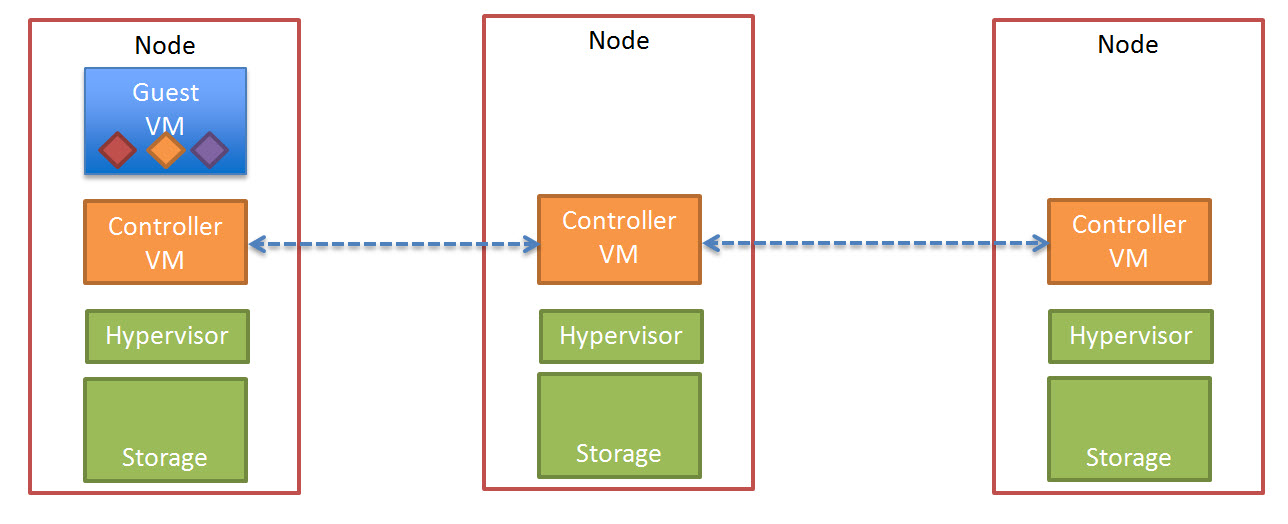
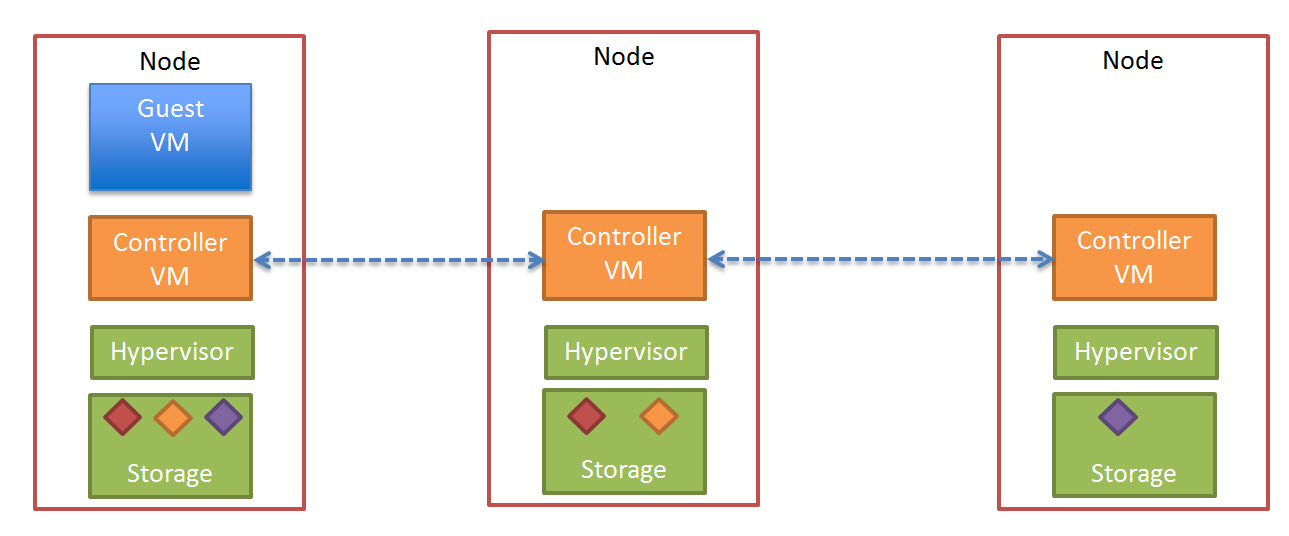
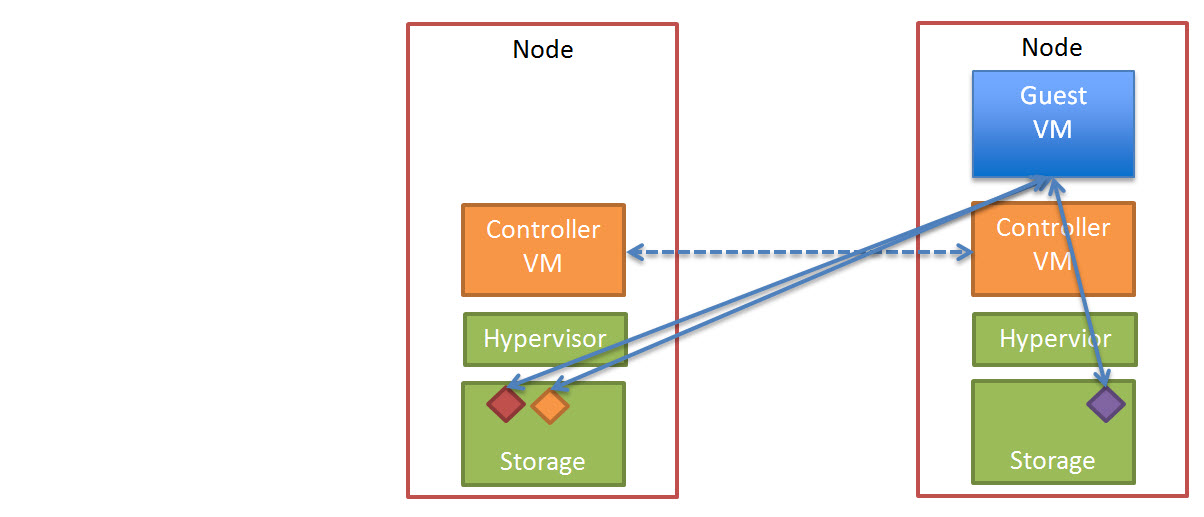
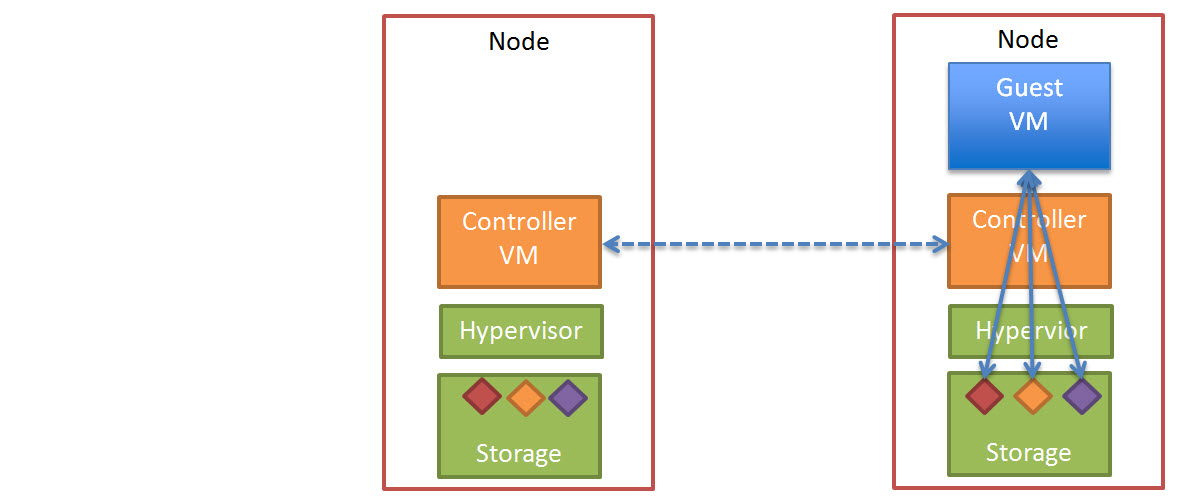
Since joining Nutanix back in July 2013, I have been working on testing the performance and resiliency of a range of virtual workloads including Business Critical Applications on the Nutanix platform. At the time, Nutanix only offered a single form factor (4 nodes in 2RU) which was not always a perfect fit depending on customer requirements.
Fast forward to August 2014 and now Nutanix has a wide range of node types to meet most workload requirements which can be found here.
The only real gap in the node types was a node which would support applications with large capacity requirements and also have a very large active working set which requires consistent low latency and high performance regardless of tier.
So what do I mean when I say “Active working Set”. I would define this as a data being regularly accessed by the VM/s, for example a file server may have 10TB of data, but users only access 10% on a regular basis. This 10% I would classify as the Active Working Set.
Now back to the topic at hand, The reason I am writing this post is because this has been a project I have been working towards for some time, and I am very excited about this product being released to the market. I have no doubt it will further increase the already fast up take of the Web-scale solutions and provide significant value and opportunities to new and existing customers wanting to simplify their datacenter/s and standardize on Nutanix Web-scale architecture.
Along with many others at Nutanix, we proposed a new node type (being the NX-8150), which has been undergoing thorough testing in my team (Solutions & Performance Engineering) for some time and I am pleased to say is being officially released (very) soon!

What is the NX-8150?
A 1 Node per 2RU platform with the following specifications:
* 2 CPU Sockets with two CPU options (E5-2690v2 [20 cores / 3.0 GHz] OR E5-2697v2 [24 cores / 2.7 GHz]
* 4 x Intel 3700 Series SSDs (ranging from 400GB to 1.6TB ea)
* 20 x 1TB SATA HDDs
* Up to 768GB RAM
* Up to 4 x 10GB NICs
* 4 x 1GB NICs
* 1 x IPMI (Out of band Management)
What is the use case for the NX-8150?
Simply put, Applications which have high CPU/RAM requirements with large active working sets and/or the requirement for consistent high performance over a large data set.
Some examples of these applications include:
* Microsoft Exchange including DAG deployments
* Microsoft SQL including Always on Availability Groups
* Oracle including RAC
* SAP
* Microsoft Sharepoint
* Mixed Production Server Workloads with varying Capacity & I/O requirements
The NX-8150 is a great platform for the above workloads as it not only has fast CPUs and up to a massive 768GB of RAM to provide substantial compute resources to VMs, but also up to a massive 6.4TB of RAW SSD capacity for Virtual machines with high IO requirements. For workloads where peak performance is not critical the NX-8150 also provides solid consistent performance across the “Cold Tier” provided by the 20 x 1TB HDDs.
As with all Nutanix nodes, Intelligent Life-cycle management (ILM) maximizes performance by dynamically migrating hot data to SSD and cold data to SATA to provide the best of both worlds being high IOPS and high capacity.
One of the many major advantages of Nutanix Web-Scale architecture is Simplicity and its ability to remove the requirement for application specific silos! Now with the addition of the NX-8150 the vast majority of workloads including Business Critical Applications can be ran successfully on Nutanix, meaning less silos are required, resulting in a simpler, more cost effective, scalable and resilient datacenter solution.
Now with a number of customers already placing advanced orders for NX-8150’s to deploy Business Critical Applications, it wont be long until the now common “Virtual 1st” policies within many organisations turns into a “Nutanix Web-Scale 1st” policy!
Stay tuned for upcoming case studies for NX-8150 based Web-Scale solutions!