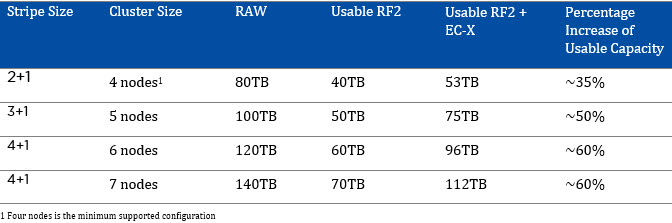
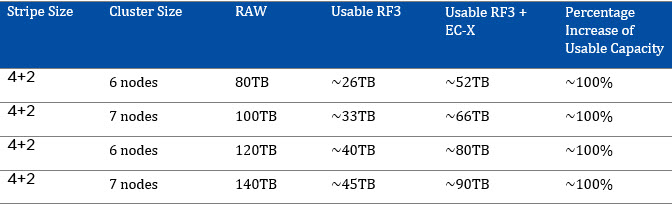
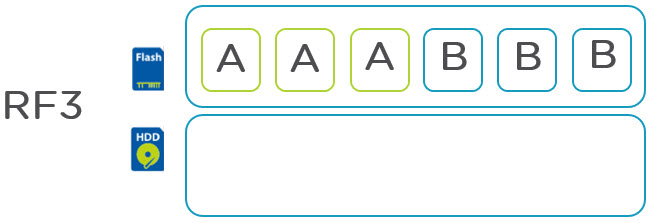
There are so many “under the cover” capabilities of the Acropolis Distributed Storage Fabric (ADSF) which have been designed and built not for short term marketing “checkboxes” but with a long term vision in mind.
As a result, Nutanix has been able to continually innovate and stay ahead of the HCI market while building a next generation platform (including the Acropolis Hypervisor, AHV) for the enterprise cloud.
Nutanix is also 100% software defined which makes adding new features and enhancing existing features possible even for hardware which is several years old.
As a result of the forward looking development of ADSF, it has allowed Nutanix to lead in the SDS space with features like Compression, Deduplication and Erasure Coding (EC-X).
In-line Compression is recommended for most workloads including business critical applications such as Oracle, SQL and Exchange and typically provides not only excellent capacity savings but an increased effective SSD capacity which results in higher performance. Compressing data on the capacity tier (not just flash tier) also helps improve performance and lowers the cost per GB of storage.
As of the next release, the compression functionality has been enhanced to support compressed and uncompressed slices in the same extent groups which for those of you not familiar with ADSF, an “Extent Group” is a group of “Extents” in which data is stored.
In previous generations of ADSF, regardless of if ADSF got good compression or not – all the data for a virtual disk (vdisk) residing in a container with compression enabled will have all of its data compressed. This can causes unnecessary overheads especially in cases where compression savings are minimal, such as for already compressed data such as Video or image files (e.g.: JPG).
This is one reason why it’s important that data reduction features such as compression (and Dedupe/Erasure Coding) can be turned off for workloads where benefits are minimal.
Previously in ADSF, compressed and uncompressed data was not supported within the same extent group which resulted in the cluster (Curator) having the added overhead of moving extents from one extent group to another even for data with low/no compression benefits.
This unnecessary overhead has now been removed which means less background tasks (overheads) resulting in lower CPU utilization by the Nutanix Controller VM (CVM) and better overall compression performance.
Secondly, Nutanix will be moving to the LZ4 group of algorithms which has two variants, LZ4 and LZ4H. LZ4H is really exciting because it gets nearly as much compression as Zlib while having a similar CPU cost but can decompress at the speed of LZ4. LZ4 by itself is marginally superior to Snappy in the common case, but the LZ4H makes this a very attractive choice.
This allows ADSF to do tiered compression – so cold data compressed with LZ4 can be further compressed with LZ4H giving higher compression ratios.
Also some good news for existing customers, this enhanced compression will be included in the next major AOS update which can be deployed via One-Click upgrade without any downtime or the requirement to reformat the drives, that’s true software defined storage.
Stay tuned for an upcoming blog showing the before and after compression savings on the same dataset.
Summary:
The upcoming releases of Acropolis OS (AOS) will provide:
- Higher compression savings
- Lower CVM overheads
- Dramatically reduced background file system maintenance tasks
- Enhanced compression will be included in the next major AOS one click upgrade!
Related .NEXT 2016 Posts
- What’s .NEXT 2016 – All Flash Everywhere!
- What’s .NEXT 2016 – Acropolis File Services
- What’s .NEXT 2016 – Acropolis X-Fit
- What’s .NEXT 2016 – Any node can be storage only
- What’s .NEXT 2016 – Metro Availability Witness
- What’s .NEXT 2016 – PRISM integrated Network configuration for AHV
- What’s .NEXT 2016 – Enhanced & Adaptive Compression
- What’s .NEXT 2016 – Acropolis Block Services
- What’s .NEXT 2016 – Self Service Restore