
When discussing resiliency, it is common to make the mistake of only looking at data resiliency and not considering resiliency of the storage controllers and the management components required to service the business applications.
Legacy technologies such as RAID and Hot Spare drives may in some cases provide high resiliency for data, however if they are backed by a dual controller type setups which cannot scale out and self heal, the data may be unavailable or performance/functionality severely degraded following even a single component failure. Infrastructure that is dependant on HW replacement to restore resiliency following a failure is fundamentally flawed as I have discussed in: Hardware support contracts & why 24×7 4 hour onsite should no longer be required.
In addition if the management application layer is not resilient, then data layer high-availability/resiliency may be irrelevant as the business applications may not be functioning properly (i.e.: At normal speeds) or at all.
The Acropolis platform provides high resiliency for both the data and management layers at a configurable N+1 or N+2 level (Resiliency Factor 2 or 3) which can tolerate up to two concurrent node failures without losing access to Management or data. In saying that, with “Block Awareness”, an entire block (up to four nodes) can fail and the cluster still maintains full functionality. This puts the resiliency of data and management components on XCP up to N+4.
In addition, the larger the XCP cluster, the lower the impact of a node/controller/component failure. For a four node environment, N-1 is 25% impact whereas for an 8 node cluster N-1 is just a 12.5% impact. The larger the cluster the lower the impact of a controller/node failure. In contrast a dual controller SAN has a single controller failure, and in many cases the impact is 50% degradation and a subsequent failure would result in an outage. Nutanix XCP environments self heal so that even for an environment only configured for N-1, it is possible following a self heal than subsequent failures can be tolerated without causing high impact or outages.
In the event the Acropolis Master instance fails, full functionality will return to the environment after an election which completes within <30 seconds. This equates to management availability greater than “six nines” (99.9999%). Importantly, AHV has this management resiliency built-in; it requires zero configuration!
For more information see: Acropolis: Scalability
As for data availability, regardless of hypervisor the Nutanix Distributed Storage Fabric (DSF) maintains two or three copies of data/parity and in the event of a SSD/HDD or node failure, the configured RF is restored by all nodes within the cluster.
Data Resiliency
While we have just covered why resiliency of data is not the only important factor, it is still key. After all, if a solution which provides shared storage looses data, its not fit for purpose in any datacenter.
As data resiliency is such a foundation to the Nutanix Distributed Storage Fabric, the Data resiliency status is displayed on the Prism Home Screen. In the below screenshot we can see is that the ability to provide resiliency in both steady state and in the event of a failure (Rebuild Capacity) are both tracked.
In this example, all data in the cluster is compliant with the configured Resiliency Factor (RF2 or 3) and the cluster has at least N+1 available capacity to rebuild after the loss of a node.

To dive deeper into the resiliency status, simply click on the above box and it will expand to show more granular detail of the failures which can be tolerated.
The below screen shot shows things like Metadata, OpLog (Persistent Write Cache) and back end functions such as Zookeeper are also monitored and alerted when required.

In the event either of these is not in a normal or “Green” state, PRISM will alert the administrator. In the event the alert is the cause of a node failure, Prism automatically notifies Nutanix support (via Pulse) and dispatches the required part/s, although typically an XCP cluster will self-heal long before delivery of hardware even in the case of an aggressive Hardware Maintenance SLA such as 4hr Onsite.
This is yet another example of Nutanix not being dependent on Hardware (replacement) for resiliency.
Data Integrity
Acknowledging a Write I/O to a guest operating system should only occur once the data is written to persistent media because until this point, it is possible for data loss to occur even when storage is protected by battery backed cache and uninterruptible power supplies (UPS).
The only advantage to acknowledging writes before this has occurred is performance, but what good is performance when your data lacks integrity or is lost?
Another commonly overlooked requirement of any enterprise grade storage solution is the ability to detect and recover from Silent Data Corruption. Acropolis performs checksums in software for every write AND on every read. Importantly Nutanix is in no way dependent on the underlying hardware or any 3rd party software to maintain data integrity, all check summing and remediation (where required) is handled natively.
Pro tip: If a storage solution does not perform checksums on Write AND Read, DO NOT use it for production data.
In the event of Silent Data Corruption (which can impact any storage device from any vendor), the checksum will fail and the I/O will be serviced from another replica which is stored on a different node (and therefore physical SSD/HDD). If a checksum fails in an environment with Erasure Coding, EC-X recalculates the data the same way as if a HDD/SSD failed and services the I/O.
In the background, the Nutanix Distributed Storage Fabric will discard the corrupted data and restore the configured Resiliency Factor from the good replica or stripe where EC-X is used.
This process is completely transparent to the virtual machine and end user, but is a critical component of the XCP’s resiliency. The underlying Distributed Storage Fabric (DFS) also automatically protects all Acropolis management components, this is an example of one of the many advantages of the Acropolis architecture where all components are built together, not bolted on afterwards.
An Acropolis environment with a container configured with RF3 (Replication Factor 3) provides N+2 management availability. As a result, it would take an extraordinarily unlikely failure of three concurrent node failures before a management outage could potentially occur. Luckily XCP has an answer for this albeit unlikely scenario as well, Block Awareness is a capability where with 3 or more blocks the cluster can tolerate the failure of an entire block (up to 4 nodes) without causing data or management to go offline.
Part of the Acropolis story around resiliency goes back to the lack of complexity. Acropolis enables rolling 1-click upgrades and includes all functionality. There is no single point of failure; in the worst-case scenario if the node with Acropolis master fails, within 30 seconds the Master role will restart on a surviving node and initiate VMs to power on. Again this is in-built functionality, not additional or 3rd party solutions which need to be designed/installed & maintained.
The above points are largely functions of the XCP rather than AHV itself, so I thought I would highlight a AHV’s Load Balancing and failover capabilities.
Unlike traditional 3-tier infrastructure (i.e.: SAN/NAS) Nutanix solutions do not require multi-pathing as all I/O is serviced by the local controller. As a result, there is no multi-pathing policy to choose which removes another layer of complexity and potential point of failure.
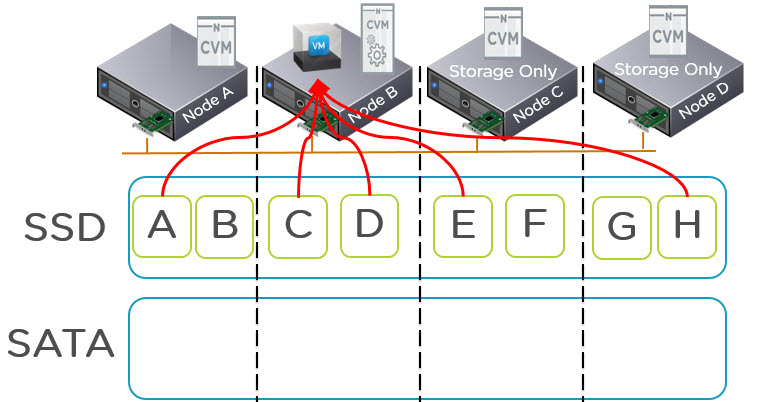
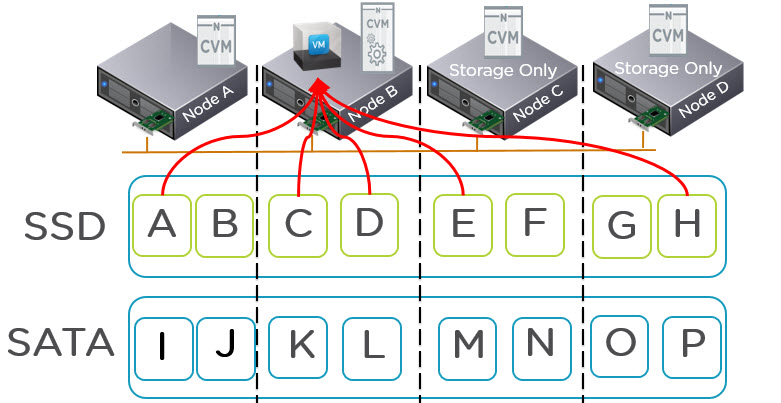
However in the event of the local CVM being unavailable for any reason we need to service I/O for all the VMs on the node in the most efficient manner. AHV does this by redirecting I/O on a per vDisk level to a random remote stargate instance as shown below.

AHV can do this because every vdisk is presented via iSCSI and is its own target/LUN which means it has its own TCP connection. What this means is a business critical application such as MS SQL / Exchange or Oracle with multiple vDisks will be serviced by multiple controllers concurrently.
As a result all VM I/O is load balanced across the entire Acropolis cluster which ensures no single CVM becomes a bottleneck and VMs enjoy excellent performance even in a failure or maintenance scenario.
For more information see: Acropolis Hypervisor (AHV) I/O Failover & Load Balancing
Summary:
- Out of the box self healing capabilities for:
- SSD/HDD/Node failure/s
- Acropolis and PRISM (Management layer)
- In-Built Data Integrity with software based checksums
- Ability to tolerate up to 4 concurrent node failures
- Management availability of >99.9999 (Six “Nines”)
- No dependency on Hardware for data or management resiliency
For more information see: Ensuring Data Integrity with Nutanix – Part 2 – Forced Unit Access (FUA) & Write Through





![[activities]Saurus3_414x2](http://www.joshodgers.com/wp-content/uploads/2015/04/activitiesSaurus3_414x2.jpg)