I was made aware of a recent article from Rob Klusman at Netapp titled “Netapp HCI Verses Nutanix” by a Nutanix Technology Champion (NTC) who asked for us to respond to the article “cause there’s some b*llsh*t in it”.
** UPDATE **
Netapp have since removed the post, it can now be viewed via Google Cache here:
http://webcache.googleusercontent.com/search?q=cache:https://blog.netapp.com/netapp-hci-vs-nutanix/
I like it when people call it like it is, so here I am responding to the bullshit (article).
The first point I would like to address is the final statement in the article.
NetApp HCI is the first choice, and Nutanix is the second choice. Leading in an economics battle just doesn’t work if performance is lacking.
Rob rightly points out Nutanix leads the economic battle so kudos for that, but he follows up by implying Nutanix performance is lacking. Wisely Rob does not provide any follow up which can be discredited, so I will just leave you with these three posts discussing how Nutanix scales performance for Single VMs, Monster VMs and Physical servers from my Scalability, Resiliency & Performance blog series.
Part 3 – Storage Performance for a single Virtual Machine
Part 4 – Storage Performance for Monster VMs with AHV!
Part 5 – Scaling Storage Performance for Physical Machines
Rob goes on to make the claim:
Nutanix wants infrastructure “islands” to spread out the workloads
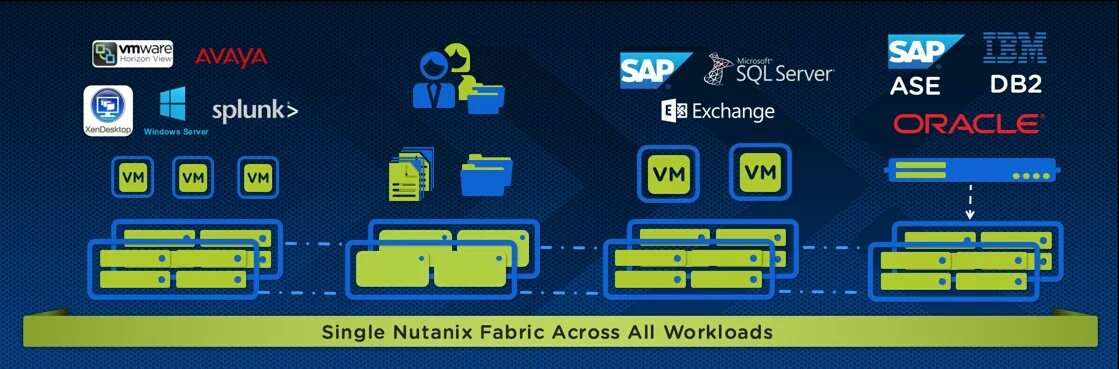
This is just incorrect and not only is it incorrect, Nutanix has been recommending mixed workload deployments for many years. Here is an article I wrote in July 2016 titled “The All-Flash Array (AFA) is Obsolete! where I conclude with the following summary:

I specifically state mixed workloads including business critical applications are supported without creating silos. It’s important to note this statement was made in July 2016 before Netapp had even started shipping (Oct 25th 2017) their 3-tier architecture product which they continue to incorrectly refer to as HCI.
Gartner supports my statement that the Netapp product is not HCI and states:
“NetApp HCI competes directly against HCI suppliers, but its solution does not meet Gartner’s functional definition of HCI.”
Mixed workloads is nothing new for Nutanix, and not only is mixing workloads supported, I frequently recommend it as it increases performance and resiliency as described in detail in my blog series Nutanix | Scalability, Resiliency & Performance.
Now let’s address the “Key Differences” Netapp claim:
User interface. Both products have an intuitive graphical interface that is well integrated into the hypervisor of choice. But what’s not obvious is that simplicity goes well beyond where you click. NetApp HCI has the most extensive API in the market, with integration that allows end users to automate even the most minute features in the NetApp HCI stack.
The philosophy of Nutanix intuitive GUI (which Netapp concedes) is all features in the GUI must be made available via an API. In the PRISM GUI Nutanix provides the “REST API Explorer” (shown below) where users can easily understand the available operations to automate anything they choose.
Next up we have:
Versatile scale. How scaling is accomplished is important. NetApp HCI scales in small infrastructure components (compute, memory, storage) that are all interchangeable. Nutanix requires growth in specific block components, limiting the choices you can make.
When vendors attack Nutanix, I am always surprised they try and attack the scalability capabilities as if anything, this is one of the strongest areas for Nutanix.
I’ve already referenced my my Scalability, Resiliency & Performance blog series where I go into a lot of detail on these topics but in short, Nutanix can scale:
- Storage Only by adding drives or nodes
- Compute Only by adding RAM or nodes
- Compute + Storage by adding drives and/or nodes
Back in mid 2013 when I joined Nutanix, the claim by Netapp was true as only one node type (NX-3450) was available, but later that same year the 1000 and 6000 series were released giving more flexibility and things have continued to become more flexible over the years.
Today the flexibility (or versatility) in scale for Nutanix solutions is second to none.
Performance. Today, it’s an absolute requirement for HCI to have an all-flash solution. Spinning disks are slightly less expensive, but you’re sacrificing production workloads. NetApp HCI only offers an all-flash solution.
Congratulations Netapp, you do all flash, just like everyone else (but you came to the party years later). There a many use cases for bulk storage capacity, be it all flash or hybrid, Nutanix provides NVMe+SATA-SSD, All SATA-SSD and SATA-SSD+SAS/SATA HDD options to cover all use cases and requirements.
Not only that but Nutanix allows mixing of All Flash and Hybrid nodes to further avoid the creation of silos.
Enterprise ready. This is an important test. One downfall of Nutanix software running on exactly the same CPU cores as your applications is the effect on enterprise readiness. Many of our customers have shifted away from Nutanix once they’ve seen what happens when a Nutanix component fails. It’s easier to move the VM workload off the current Nutanix system (the one that’s failing) than it is to wait for the fix. Nutanix does not run optimally in hardware-degraded situations. NetApp HCI has no such problem; it can run at full workloads, full bandwidth, and full speed while any given component has failed.
It’s a huge claim by Netapp to dispute Nutanix’ enterprise readiness, considering we have many more years of experience shipping product but hey, Netapp’s article is proving to be without factual basis every step of the way.
The beauty of Nutanix is the ability to self heal after failures (hardware or software) and then tolerate subsequent failures. Nutanix also has the ability to tolerate multiple concurrent failures including up to 8 nodes and 48 physical drives (NVMe/SSD/HDD).
Nutanix can also tolerate one or more failures and FULLY self heal without any hardware being replaced. This is critical as I detailed in my post: Hardware support contracts & why 24×7 4 hour onsite should no longer be required.
For more details on these failure scenarios checkout the Resiliency section of my blog series Nutanix | Scalability, Resiliency & Performance.
Workload performance protection. No one should attempt an advanced HCI deployment without workload performance protection. Only NetApp HCI provides such a guarantee, because this protection is built into the native technology.
One critical factor in delivering consistent high performance is data locality. The further data is from the compute layer, the more bottlenecks there are to potentially impact performance. It’s important to Evaluate Nutanix’ original & unique implementation of Data Locality to understand that features such as QoS for Storage IO are features which are critical with scale up shared storage (a.k.a SAN/NAS) but when using a highly distributed scale out architecture, noisy neighbour problems are all but eliminated by the fact you have more controllers and that the controllers are local to the VMs.
Storage QoS is added complexity, and only required when a product such as a SAN/NAS has no choice but to deal with the IO blender effect where sequential IO is received as random due to competing workloads, this effect is minimised with Nutanix Distributed Storage Fabric.
Shared CPU cores. One key technical difference between the Nutanix product and NetApp HCI is the concept of shared CPU cores. Nutanix has processes running in the same cores as your applications, whereas NetApp HCI does not. There is a cost associated with sharing cores when applications like Oracle and VMware are licensed by core count. You actually pay more for those applications when Nutanix runs their processes on your cores. It’s important to do that math.
I’m very happy Rob raised the point regarding VMware’s licensing (part of what I’d call #vTAX), this is one of the many great reasons to move to Nutanix next generation hypervisor AHV (Acropolis Hypervisor).
In addition, for workloads like Oracle or SQL where licensing is an issue, Nutanix offers two solutions which address these issues:
- Compute Only Nodes running AHV
- Acropolis Block Services (ABS) to provide the Nutanix Distributed Storage Fabric (ADSF) to physical or virtual servers not running on Nutanix HCI nodes.
But what about the Nutanix Controller VM (CVM) itself? It is assigned vCPUs which share physical CPU cores with other virtual machines.
Sharing Physical cores is a bad idea as virtualisation has taught us over many years. Hold on, wait, no that’s not it (LOL!), Virtualisation has taught us we can share physical CPU cores very successfully even for mission critical applications where it’s done correctly.
Here is a detailed post on the topic titled: Cost vs Reward for the Nutanix Controller VM (CVM)
Asset fluidity. An important part of the NetApp scale functionality is asset fluidity – being able to move subcomponents of HCI around to different applications, nodes, sites, and continents and to use them long beyond the 3-year depreciation cycle.
This is possibly the weakest argument in Netapp’s post, Nutanix nodes can be removed non disruptively from a cluster and added to any other cluster including mixing all flash and hybrid. Brand new nodes can be mixed with any other generation of nodes, I regularly form large clusters using multiple generations of hardware.
Here is a tweet of mine from 2016 showing a 22 node cluster with four different node types across three generations of hardware (G3 being the original NX-8150, G4 and G5).
Data Fabric. The NetApp Data Fabric simplifies and integrates data management across clouds and on the premises to accelerate digital transformation. To plan an enterprise rollout of HCI, a Data Fabric is required – and Nutanix has no such thing. NetApp delivers a Data Fabric that’s built for the data-driven world.
I had to look up what Netapp mean by “Data Fabric” as it sounded to me like a nonsense marketing term, and surprise surprise I was right. Here is how Netapp describe “Data Fabric“.
Data Fabric is an architecture and set of data services that provide consistent capabilities across a choice of endpoints spanning on-premises and multiple cloud environments.
It’s a fluffy marketing phrase but the same could easily be argued about Nutanix Distributed Storage Fabric (ADSF). ADSF is hypervisor agnostic which straight away delivers a multiple platform solution (cloud or on premises) including AWS and Azure (below).
Nutanix can replicate and protect data including virtual machines across different hardware, clusters, hypervisors and clouds.
So the claim “Nutanix does not have a Data Fabric” is pretty laughable based on Netapp’s own description of “Data Fabric”.
Now the final point:
Choosing the Right Infrastructure for Your Enterprise
I’ve written about Things to consider when choosing infrastructure and my conclusion was:

Nutanix has for many years provided a platform which can be your standard for all workloads and the number of niche workloads that cannot be genuinely supported are now so rare with all the enhancements we’ve made over the years.
The best thing about Nutanix, with our world class enterprise architect enablement and Nutanix Platform Expert (NPX) certification programmes, we ensure our field S.Es , Architects and certified individuals that design and implement solutions for customers every day know exactly when to say “No”.
This culture of customer success first, sales last, comes from our former President Sudheesh Nair who wrote this excellent article during his time at Nutanix
After addressing all the points raised by Netapp, it’s easy to see that Nutanix has a very complete solution thanks to years of development and experience with enterprise customers and their mission critical applications.
Have you read any other “b*llsh*t” you’d like Nutanix to respond to, if so, don’t hesitate to reach out.