Problem Statement
What are the most suitable HA / host isolation response when using Nutanix?
Assumptions
1. vSphere 5.0 or greater
2. Two x 10GB Network interfaces are shared for Nutanix Storage Traffic and Virtual Machine Traffic
Motivation
1. Minimize the chance of a false positive isolation response
2. Ensure in the event the storage is unavailable that virtual machines are promptly shutdown to enable HA to recover the VMs in a timely manner (where other hosts are unaffected by isolation) and to prevent a “split brain” scenario
3. Ensure maximum availability
Architectural Decision
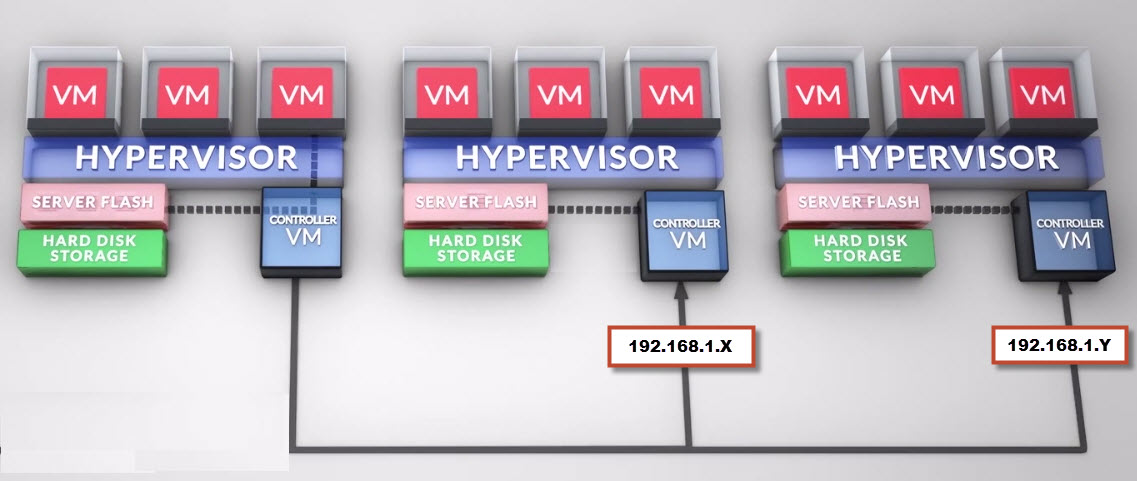
Turn off the default isolation address and configure the below specified isolation addresses, which check connectivity to multiple Nutanix Controller VMs (CVMs) on the IP Storage VLAN.
Configure the following Isolation addresses
das.isolationaddress1 : NDFS Cluster IP Address
Configure Host Isolation Response to: Power Off
For Nutanix Controller VMs override the cluster setting and configure Host Isolation Response to “Leave Powered On”
Justification
1. The ESXi Management traffic along with the Virtual machine traffic and inter-Nutanix node storage traffic is running over 2 x 10GB connections. Using the ESXi management gateway (default isolation address) to check for isolation is not suitable as the management network can be offline without impacting the IP storage or data networks. This situation could lead to false positives isolation responses.
2. The isolation addresses chosen tests IP storage connectivity over the converged 10Gb network and in the event this is unavailable, there is no point testing further connectivity as Virtual machines cannot function without their storage
3. In the event the Nutanix cluster IP address cannot be reached by ICMP the Node will not be able to properly function. As such, triggering isolation response and powering off the VMs based on this criteria is logical as the VMs will not be able to function under these conditions.
4. In the event the NDFS Cluster IP address does not respond to ICMP on the Management interfaces it is likely there has been an isolation event OR a catastrophic failure in the environment, either to the network, or the storage controllers themselves, in which case the safest option is to Power Off the VMs.
5. In the event the isolation response is triggered and the isolation does not impact all hosts within the cluster, the VMs can be restarted by HA onto a surviving host and resume functioning
6. Using the Nutanix Controller VM (CVM) IP address (192.168.5.2) for the Isolation address is not suitable as this address exists on each ESXi hosts and as such it is not a good candidate for isolation detection as the host will always be able to find this address even when the network is offline due to the CVM being local to the host
7. The Nutanix Controller VM accesses local storage and can continue to run locally even in an isolation event. When the isolated event is over, the CVM will then regain connectivity to the other CVMs in the Nutanix cluster.
8. Shutting down the CVM would only increase the recovery time once the isolation even is over and has no added benefits.
Implications
1. In the event the host cannot reach any of the isolation addresses, virtual machines will be powered off.
2. Initial cluster setup would require the vSphere administrator to override the Cluster settings for each Controller VM. Note: This is a one time task (Set & Forget)
Alternatives
1. Set Host isolation response to “Leave Powered On”
2. Do not use Datastore heartbeating
3. Use the default isolation address
4. Leave the CVM on the default cluster setting and “Shutdown” on isolation
Related Articles
1. VMware Host Isolation Response in a Nutanix Environment #NoSAN
2. Storage DRS and Nutanix – To use, or not to use, that is the question?