The I/O path in AHV is unlike other hypervisors and is remarkably simple. Each VM is made up of one or more vDisks, with each vDisk presented directly to the VM via iSCSI. vDisks appear to the guest OS as if they were a physical disk or the same as a VMDK does in vSphere environments and do not require any special in guest configuration.
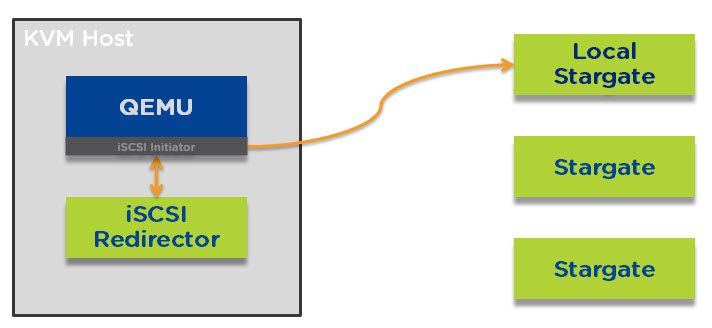
The I/O path for each vDisk bypasses the underlying QEMU storage stack and has a direct TCP connection to the iSCSI target on the local Controller VM. This bypasses any/all queues at the hypervisor layer and allows Stargate to manage the one and only queue.
Importantly, every single vDisk has its own TCP connection to stargate which means vdisks do not share any queues until they hit the storage controller (stargate). This reduces points of contention to Stargate itself and as every AHV node runs a stargate instance (within the CVM), only VMs on the same node share the queue for stargate, further reducing the chances of contention.
For those of you who are not familiar with the underlying Nutanix architecture, check out the below video describing what stargate does.
Because the vDisk is presented as a LUN via iSCSI the commands being sent do not require SCSI protocol emulation and simply send native SCSI commands.
The below diagram shows a VM with 3 vDisks and how they connect to Stargate. You will note QEMU is completely bypassed which optimises the I/O path.
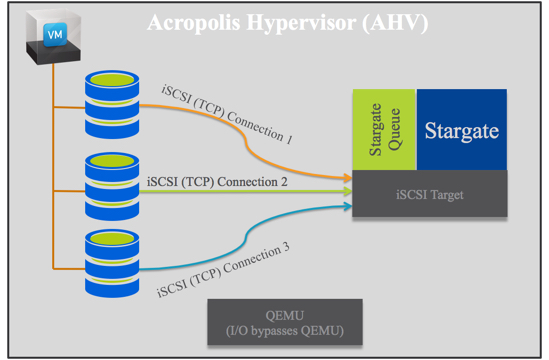
If a Virtual machine has more than 3 vDisks, each additional vDisk will have its own TCP connection.
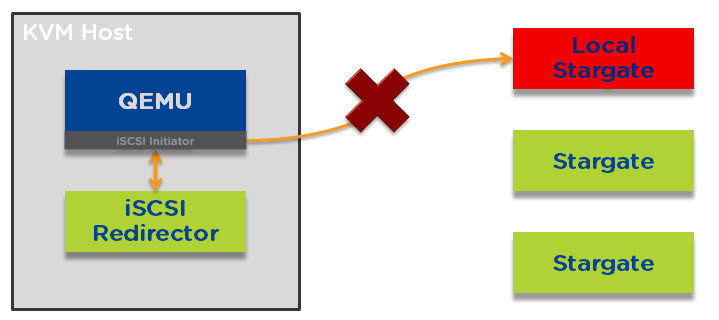
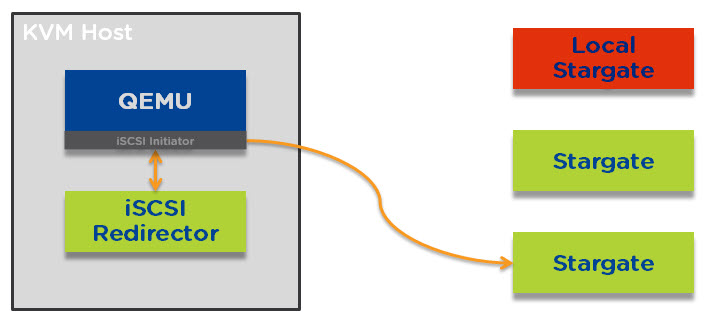
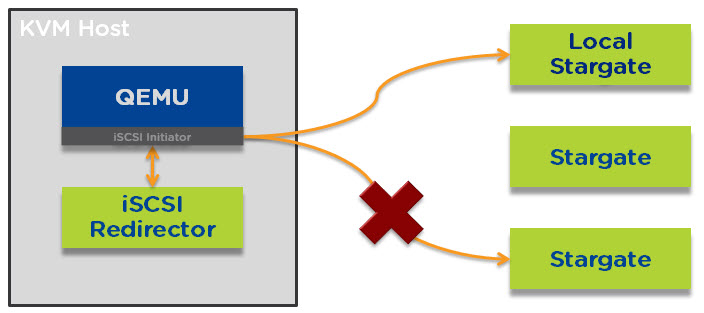
In the event the local Stargate instance is offline for any reason (e.g.: Rolling One-Click upgrade or CVM failure) each TCP connection will be redirected in a round robin manner across all the CVMs within the Nutanix cluster as described in Acropolis Hypervisor (AHV) I/O Failover & Load Balancing.
Related Posts:
1. Scaling Hyper-converged solutions – Compute only.
2. Advanced Storage Performance Monitoring with Nutanix
3. Why AHV is the next generation hypervisor – 10 Part Series