Over the past few weeks with the release of Acropolis base version 4.5 (formally known as NOS) on the horizon there has been a lot of interest in Erasure Coding (EC-X) which was announced at Nutanix .NEXT conference in June this year.
The most common questions are how does EC-X increase the effective SSD tier capacity and the overall cluster usable capacity. This post aims to cover these questions.
Resiliency Factor 2 (RF2) & Erasure Coding
Resiliency Factor 2 ensures that two copies of all data are written to persistent media prior to being acknowledged to the guest operating system. This ensures at N+1 level of redundancy which translates to being able to tolerate a single failure.
RF2 provides a usable capacity of ~50% of RAW.
The below figure shows an example of RF2 where six blocks store three pieces of data in a redundant fashion. In this configuration a single SSD/HDD or node can be lost without impacting data availability.

Now let’s take a look at how the same 6 blocks will be utilized with Erasure Coding enabled:

As we can see, we are now able to store four pieces of data (A,B,C,D) with single parity to ensure data can be rebuilt in the event of a drive or node failure. As with standard RF2, an RF2 + EC-X configuration can also tolerate a single SSD/HDD or node can be lost without impacting data availability. We also free up space to be used for another EC-X stripe.
As a result, the usable capacity increases from approx. 50% usable up to 80% usable for clusters of six (6) or larger.
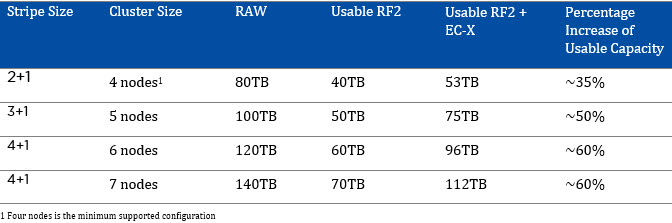
The following table shows the maximum usable capacity for RF2 + EC-X based on cluster size:
Note: Assumes 20TB RAW per node
Resiliency Factor 3 (RF3) & Erasure Coding
Resiliency Factor 3 ensures that three copies of all data are written to persistent media prior to being acknowledged to the guest operating system. This ensures at N+2 level of redundancy which translates to being able to tolerate two concurrent SSD/HDD or node failures.
RF3 provides a usable capacity of ~33% of RAW.
The below figure shows an example of RF3 where six blocks store two pieces of data in a redundant fashion. In this configuration the environment can tolerate two concurrent SSD/HDD or node failures without impacting data availability.

Now let’s take a look at how the same 6 blocks will be utilized with Erasure Coding enabled:

Similar to the RF2 example, we can see we are now able to store more data with the same level of redundancy. In this case, five pieces of data (A,B,C, D) with dual parity to ensure data can be rebuilt in the event of dual concurrent drive or node failures. As with standard RF3, an RF3 + EC-X provides an N+2 level of availability while providing higher usable capacity.
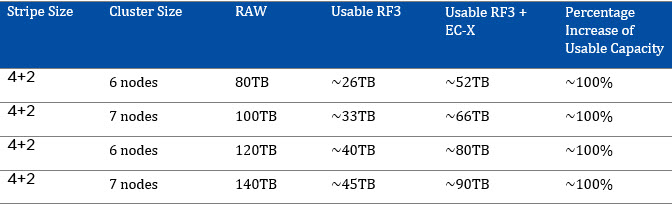
The following table shows the usable capacity for RF3 + EC-X based on cluster size:
Note: Assumes 20TB RAW per node
EC-X Parity Placement
To further increase the effective capacity of the SSD tier and there for supporting larger working set sizes with all flash performance, the Parity for containers with EC-X enabled is stored on the SATA tier.
The following figure shows a standard RF3 deployment:
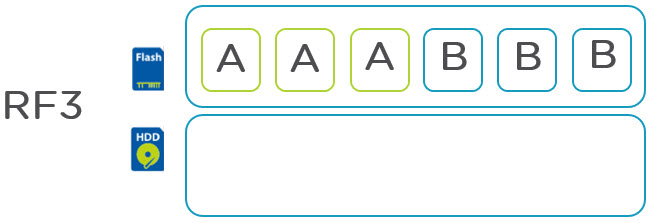
As we can see, 6 blocks of storage contain just 2 actual pieces of user data all of which reside in the SSD tier.
With RF3 + EC-X the same 6 blocks of storage contain 4 pieces of user data thus increasing the effective capacity of the SSD tier by 100% due to being able to store 4 piece of data compare to two with RF3. In addition the effective SSD capacity is further increased by moving the 2 parity blocks to SATA freeing up a further 33% SSD tier capacity.

I hope that explains how EC-X works and why its such an advantage for Nutanix current and futures customers.
Related Articles:
- Nutanix Erasure Coding Deep Dive
- Increasing resiliency of large clusters with Erasure Coding
- What I/O will EC-X take effect on?
- Sizing assumptions for solutions with Erasure Coding (EC-X)