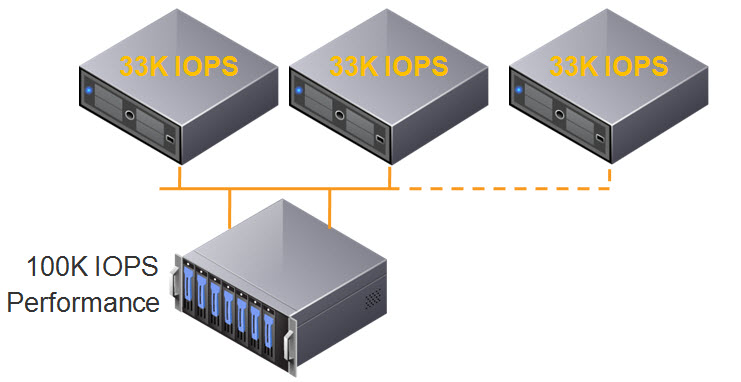
The 100K IOPS is now divided by 3, and each ESXi host now has 33K IOPS.
This isn’t really what customers expect when they add additional servers to an environment, but in reality, the storage performance is further divided between ESXi hosts and results in less IOPS per host in the best case scenario. Worst case scenario is the additional workloads on the third host create contention, and each host may have even less IOPS available to it.
But wait, there’s more!
What happens when we add a forth host? We further reduce the storage performance per ESXi host to 25K IOPS as shown below, which is HALF the original performance.
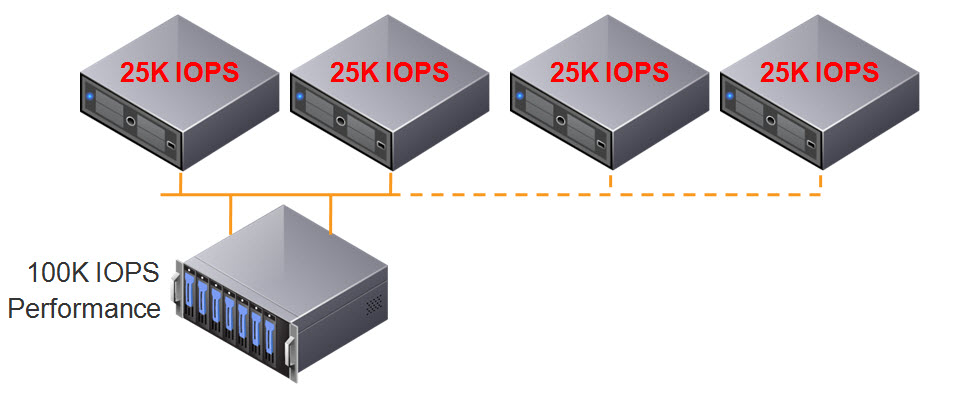
At this stage, the customers performance is generally significantly impacted, and there is no easy or cost effective resolution to the problem.
….. and when we add a fifth host? We continue to reduce the storage performance per ESXi host to 20K IOPS which is less than half its original performance.
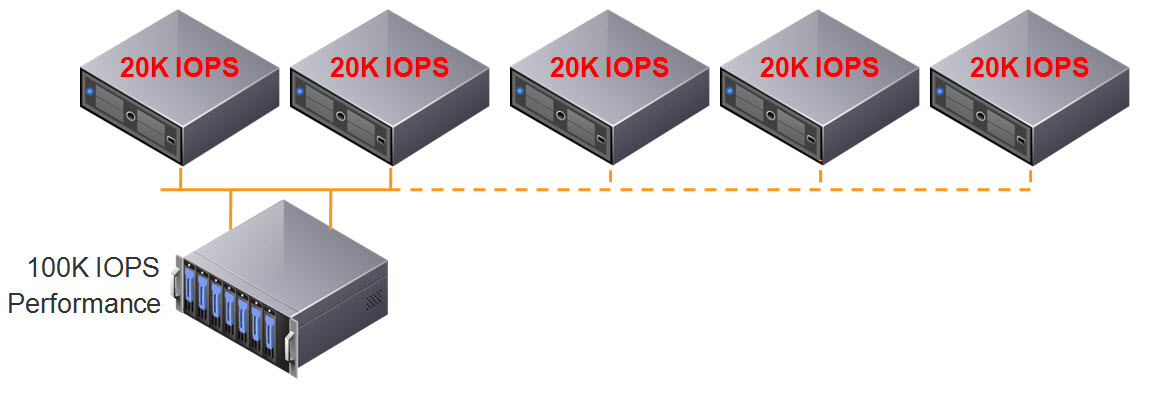
So at this stage, some of you may be thinking, “yeah yeah, but I would also scale my storage by adding disk shelves.”
So lets add a disk shelf and see what happens.
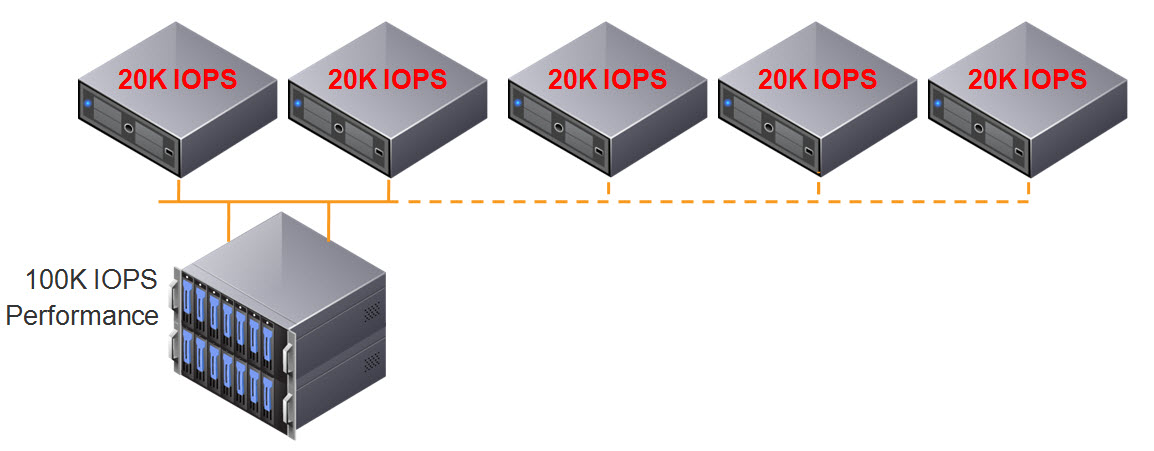
We still only have 100K IOPS capable storage controllers, so we don’t get any additional IOPS to our ESXi hosts, the result of adding the additional disk shelf is REDUCED performance per GB!
Make sure when your looking at implementing, upgrading or replacing your storage solution that it can actually scale both performance (IOPS/throughput) AND capacity in a linear fashion,otherwise your environment will to some extent be impacted by what I have explained above. The only ways to avoid the above is to oversize your storage day 1, but even if you do this, over time your environment will appear to become slower (and your CAPEX will be very high).
Also, consider the scaling increments, as a solutions ability to scale should not require you to replace controllers or disks, or have a maximum number of controllers in the cluster. it also should scale in both small, medium and large increments depending on the requirements of the customer.
This is why I believe scale out shared nothing architecture will be the architecture of the future and it has already been proven by the likes of Google, Facebook and Twitter, and now brought to market by Nutanix.
Traditional storage, no matter how intelligent does not scale linearly or granularly enough. This results in complexity in architecture of storage solutions for environments which grow over time and lead to customers spending more money up front when the investment may not be realised for 2-5 years.
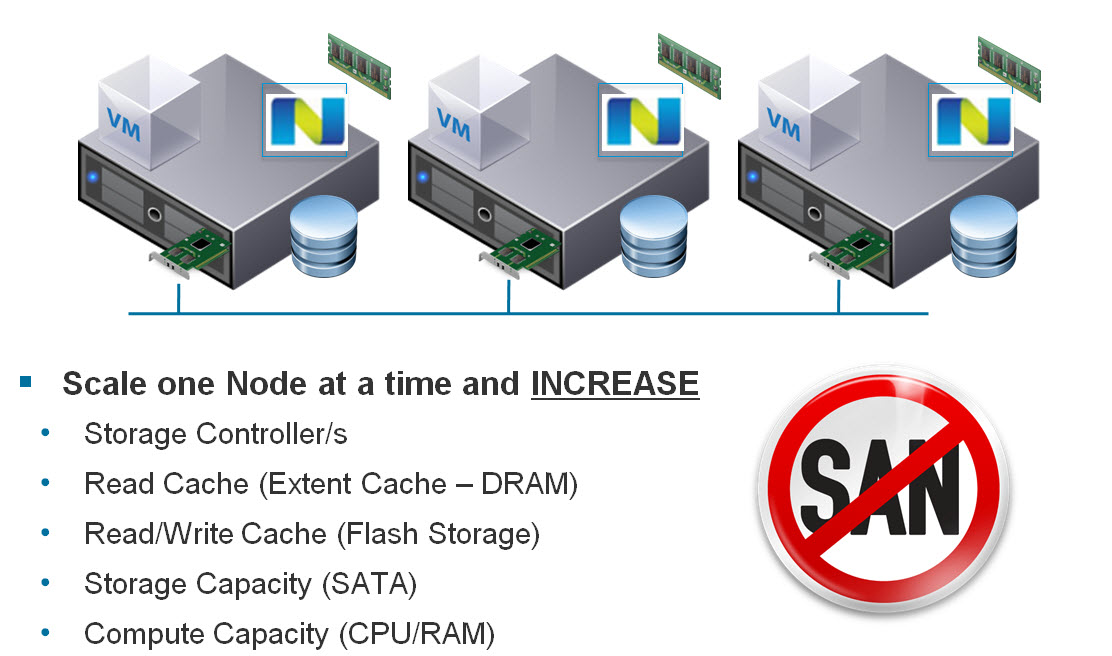
I’d prefer to be able to Start small with as little as 3 nodes, and scale one node at a time (regardless of node model ie: NX1000 , NX3000 , NX6000) to meet my customers requirements and never have to replace hardware just to get more performance or capacity.
Here is a summary of the Nutanix scaling capabilities, where you can scale Compute heavy, storage heavy or a mix of both as required.
While I agree with the general concepts here, isn’t it more likely that a storage array will be IO constrained on the back end, rather than at the controllers? In my experience an array with dual 50k IOP controllers is unlikely to have 100k worth of back end IO on day 1. Granted the closer you get to the controller maximum, the less linear IO will scale.
In my experience, traditional storage runs out of performance way before capacity limits. But your correct that you need a certain amount of back end SSD/disk before the controllers reach their peak performance. Although In recent times, performance is more and more being provided by caching solutions and intelligence in the controllers, more than back end disk. Take most traditional storage solutions, 1 or 2 trays of SSD max out the controller, but equate to a small percentage of the total capacity the controllers support.
I agree scale out scale out shared nothing model is the future for storage solutions. But extracting optimal I/O and delivering it to the end point i.e. the servers is much more involving. There are several stacks
Server –> HBAs (multiple or multi ported), mpio drivers
Storage fabric –> Multiple paths to storage controllers and LUNs
Storage Arrays –> Capacity of front end controllers, Caching strategy, Capacity of back plane to the disks etc
I feel some of the issues can be addressed via mechanims like priority flow controls e.g. what exists on VMWare Storage I/O control, Storage Policies assigned to VMs.
Is it possible to priority assign tags to I/O packets e.g. what happens in networking world 802.1 p COS tags etc, not sure may be some mechanism already exists?
Thanks
I think you have hit the nail on the head, There is a lot involved with Extracting optimal I/O from traditional SAN/NAS!
Hey Josh,
In one sense you make a very valid argument regarding customers possibly not being able to buy for today, and having to build in some kind of headroom/growth – often nominally 3 years. And for sure this is why nutanix/VSAN/islion or any other “non-disruptive”, in terms of scaling, scale-out shared nothing models are the models for the now/future. There’s a lot to like there so there’s no problem there.
I think this performance/capacity balancing act has always been the challenge with SAN design. However I don’t agree with the starting premise in this article that you would architect a solution with absolutely no headroom whatsoever. So that day 1 requirement of 100,000 IOPS is met with a solution that can only scale to 100,000 IOPS. So you have zero headroom for growth or component controller failure. Isn’t that bad design ?, which is what your example illustrates.
I would question whether Nutanix would advise customers to run a single NX1000 to 100% capacity – would it not be more likely to suggest that you run at maximum tilt of 50% or maybe less on all nodes to ensure failover capacity, just like with admission control ?. And then I’m sure when you get to a threshold you introduce another unit ?.
On large Tier 1 SAN systems, where backplane bandwidth can be as high as 64GB/s and where you can also have excess front capacity (IOPS/BW), as Hamish has said it is often backend (typically bandwidth) that suffers when for example a large block workload (64K) like SQL turns from IOPS intensive to bandwidth intensive. However even in those cases you can still architect the backend, assuming there is enough bandwidth, to linearly scale. On a recent project we could scale 1,000 64K IOPS at a time on a HDS VSP by adding 1 parity group for data and one for log (1PG=6+2 R6 SAS). This was tested/benchmarked using SQLIO to ensure we stayed within Microsoft latency targets (20ms for data/tempdb & 3ms for log). It deployed a modified wide striping schema to separate different IO types and while I would agree did require some testing, the whole design goal was linearly scalability. I’m not saying it was cheap (it wasn’t !), but it was eminently simple to manage for such a large system and by god did it perform. It was sized for 3 years growth but based on IOPS (and the scaling factor was parity groups) and as it grew it hit those goals. My point is yeah using the traditional raid group approach is not a runner and I believe a lot of the tiering solutions are just hotfix solutions, but ultimately understanding your workload and data are most important. I think its shows a lot of SAN vendors have trouble knowing how to size these things and don’t advise customers correctly. And if you do understand them, you can realistically size a solution to fit (if you have the budget ;-))
Hi Paul,
Thanks for the detailed comment.
The starting premise for the post may have not been well explained, my example was the environment was not sized to be 100% utilized day one, but simply the capability of the controllers chosen was 100K IOPS (regardless of it was 1% or 100% utilized Day 1).
So day 1 performance was great, as there was minimal chance of a bottleneck and 100K IOPS shared between two hosts.
The point I was trying to get across was regardless of the sizing of the Controllers being right or wrong, its still limited to 100K IOPS for the life of the solution, and as the environment grows, performance wont increase, it will just be shared between more and more hosts.
My recommendation for a customer using traditional shared storage, was and would still be today to size with a significant amount of future proofing involved, typically between 1-5 years.
With Nutanix, I advise customers to buy exactly what they need today (with N+1) and scale incrementally one node at a time as this is a very low cost, and the CAPEX/OPEX and TCO can be reduced significantly using this model without impacting performance/availability etc due to the shared nothing scale out architecture.
So if a customer has a “X” node Nutanix cluster and they are approaching 100% utilization (or whatever threshold they decide) they can order one or more nodes, and continue to scale the environment in a “just in time” fashion. It also lowers the risk of sizing mistakes, as the cluster can be expanded in very small and cost effective increments.
Its a significant change to architectural thinking compared to traditional storage, but I believe its a Win/Win for the customers and delivers a better technical solution.
In your example, if I had a customer who I knew would scale to many PBs of storage and hundreds of hosts, but only needed 50Ghz and 256GB Ram today, I would have no problem with them starting with a 3 node NX1000, as Nutanix nodes can be mixed and you never need to throw out a Nutanix node, you can just keep expanding the cluster.
It sounds like you have done some very good architecture to work around some scaling constraints of traditional storage, but I think you conceded it was expensive and may also concede it was not easy to architect, even if the end result scales easily. This is where I am very impressed with Nutanix, architecture is very easy both for capacity and performance.
Hope that makes sense.
Hey Josh,
Hope you’re well..
Thanks for your detailed reply. Don’t get me wrong – I have advised some clients to check out the hyper converged story including yourselves already. I do think hyper converged is a better approach than VCE/flexpod etc. That’s a personal view but mainly because those things are quite complex to manage and have similar scaling issues. My main point really does not diverge from anything you say and that is to know your workload and perform a proper design, and proof of concept. Otherwise it’s guess work..
Later,
Paul
This is a noob questions, but why isn’t the IOPS increased by adding another disk shelf.
“We still only have 100K IOPS capable storage controllers, so we don’t get any additional IOPS to our ESXi hosts, the result of adding the additional disk shelf is REDUCED performance per GB!”
Adding drives to an existing SAN/NAS controller only increases performance if the bottleneck is not the controllers themselves. No matter how many drives a SAN/NAS has, performance is always dependant on the controllers.
So if the controllers are the bottleneck, IOPS/GB will reduce when adding drives, if the controllers are not the bottleneck, adding drives may increase performance assuming there are no other bottlenecks like the connectivity to the storage.
Pingback: Software-Defined Storage – Converged Infrastructure | Cloud Solutions Architect
Pingback: Converged Infrastructure | Cloud Solutions Architect
Pingback: The 10 reasons why Moore’s Law is accelerating hyper-convergence |