Nutanix “Cloud Clusters” a.k.a “NC2” was designed to enable customers to quickly and easily migrate from on premises environments into public cloud providers such as Amazon EC2 and Microsoft Azure and benefit from these offerings long list of business, architectural and technical advantages.
Two of the advantages which stand out to me are:
- Well understood standard architecture
- Global availability
The well understood architecture of both the Amazon and Azure offerings is incredibly valuable as organisations are largely protected from the underestimated cost & impact of “tribal knowledge” being lost with inevitable employee turnover.
The standard architecture is also highly valuable as both Microsoft and Amazon have extensive training and certification programmes to ensure customers can validate skills of potential employees and enable their existing staff.
The standard architecture also reduces many of the risks & cost of bespoke or custom designed environments where it’s almost impossible for customers (and even many vendors) to match the amount of architectural and engineering rigour as large companies such as Microsoft and Amazon can invest due to their incredible scale.
Now looking at the global availability of resources from both Amazon and Azure, this is extremely attractive as it enables customers to potentially deploy anywhere in the world and in a timely manner and reduce the risk of supply chain issues delaying projects and/or restoring resiliency to production environments after hardware failure/s.
Lets switch gears and look at NC2 and where it fits in.
For a long time now, I’ve be championing Nutanix HCI as the “standard platform for all workloads” as it allows customers to benefit from a well understood architecture which simplifies the traditional datacenter. This reduces the risks & cost of bespoke or custom designed environments and Nutanix training programmes ensure existing and future staff have or can develop the required skills.
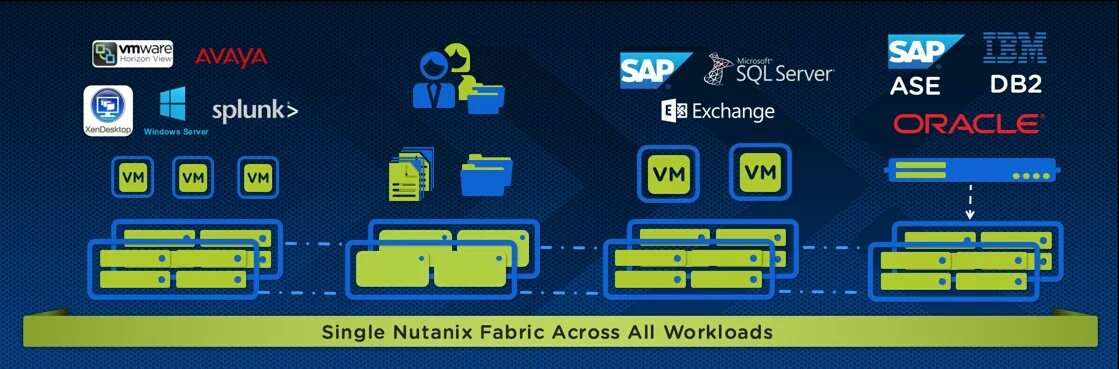
However the problem with any on premises focused product/s are they’re all constrained by commercial challenges such as CAPEX, supply chain as well as organisational challenges such as change requests/approvals/windows and ultimately all of these negatively impact the time to value no matter how simple the deployment it’s once the equipment is delivered.
However with the introduction of NC2, customers benefit from the best of all worlds being Nutanix NC2 as the standard platform for all workloads which can be spanned from new/existing on premises deployments to public clouds providers such as Amazon and Azure.

Leveraging NC2 on Amazon and Azure effectively eliminates the commercial challenges (CAPEX & supply chain) and ensures the fastest possible time to value with new NC2 environments being able to be deployed in under 60 minutes. This partnership also enables customers have a true global reach available at their fingertips.
The ability to scale resources which provide increased performance & capacity to all workloads cluster wide) in minutes is also extremely valuable.
Summary
Nutanix NC2 provides a highly complimentary offering to AWS and Azure which enables customers to enjoy a simple, standard platform for all workloads across private and leveraging multiple public cloud providers and even operate across and migrate/failover between providers.
NC2 can also deliver higher performance, increased resiliency (business continuity) with lower risk, typically a lower total cost of ownership (TCO) while providing a genuine and relatively simple public cloud provider exit strategy.
In Part 2 we will dive into a detailed cost comparison of NC2.