If you haven’t already review Parts 1 through 4, please do so as they cover critical resiliency factors around speed of recovery from failures, increasing resiliency on the fly by converting from RF2 to RF3 as well as using Erasure Coding (EC-X) to save capacity while providing the same resiliency level.
Parts 5 and 6 covered how Read and Write I/O function during CVM maintenance or failure and in this Part 7 of the series, we look at what impact hypervisor (ESXi, Hyper-V, XenServer and AHV) upgrades have on Read and Write I/O.
This post will refer to Parts 5 and 6 heavily so they are required reading to fully understand this post.
As covered in Part 5 and 6, no matter what the situation with the CVM, read and write I/O continues to be served and data remains in compliance with the configured Resiliency Factor.
In the event of a hypervisor upgrade, Virtual Machine are first migrated off the node and continue normal operations. In the event of a hypervisor failure the Virtual Machine would be restarted by HA and then resume normal operations.
Whether it be a hypervisor (or node) failure or hypervisor upgrade, ultimately both scenarios result in the VM/s running on a new node and the original node (Node 1 in the diagram below) being offline with the data on it’s local drives unavailable for a period of time.
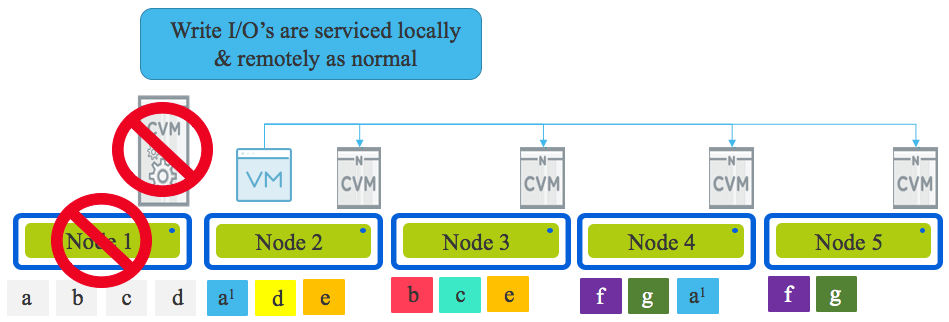
Now how does Read I/O work in this scenario? The same way as was described in Part 5 with reads being serviced remotely OR if the 2nd replica happens to be on the node the Virtual Machine migrated (or was restarted by HA) onto, then the read is serviced locally. If a remote read occurs the 1MB extent is localised to ensure subsequent reads are local.
How about Write I/O? Again as per Part 6, all writes are always in compliance with the configured Resiliency Factor no matter if it’s a hypervisor upgrade OR CVM, Hypervisor, Node, Network, Disk or SSD failure with one replica being written to the local node and the subsequent one or two replica/s distributed throughout the cluster based on the clusters current performance and capacity per node.
It really is that simple, and this level of resiliency is achieved only thanks to the Acropolis Distributed Storage Fabric.
Summary:
- A hypervisor failure never impacts the write path of ADSF
- Data integrity is ALWAYS maintained even in the event of a hypervisor (node) failure
- A hypervisor upgrade is completed without disruption to the read/write path
- Reads continue to be served either locally or remotely regardless of upgrades, maintenance or failure
- During hypervisor failures, Data Locality is maintained with writes always keeping one copy locally where the VM resides for optimal read/write performance during upgrades/failure scenarios.
Index:
Part 1 – Node failure rebuild performance
Part 2 – Converting from RF2 to RF3
Part 3 – Node failure rebuild performance with RF3
Part 4 – Converting RF3 to Erasure Coding (EC-X)
Part 5 – Read I/O during CVM maintenance or failures
Part 6 – Write I/O during CVM maintenance or failures
Part 7 – Read & Write I/O during Hypervisor upgrades
Part 8 – Node failure rebuild performance with RF3 & Erasure Coding (EC-X)
Part 9 – Self healing
Part 10: Nutanix Resiliency – Part 10 – Disk Scrubbing / Checksums