At VMware vForum Sydney this week I presented “Taking vSphere to the next level with converged infrastructure”.
Firstly, I wanted to thank everyone who attended the session, it was a great turnout and during the Q&A there were a ton of great questions.
I got a lot of feedback at the session and when meeting people at vForum about how the Nutanix scale out shared nothing architecture tolerates failures.
I thought I would summarize this capability as I believe its quite impressive and should put everyone’s mind at ease when moving to this kind of architecture.
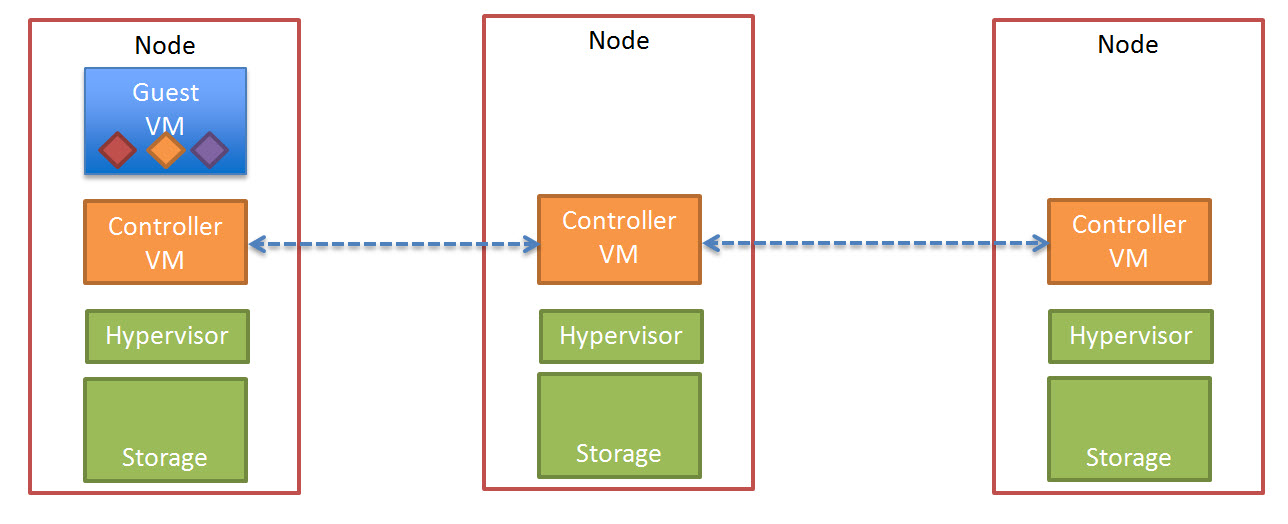
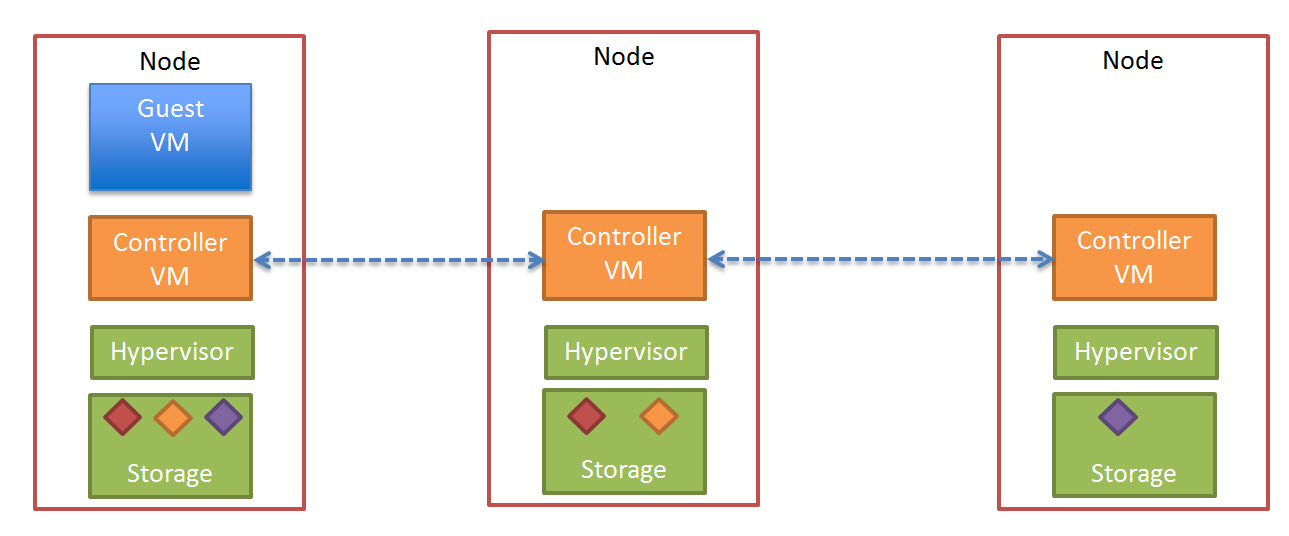
So lets take a look at a 5 node Nutanix cluster, and for this example, we have one running VM. The VM has all its data locally, represented by the “A” , “B” and “C” and this data is also distributed across the Nutanix cluster to provide data protection / resiliency etc.

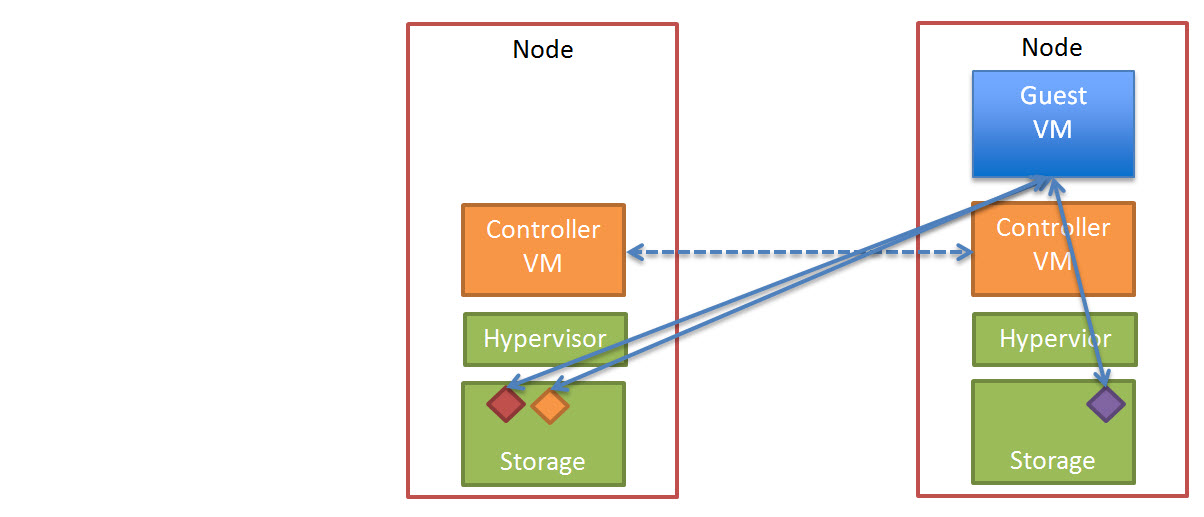
So, what happens when an ESXi host failure, which results in the Nutanix Controller VM (CVM) going offline and the storage which is locally connected to the Nutanix CVM being unavailable?
Firstly, VMware HA restarts the VM onto another ESXi host in the vSphere Cluster and it runs as normal, accessing data both locally where it is available (in this case, the “A” data is local) and remotely (if required) to get data “B” and “C”.

Secondly, when data which is not local (in this example “B” and “C”) is accessed via other Nutanix CVMs in the cluster, it will be “localized” onto the host where the VM resides for faster future access.
It is importaint to note, if data which is not local is not accessed by the VM, it will remain remote, as there is no benefit in relocating it and this reduces the workload on the network and cluster.
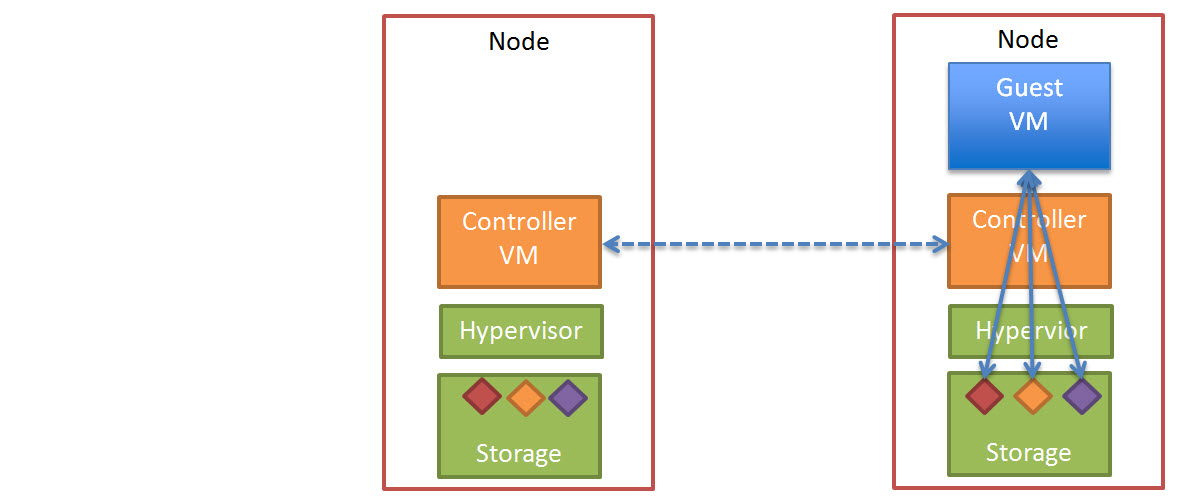
The end result is the VM restarts the same as it would using traditional storage, then the Nutanix cluster “curator” detects if any data only has one copy, and replicates the required data throughout the cluster to ensure full resiliency.
The cluster will then look like a fully functioning 4 node cluster as show below.

The process of repairing the cluster from a failure is commonly incorrectly compared to a RAID pack rebuild. With a raid rebuild, a small number of disks, say 8, are under heavy load re striping data across a hot spare or a replacement drive. During this time the performance of everything on the RAID pack is significantly impacted.
With Nutanix, the data is distributed across the entire cluster, which even with a 5 node cluster will be at least 20 SATA drives, but with all data being written to SSD then sequentially offloaded to SATA.
The impact of this process is much less than a RAID rebuild as all Nutanix controllers in the cluster participate and take a portion of the workload as a result the impact per disk, per controller ,per node and importantly for production VMs running in the cluster, is greatly reduced.
Essentially, the larger the cluster, the faster the cluster can repair itself, and the lower the impact on production workloads.
Now lets talk about a subsequent ESXi host failure, now we have two failed nodes, and three surviving nodes, and only one copy of data “A” , “B” and “C” as shown below.

Now the Nutanix “Curator” detects only one copy of data “A”, “B” and “C” exists and starts to replicate copies of “A”, “B” and “C” across the cluster. This results in the below which is a fully functional and redundant cluster, capable of surviving yet another failure as shown below.

Even in this scenario, where two ESXi hosts are lost, the environment still has 60% of its storage controllers (and performance), as compared to a typical traditional storage product where the loss of just two (2) controllers can have your environment completely offline, and even if you only lost a single controller, you would only have 50% of the storage controllers (and performance) available.
I think this really highlights what VMware and players like Google, Facebook & Twitter have been saying for a long time, scaling out not up, and shared nothing architecture is the way of the future. The only question is who will be dominant in bringing this technology to the mass market, and I think you know who I have my money on.