Recently DeepStorage.net published a paper “Evaluating Data Locality” which was commissioned by VMware who have been critical of Nutanix ever since releasing VSAN.
The technology report preface includes strong language (below) broadly painting (data) locality as complicated and antithetical to modern storage. It is reasonable to expect that the report supports these claims with details of specific data locality implementations (such as those by Nutanix), but not a single real-life scenario is referenced. The author’s only responses to my enquiries for the testing methodologies utilized was a tweet advising that the claim is only theoretical.

The report is clearly just an opinion piece without factual (at least not tested/validated) basis. Rather than reflect a rigorous examination of pros and cons of data locality, it appears the report may instead reflect a intention by sponsor VMware to create Fear, Uncertainty and Doubt (a.k.a FUD) around the Data Locality capability that its own product lacks. The document certainly does not highlight any advantages of VMware’s own product.The beauty of this kind of 3rd party commissioned report is it provides Nutanix with an opportunity to highlight the advantages of our platform’s capabilities – which I will be doing in this (very) long post.
Nutanix implementation of Data locality is unique and, in my opinion, a significant advantage which explains why competitors lacking the same capabilities focus so much time/attention on trying to discredit it. In fact, I would go so far as to say the term “Data locality” is synonymous with Nutanix, at least in the context of hyper-converged infrastructure (HCI).
I contacted the author of the paper (Howard Marks) who stated:
“Of course not everything there was re: Nutanix implementation,” but the report is very similar to much of the competitive FUD that VMware uses in the field against Nutanix. This leads me to conclude Nutanix, especially being the market leader, is a significant if not the primary focus for the commissioning of this paper. While plenty of information is publicly available regarding Nutanix Data Locality such as the Nutanix bible and various blog articles such as “Data Locality & Why is important for vSphere DRS clusters” which date back to 2013, it’s common for competitors and analysts to get even the 101 level basics incorrect when it comes to the Nutanix implementation.
The report starts by talking about What (DeepStorage.net) mean by data locality. It stays very much at the 101 level, talking about reading data from a local device and avoiding network hops, which is only a small part of the advantage that Nutanix data locality provides.

A few key points:
- Nutanix does not preferentially store a full copy of the data for each virtual machine on the local storage on the host where it runs.
Nutanix always writes new I/O to the local node, and replicas are distributed throughout the cluster. When a VM moves to another host, new data is again written locally and replicas distributed throughout the cluster.
This means for WRITE I/O, Nutanix Data Locality ensures consistent performance regardless of how many times and VM is moved around a cluster.
Data which is read cold is NOT localised!
For data which is read hot: If the read occurs remotely that 1MB extent is localised and one of the redundant replicas marked for deletion. This ensures subsequent reads for the read hot data are local and ensures there is only one penalty of traversing the network and requesting data from a remote node, however, large or small than penalty may be. Avoiding the penalty, put simply, is not a bad thing as even a 1% efficiency improvement adds up over time.
Virtual Disks (e.g.: VMDK, VHDX or VDISKS) are NEVER moved in their entirety from one node to another following a VM migration. This limitation applies not to Nutanix, but to VMware’s own VSAN where objects (up to 255Gb) need to be moved. Nutanix moves data at the much more granular scale of 1MB regardless of the size of the virtual disk.
Nutanix also does not, and has never done, STRICT LOCALITY as this would be very inefficient and limit the flexibility of a distributed platform. VMware VSAN, on the other hand, has a much more restrictive technique where one node hosts entire objects that almost never move, meaning the bulk of I/O is remote.
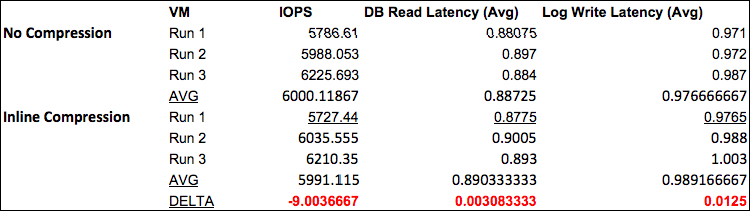
With the release of AOS 4.5 in 2015, Nutanix delivered increased performance (especially from SATA tiers) from the distributed storage fabric by measuring latency for local vs remote and I/O where there is lower remote latency (e.g.: If the local drives are under heavy load) . This scenario is more likely with hybrid platforms.While all flash uptake is steadily rising, this capability makes hybrid a more performant/consistent platform for both new and existing deployments while protecting and maximising the investments already made by Nutanix customer base.
- VMs can migrate to any host in a Nutanix cluster, even where ZERO of the VMs’ data exists.
Nutanix data locality puts ZERO restrictions on where VMs can move within a cluster. VM’s can migrate to a host even if it has no local data. As mentioned earlier, Nutanix always writes new I/O to the local node which means subsequent reads (which are common for new data) are serviced locally. The system localizes remote reads only when they occur (at a 1MB granularity).
This DeepStorage.net criticism of data locality is not at all applicable to Nutanix’s data locality implementation. The report highlights some weaknesses of vendors who have quite frankly just adopted the data locality terminology without the underlying architecture of the leading Enterprise Cloud platform from Nutanix.
Let’s look at the next section, “Data locality’s promoted advantages”.

A few key points:
- Nutanix does not claim data locality is the only way to deliver the performance modern datacenters demand.
Nutanix Acropolis distributed storage fabric (ADSF) understands where reads and writes are occurring and how to most intelligently place data and when locality will benefit and when a workload demands more I/O than a single node can provide.
Nutanix released Acropolis Block Services (ABS) in 2016 which allows virtual or physical workloads to enjoy scale out performance using all nodes in a Nutanix cluster. In the case of a physical server, no data locality is available, but if the workload is a VM, some data locality is possible which takes some overhead off the network to maximise the available bandwidth for remote I/O to occur with minimal contention.
The below tweet shows a physical server connected to a 4 node cluster using 4 active paths, then the same physical server expanding automatically to 8 paths when the cluster was expanded to 8 nodes.
How many #Nutanix CVMs service a single bare metal workload when using Acropolis Block Services?#HCI #FightTheFUD pic.twitter.com/yLUrSIaRYG
— Josh Odgers (@josh_odgers) August 7, 2016
ABS can be used with VMs running on Nutanix as well where the I/O requirements are so high that a single controller becomes a bottleneck. These use cases are extremely rare these days, but Nutanix has a (very) good solution for these scenarios while allowing all other VMs to benefit from data locality as ABS is used on a per server (VM or physical) basis.
This is a very good example of Nutanix having multiple solutions for different workloads and use cases as well as being the first to market with these capabilities.
- As I mentioned earlier, Nutanix always writes new I/O to the local node, and replicas are distributed throughout the cluster.
Why am I bringing this up for the third (!!) time? This is such a key point because writing locally ensures “a significant fraction of write I/ Os will also go to the local media.” as per the DeepStorage.net report.
This fraction is 50% for Resiliency Factor 2 (RF2) and 33% for Resiliency Factor 3 (RF3).
This means for RF2 results in a 50% less chance of the network or a remote node being a bottleneck to the I/O being written and acknowledged and, of course, 33% for RF3. It also means less unnecessary network utilization and potential contention.
The next section (rightly) talks about “Reduced network traffic”.

A few key points on reduced network traffic.
- The report confirms that reduced network traffic is an indisputable advantage
The report and Nutanix agree, reduced network traffic is a good thing. But what advantages does reducing network utilization provide with these super fast 10/25/40 and even 100Gb networks?
A few examples come to mind when hearing critics talk about data locality. For example, critics also claim that the network is not a bottleneck for storage and latencies are very low these days. Even if this were 100% true, it doesn’t take into account the networking requirements of the virtual machine and the applications. If an app is driving any reasonable level of I/O it’s typically because users are accessing the service being provided by that/those VMs.
So the less I/O (unnecessarily) used for remote storage I/O, the MORE available bandwidth and the LOWER contention there is for actual virtual machine/user traffic. Keep in mind contention can occur without network links being 100% utilised.
A second example is when remote I/O occurs it means that two nodes are involved in the I/O path, as opposed to one. The CPU for Node 1 is in a wait state while waiting for Node 2 to respond. This is a simple example of remote I/O (or a lack of data locality) having higher overheads from a (In-kernel or VM based) storage controller CPU perspective.
The final example is an economic one. If a customer uses a solution like Nutanix then the requirement to upgrade from 10Gb networking to 25/40/100Gb networking is significantly reduced. In the past, it was common that I would design virtualisation solutions using SAN/NAS which required 4 x 10GB NICs (2 for VM traffic and 2 for IP Storage traffic), or 2 x 10GB for VM traffic and 2 x 8GB FC HBAs for storage traffic.
Since joining Nutanix in 2013, I have seen only a handful of customers who required more than 2 x 10Gb for VM and storage traffic, and this has been in large part due to data locality. For context, I have focused on business critical applications the entire 4+ years I’ve been with Nutanix so the workloads customers are running are the same, or in many cases larger, than the ones which have required 4 x 10Gb NICs in the past.
The next section covers DeepStorage.net thoughts on “The downside to data locality”.

A few key points on the downside to data locality.
- Deepstorage.net is not talking about Nutanix Data Locality
As I mentioned at the start of this article, by DeepStorage.net definition, it is not talking about Nutanix unique implementation of data locality. It is referring to other products in the HCI market trying to emulate Nutanix.
- I agree with the article that other vendors’ object based implementations are inefficient.
In short, the other vendors claiming to have data locality don’t really have data locality per se. Their use of data locality refers to limitations of fairly rudimentary file systems / object stores. This strategy is doubtlessly designed to try and elevate their products into conversations where Nutanix is widely considered the market leader due to many unique capabilities like Data Locality implementation.
The next section is “I/O concentration”.

A few key points on I/O concentration.
- Again, Deepstorage.net is not talking about Nutanix Data Locality
Nutanix distributed storage fabric does not use flash devices as “cache” per se like VSAN,
- I agree with the article that distributing data across nodes reduces the potential for I/O hotspots.
This is, in fact, exactly what Nutanix does in real time, based on fitness values (patent pending) which takes into account capacity utilization and performance of each individual node and drive. So Nutanix keeps Write I/O local, and proactively (in the write path) ensures that replicas are placed in the optimal place to minimise potential hotspots. This also ensures subsequent reads can be done locally in the vast majority of cases.
The next section covers “Constraints on VM placement / movement & load balancing”.

A few key points on I/O concentration.
- None of the constraints highlighted are applicable to Nutanix.Nutanix does, however, have another unique capability which ensures data locality maximization without any overheads so onto point 2 🙂
- Nutanix Acropolis Hypervisor (AHV) automatically places VMs powering on or recovering from a HA event onto the node with the most local data.
This is what we refer to as “restoring locality” which is done in the most lightweight way possible by moving the VM and not the data!
This capability is not new; it’s been built into AHV since day 1 and the below tweet shows what it looks like from the Nutanix PRISM UI.
What is "Host VM restore locality"?
It's #Nutanix #AHV vMotioning a VM to the node with the most local data.
Data Locality for the win!#HCI pic.twitter.com/o7uhVpl9K1— Josh Odgers (@josh_odgers) March 31, 2017
This function minimizes the chance of data needing to be “localised”.
- What the article refers to is an HCI product which is similar to HA pairs where VMs can only run on two nodes where the data is located, which is why DRS being disabled or Manual is recommended.
In reality, this isn’t data locality, it’s just a basic product which has very limited scalability. One of the many issues with this type of product is that a single node failure creates a significant risk and cannot be recovered without hardware replacement.
Nutanix, on the other hand, can restore the resiliency and even tolerate subsequent failures without failed hardware (such as SSD/HDD or even entire nodes) being replaced.
I recently wrote a series of posts after HPE decided to start a campaign of FUD against Nutanix with #HPEDare2Compare. One article in the series specifically covers the resiliency of the Nutanix platform in depth so I encourage you to take a look at that post and the rest of the series.
The next section covers “Data Locality limits VM Migration”.

A few key points on Data Locality limiting VM Migration.
- As previously mentioned, VM’s can migrate to ANY node in a Nutanix cluster, without restriction AND without bulk data movement.
To recap, For data which is never accessed, it is NEVER moved! Only data which is read/overwrite hot is localised and is done so at a 1MB granularity.
Virtual Disks (e.g.: VMDK, VHDX or VDISKS) are NEVER moved in their entirety from one node to another following a VM migration.
Now if you believe the network is not a bottleneck, then this granular localisation is not a problem. But think about it this way; The network is used the same amount of time if a remote read is localised or not, so what’s the problem with localising? The problem is actually not localising the data as subsequent reads hit the network unnecessarily adding some overhead, even if it’s minimal.
- If data locality results in data being spread over multiple nodes, how is this worse than a platform without data locality that allows vDisks to “spill” over to other nodes?
The simple answer is “spilling” over between nodes (i.e.: What VSAN does) is at best a band-aid to try and address the fact that VSAN is not a distributed file system. ADSF, on the other hand, is a distributed storage fabric and distributes replicas across the entire cluster by design. This is also done in real time based on the fitness values (patent pending) which takes into account capacity utilization and performance of each individual node and drive.
- New micro-services don’t know the underlying storage, and cannot migrate VMs or containers to where the data is located.
Well, lucky Nutanix has a solution for that. The next generation hypervisor (AHV) places VMs automatically on the node with the most local data.
- On Nutanix, Data Locality is never random. Because ALL write I/O goes to the node running the VM or container.
So for the emerging market of microservices/containers, etc, Nutanix ADSF is the perfect platform as any new data is written locally (optimally) no matter where the instance starts up in the cluster. If that workload only runs for a short time, or moves between hosts several times, it gets the maximum data locality with no additional overhead as locality for new data is achieved in the write path and on by default.
- Static VMs do not require enough capacity on the local node on Nutanix
Back in 2015 this was a perceived problem, but it has in reality never been a problem thanks to ADSF being a truly distributed storage fabric. I wrote the article “What if my VMs storage exceeds the capacity of a Nutanix node?” which covers off this point in detail for those of you who are interested. In short, this is not a problem at all for Nutanix.
For example, in a 100 node cluster one VM running on Node 1 can use all the capacity of the 100 node cluster and this is automatically balanced in real time as discussed earlier by the fitness values (patent pending). This balancing avoids a situation where virtual disks are “spilled” onto new nodes/drives because the distribution of replicas is done at the time of writing the IO.
The next section covers “Data Locality and metadata clones”.

One key point on Data Locality and Metadata clones.
- Nutanix allows the customer making the metadata clones to chose between maximum performance or maximum capacity savings.
Nutanix shadow clones, which are typically used for VDI golden images as the article mentioned, can also provide maximum data locality and therefore performance for metadata clones when they, for whatever reason, have spread across a large number of nodes (which I don’t see typically, but i’ll address the scenario all the same).
If customers want/need maximum performance, Shadow Clones provide the solution. If the environment warrants maximum capacity savings, then Nutanix can simply cache read hot data in the content cache on the nodes running the MySQL VMs which also provides a reasonable level of data locality without the capacity overheads of making an entire copy, in this scenario, five times.
I can’t stress enough, remote read I/O is not a problem for Nutanix, it’s just not as optimal as local I/O.
This tweet says it all, and is a phase I coined back at VMworld 2013 which I tweeted out today.
With #Nutanix Data Locality the WORST case scenario for Read I/O is non-local reads. For an AFA/SAN/NAS this is the BEST case scenario!#HCI
— Josh Odgers (@josh_odgers) July 24, 2017
Network utilization or remote I/O on Nutanix, will be in the worst, and most unlikely, case equal to VSAN, but because data locality writes new data locality, all write I/O will be local, making it more efficient than VSAN and other HCI products.
The next section covers “Deduplication”.

A few key points on Data Locality and Dedupliciation.
- Deduplication is the most overrated storage feature!
Deduplication does not, despite popular belief, solve world hunger or typically reduce your real datacenter storage requirements by 10x or even 5x regardless of vendor. I discuss this importaint topic in The truth about Storage Data efficiency ratios and Dare2Compare Part 1 : HPE/Simplivity’s 10:1 data reduction HyperGuarantee Explained.
For VDI, metadata clones save SO much capacity that even if you keep an entire copy of the dataset on EVERY NODE, you still need a minimal amount of flash per node. e.g.: If you use Shadow clones with even 400GB per node of cloned data (unlikely but let just use this for an example), even a single 800GB SSD which are very affordable these days would have you well covered.
So I’m moving on from VDI as it’s all but a non issue in the real world.
Moving onto server workloads, firstly many datasets do not achieve significant deduplication ratios and other datasets such as database workloads suffer significant performance implications of being deduped due to the fact sequential I/O streams frequently having to be served as random due to deduplication.
In my experience, customers running mission critical workloads such as SQL, SAP and Oracle do not want deduplication, and therefore opt to turn it off or just avoid platforms not allowing dedupe to be turned off (yes platforms like this exist even in 2017!!).
But I have to concede, deduplication on a distributed file system such as ADSF which does global dedupe and especially on platforms like VSAN which do dedupe on a per disk group basis (which can be a smaller dedupe domain than a node), are not as capacity efficient as a centralised SAN. But the pros of Nutanix and ADSF far outweigh the minimal difference in deduplication efficiency which is insignificant in the real world.
- Nutanix does not “need” a local copy and can/does access remote replicas
In short, Nutanix can work with no data locality or 100% data locality. The more locality the better, but in the WORST case, Nutanix has the same network overheads/latency as a SAN does in the BEST case. I cover of this in my younger/fatter days in this VMworldTV interview from 2013 (From 2:44 onward).
The next section covers “Erasure Coding”.

One key point on Data Locality and Erasure Coding.
- It’s not a conflict, it’s a choice between capacity efficiency and performance.
Erasure coding (EC-X) has been a capability of ADSF since 2015 and its uptake has been steadily growing over the past two years. The best thing about Nutanix data reduction capabilities is the ability to turn on/off features per vDisk. Even within a single VM, multiple different data reduction features and combinations can be used to maximise performance and data reduction/efficiency.
In general, the primary use cases for Erasure coding which I detailed in “What’s .NEXT 2015 – Erasure Coding” is write cold data, such as
- File Servers
- Backup
- Archive
- Logging
- Video
- Audio
Data Locality is designed to reduce overheads and optimise performance. Erasure Coding still writes locally and if/when data meets the criteria for striping (meaning the data is write cold for 7 days), then the Erasure Coding will take effect as a low priority background task.
Customers get all the performance of RF2/RF3 along with data locality. Erasure coding is striped only when the data qualifies as write cold. Once striped, there is reduced level of data locality due to the striping of data across nodes, however, by the time data is striped, it is unlikely that maximum performance will be a realistic concern or even noticible.
With that said, in the WORST case, Nutanix has the same network overheads/latency as VSAN or a traditional SAN does in the BEST case.
It should be clear by this stage that the data locality report tries to find every possible corner case to make data locality sound like a bad thing. Although many points are valid for other platforms lacking the unique data locality capabilities that Nutanix customers enjoy, not a single point has any merit in regard to real-world Nutanix scenarios.
Next up we talk “Data Locality and offline resources”.

A few key points on Data Locality and Offline Resources.
- As data locality is not central to Nutanix performance, if VMs do not for any reason have a high percentage of data locality, we’re not worse off than VSAN, and we’re better off than a SAN in any case.
Nutanix performance is excellent without locality; data locality just makes things better and does so with minimal overhead. In other words, the pros far outweigh the cons.
In the failure scenario the article described, Nutanix will still benefit from a more optimal write path as one replica is always written locally even directly after a HA event. Nutanix’s ability to rebuild data is, as the report states, a many-to-many architecture.
For example, if a VSAN node fails, the second copy of an object is solely read from ONE node and written to another ONE node. Should a single Nutanix node fail, EVERY NODE in the cluster participates in the rebuild making the recovery time faster. And the rebuild has a low impact due to the “many hands make light work” approach.
Importantly, data does not have to be recovered to any specific location/node, so ADSF uses the fitness values discussed earlier to place data intelligently for both performance and capacity to ensure an optimal storage fabric.
And FINALLY, the conclusions!

Some final thoughts:
- The closer we look at data locality the less attractive it looks?
When talking about other platforms, I would agree because they don’t truly have data locality. The points raised in this post clearly show the report is almost entirely not applicable to Nutanix, with the exception of the insignificant (in the real world) efficiency reductions when using Deduplication and Erasure Coding with distributed platforms (which is much more applicable to VMware VSAN than Nutanix as previously mentioned).
The part which I find the most amusing is that while VMware commissioned the article, the only valid (yet insignificant) points around data reduction which have some impact on Nutanix, have higher impacts on VSAN which has a much less efficient (per disk group as opposed to global) deduplication.
- “We [DeepStorage.net] believe that users would be better served by the consistent performance of an all-flash system rather than gaming the performance of a hybrid system with data locality.”
Comparing all flash to hybrid is apples and oranges, but the point about consistent performance is reasonable. Data locality (as explained earlier) ensures the write path remains consistent even after a VM migrates as one replica is always written locally and the other replica/s distributed across the cluster. So for consistency, especially for write performance (which is much more intensive than read), data locality is the way to go!
Related Articles: