Scalability is not just about the number of nodes that can form a cluster or the maximum storage capacity. The more important aspects of scalability is how an environment expands from many perspectives including Management, Performance, Capacity, Resiliency and how scaling effects Operational aspects.
Let’s start with scalability of the components required to Manage/Administrator AHV:
Management Scalability
AHV automatically sizes all Management components during deployment of the initial cluster, or when adding node/s to the cluster. This means there is no need to do initial sizing or manual scaling of XCP management components regardless of the initial and final size of the cluster/s.
Where Resiliency Factor of 3 (N+2) is configured, the Acropolis management components will be automatically scaled to meet the N+2 requirement. Let’s face it, there is no point having N+2 at one layer and not at another because availability, like a Chain, is only as good as its weakest link.
Storage Capacity Scaling
The Nutanix Distributed Storage Fabric (DSF) has no maximum Storage Capacity, additionally, storage capacity can even be scaled separately to compute with “Storage-only” nodes such as the NX-6035C. Nutanix storage only nodes help eliminate the problems when scaling capacity compared to traditional storage.
Scaling Storage-only nodes run AHV (which are interoperable with other supported hypervisors) allowing customers to scale capacity regardless of Hypervisor. Storage-only nodes do not require hypervisor licensing or separate management. Storage only nodes also fully support all one-click upgrades for the Acropolis Base Software and AHV just like compute+storage nodes. As a result, storage only nodes are invisible, well apart from the increased capacity and performance which the nodes deliver.
Nutanix Storage only nodes help eliminate the problems when scaling capacity compared to traditional storage, for more information see: Scaling problems with traditional shared storage.
Some of the scaling problems with traditional storage is adding shelves of drives and not scaling data services/management. This leads to problems such as lower IOPS/GB and higher impact to workloads in the event of component failures such as storage controllers.
Scaling storage only nodes is remarkably simple. For example a customer added 8 x NX6035C nodes to his vSphere cluster via his laptop on the showroom floor of vForum Australia in October of this year.
https://twitter.com/josh_odgers/status/656999546673741824
As each storage-only node is added to the cluster, a light-weight Nutanix CVM joins the cluster to provide data services to ensure linear scale out management and performance capabilities, thus avoiding the scaling problems which plague traditional storage.
For more information on Storage only nodes, see: http://t.co/LCrheT1YB1
Compute Scalability
Enabling HA within a cluster requires reserving one or more nodes for HA. This can create unnecessary inefficiencies when the hypervisor limits the maximum cluster size. AHV not only has no limit to the number of nodes within a cluster. As a result, AHV can help avoid unnecessary silos that can lead to inefficient use of infrastructure due to requiring one or more nodes per cluster to be reserved for HA. AHV nodes are also automatically configured with all required settings when joining an existing cluster. All the administrator needs to provide is basic IP address information, Press Expand cluster and Acropolis takes care of the rest.
See the below demo showing how to expand a Nutanix cluster:
Analytics Scalability
AHV includes built-in Analytics and as with the other Acropolis Management components, Analysis components are sized automatically during initial deployment and scales automatically as nodes are added.
This means there is never tipping point where there is a requirement for an administrator to scale or deploy new Analysis instances or components. The analysis functionality and its performance remains linear regardless of scale.
This means AHV eliminates the requirement for seperate software instances and database/s to provide analytics.
Resiliency Scalability
As Acropolis uses the Nutanix Distributed Storage Fabric, in the event drive/s or node/s fail, all nodes within the cluster participate in restoring the configured resiliency factor (RF) for the impacted data. This occurs regardless of Hypervisor, however, AHV includes fully distributed Management components; the larger the cluster, the more resilient the management layer also becomes.
For example, the loss of a single node in a 4-node cluster would have potentially a 25% impact on the performance of the management components. In a 32-node cluster, a single node failure would have a much lower potential impact of only 3.125%. As an AHV environment scales, the impact of a failure decreases and the ability to self-heal increases in both speed to recover and number of subsequent failures which can be supported.
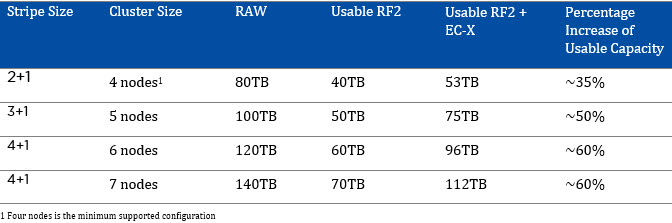
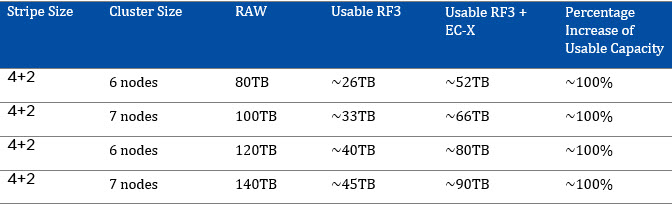
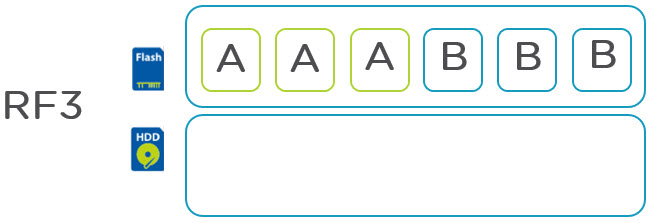
For information about increasing resiliency of large clusters, see: Improving Resiliency of Large Clusters with EC-X
Performance Scalability
Regardless of hypervisor, as XCP clusters grow, the performance improves. The moment new node(s) are added to the cluster, the additional CVM/s start participating in Management and Data Resiliency tasks even when no VMs are running on the nodes. Adding new nodes allows the Storage Fabric to distribute RF traffic among more Controllers which enhances Write I/O & resiliency while helping decrease latency.
The advantage that AHV has over the other supported hypervisors is that the performance of the Management components (many of which have been previously discussed) dynamically scale with the cluster. Similar to Analytics, AHV management components scale out. There is never a tipping point requiring manual scale out of management or new deploying instances of management components or their dependencies.
Importantly, for all components, the XCP distributes data and management functions across all nodes within the cluster. Acropolis does not use “mirrored” components/hardware or objects which ensures no two nodes or components/hardware become a bottleneck or point of failure.