While its not news that Nutanix Distributed Storage Fabric (NDSF) supports numerous data avoidance & reduction technologies, what is less well known is how these technologies can be enabled/disabled and used.
Before we begin, let me cover off what technologies NDSF offers:
Data Avoidance:
- VAAI-NAS Fast File Clone (for ESXi)
- View Composer for Array Integration (VCAI) for Horizon View
- Native NDSF Clones (ESXi, Hyper-V and AHV)
- ODX Copy Offload (Hyper-V)
- Crash and Application Consistent snapshots (ESXi, Hyper-V and AHV)
Data Reduction:
- Compression (In-Line and Post-Process)
- Deduplication (Fingerprint on Write/In-Line for Performance Tier and/or Capacity Tier)
- Erasure Coding (EC-X)
Data avoidance is designed to prevent the creation of unnecessary data which removes the requirement to leverage data reduction technologies. This means less work for the storage layer which results in more available front end IO to service the virtual machines.
An example of data avoidance is using VCAI with Horizon View to create Linked Clones near instantly which not only reduces space but ensures faster deployment and recompose activities with greatly reduced impact to the environment.
Data avoidance is greatly underrated in my opinion, as it results in lower compression/deduplication ratios, because there is no additional data to dedupe or compress. If Nutanix turned off these data avoidance technologies, it would result in HIGHER compression and dedupe ratios, which sounds great on a marketing slide or in a tweet, but in reality, avoiding work for the storage is a much better way to do things.
Some vendors report data avoidance such as snapshots in deduplication ratios, and this in my opinion is very misleading and designed to artifically inflate dedupe ratios for competitive purposes. For more information see: Deduplication ratios – What should be included in the reported ratio?
Data Reduction is still a valuable option to have but in my opinion its overrated. The reason I think its overrated is data reduction does not always work well. It greatly depends on your data type if you will see a good data reduction ratio or not, AND if the overheads (of which there is always an overhead) are worth it.
Let’s now focus on the NDSF implementation of Data Reduction technologies.
Compression:
Compression can be configured on new or existing containers and be set to In-Line or Post-Process. For post process, enter a “Delay” value e.g.: 60 to delay compression for 1 Hour, or 3600 for 1 day.
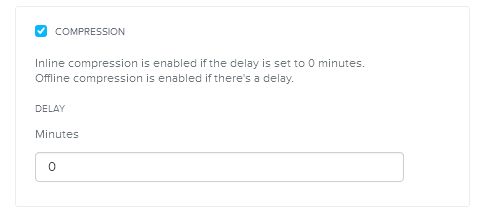
Compression can be reconfigured at any time, without the requirement to relocate VMs or reformat the storage. For data which is already compressed it will be uncompressed as part of a low priority background task (known as Curator). This ensures there is low/no impact of changing Compression settings, ensuring maximum flexibility for customers.
Because compression is configured per container, you can have VMs or even Virtual Disks running compression alongside VMs or Virtual Disks not running compression within the same NDSF cluster. This helps eliminate silos and ensures mixed workloads with different data types/profiles can co-exist efficiently.
Deduplication:
As with Compression, Deduplication can be configured on new or existing containers and be set to dedupe for the performance tier (SSD) and optionally for the Capacity (HDD) Tier. This means data reduction can be maximised for either or both tiers depending on customer requirements.

Again the same as Compression, Dedupe can be reconfigured at any time, without the requirement to relocate VMs or reformat the storage. For data which is already deduped the same low priority background task (Curator) rehydrates the data again ensuring there is low/no impact of changing dedupe settings and ensuring maximum flexibility for customers.
Because dedupe is configured per container, you can have VMs or even Virtual Disks running dedupe alongside VMs or Virtual Disks not running dedupe within the same NDSF cluster. Deduplication is also complimentary to Compression, meaning both can be ran at the same time to maximise data reduction and further eliminate silos ensuring mixed workloads can co-exist efficiently.
Erasure Coding (EC-X):
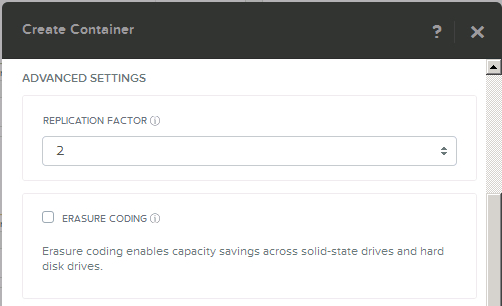
As with Compression & Dedupe, EC-X is enabled on a per container basis and is complimentary to both Compression and Dedupe. EC-X is a post-process only form of data reduction designed to work on Write cold data (meaning data which is not changing).
EC-X applies to data across the Performance Tier (SSD) and the Capacity Tier (SATA) which means the effective SSD capacity is increased, which means more data can be serviced by SSD, thus increasing performance.
As previously discussed, NDSF supports different containers using different combinations of data reduction all within the same NDSF cluster to maximise efficiencies and eliminate unnecessary silos.
Summary:
Nutanix provides multiple technologies to minimise the data being stored on the distributed storage fabric while giving customers the flexibility to enable/disable and tune data reduction settings to suit different data profiles all within the same NDSF cluster.
Remember, “one size does not fit all” so it is importaint for the storage layer to be able treat your workloads differently based on their individual requirements.
Related Articles:
- NOS 4.5 Delivers Increased effective SSD tier capacity
- Nutanix – Improving Resiliency of Large Clusters with Erasure Coding (EC-X)
- Nutanix – Erasure Coding (EC-X) Deep Dive
- Deduplication and MS Exchange
- What I/O will Nutanix Erasure coding (EC-X) take effect on?
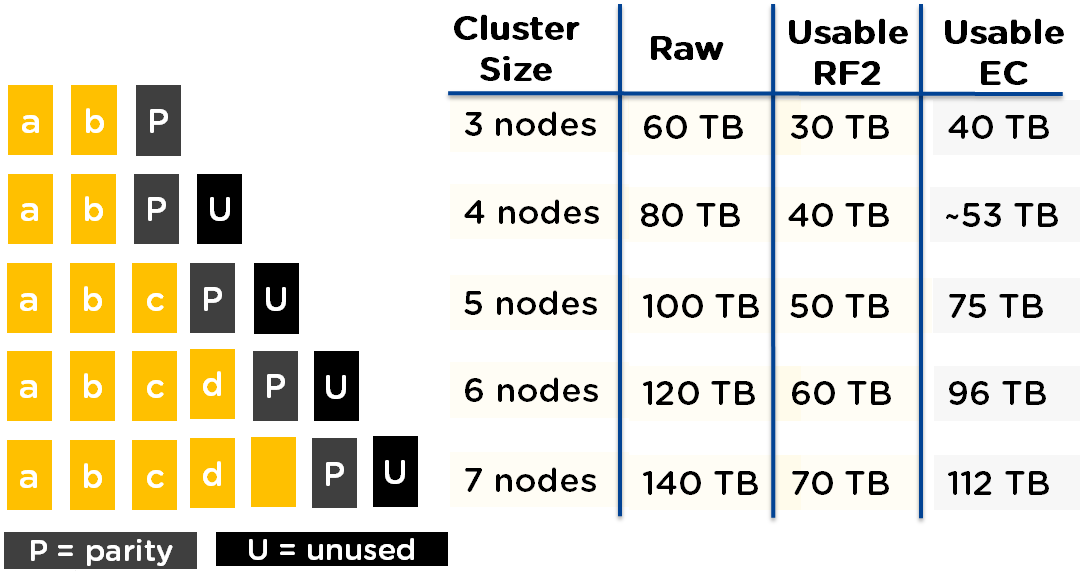
- RF2 & RF3 Usable Capacity with Erasure Coding (EC-X)
- Sizing assumptions for solutions with Erasure Coding (EC-X)
- Deduplication ratios – What should be included in the reported ratio?