
It seems like the FUD is surging out of Cisco thick and fast, which is great news since Nutanix is getting all the mind share and recognition as the clear market leader.
The latest FUD from Cisco is their Virtual Storage Appliance (VSA, or what Nutanix calls a Controller VM, or CVM) is better than Nutanix because it provides I/O from across the cluster where as Nutanix only serves I/O locally.
I quite frankly don’t care how Cisco or any other vendor does what they do, I will just explain what Nutanix does and why then you can make up your own mind.
Q1. Does Nutanix only serve I/O locally?
A1. No
Nutanix performs writes (e.g.: RF2/RF3) across two or three nodes before providing an acknowledgement to the guest OS. One copy of the data is always written locally except in the case where the local SSD tier is full in which case all copies will be written remotely.
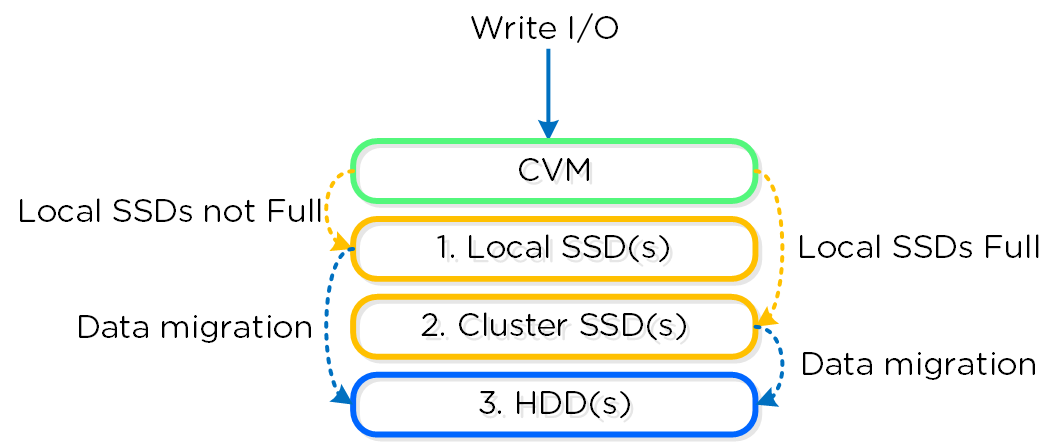
The above image is courtesy of the Nutanix Bible by Steve Poitras.
It shows that Write I/O is prioritized to be local to the Virtual Machine to enable future Read I/O to be served locally thus removing the network, other nodes/controllers as a potential bottleneck/dependancy and ensuring optimal performance.
This means a single VM can be serviced by “N” number of Controllers concurrently, which improves performance.
Nutanix does this as we want to avoid as many dependancies as possible. Allowing the bulk of Read I/O to be serviced locally helps avoid traditional storage issues like noisy neighbour. By writing locally we also avoid at least 1 network hop and remote controller/node involvement as one of the replica’s is always written locally.
Q2. What if a VM’s active data exceeds the local SSD tier?
A2. I/O will be served by controllers throughout the Cluster
I have previously covered this topic in a post titled “What if my VMs storage exceeds the capacity of a Nutanix node?“. As a quick summary, the below diagram shows a VM on Node B having its data served across a 4 node cluster all from SSD.
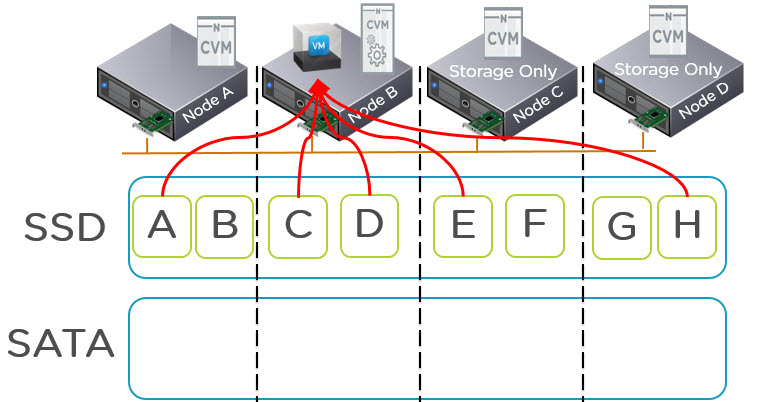
The above diagram also shows the node types can be Compute+Storage or Storage Only nodes while still providing SSD tier capacity and a Nutanix CVM to provide I/O and data services such as Compression/Dedupe/Erasure Coding as well as monitoring / management capabilities.
Q3. What if data is not in the SSD tier?
A3. If data is migrated to the SATA tier, it is accessed based on avg latency either locally or remotely.
If data is moved from SSD to SATA, the 1st option is to service the I/O locally, but if the local SATA latency is above a threshold, the I/O will be serviced by a remote replica. This ensures in the unlikely event of contention locally, I/O is not unnecessarily delayed.
For reads from SATA, the bottleneck is the SATA drive itself which means the latency of the network (typically <0.5ms) is insignificant when several ms can be saved by using a replica on drives which are not as busy.
This is explained in more detail in “NOS 4.5 Delivers Increased Read Performance from SATA“.
Q4. Cisco HX outperforms Nutanix
A4. Watch out for 4K unrealistic benchmarks, especially on lower end HW & older AOS releases.
I am very vocal that peak performance benchmarks are a waste of time, as I explain in the following article “Peak Performance vs Real World Performance“.
VMware and EMC constantly attack Nutanix on performance, which is funny because Nutanix AOS 4.6 outperforms VSAN comfortably as I show in this article: Benchmark(et)ing Nonsense IOPS Comparisons, if you insist – Nutanix AOS 4.6 outperforms VSAN 6.2
Cisco will be no different, they will focus on unrealistic Benchmark(et)ing which I will respond to the upcoming nonsense in the not to distant future when it is released.
Coming soon: Cisco HX vs Nutanix AOS 4.6
Summary:
One of the reasons Nutanix is the market leader is our attention to detail. The value of the platform exceeds the sum of its parts because we consider and test all sorts of scenarios to ensure the platform performs in a consistent manner.
Nutanix can do things like remote SATA reads, and track performance and serve I/O from the optimal location because of the truly distributed underlying storage fabric (ADSF). These sort of capabilities are limited or not possible without this kind of underlying fabric.
Related Posts: