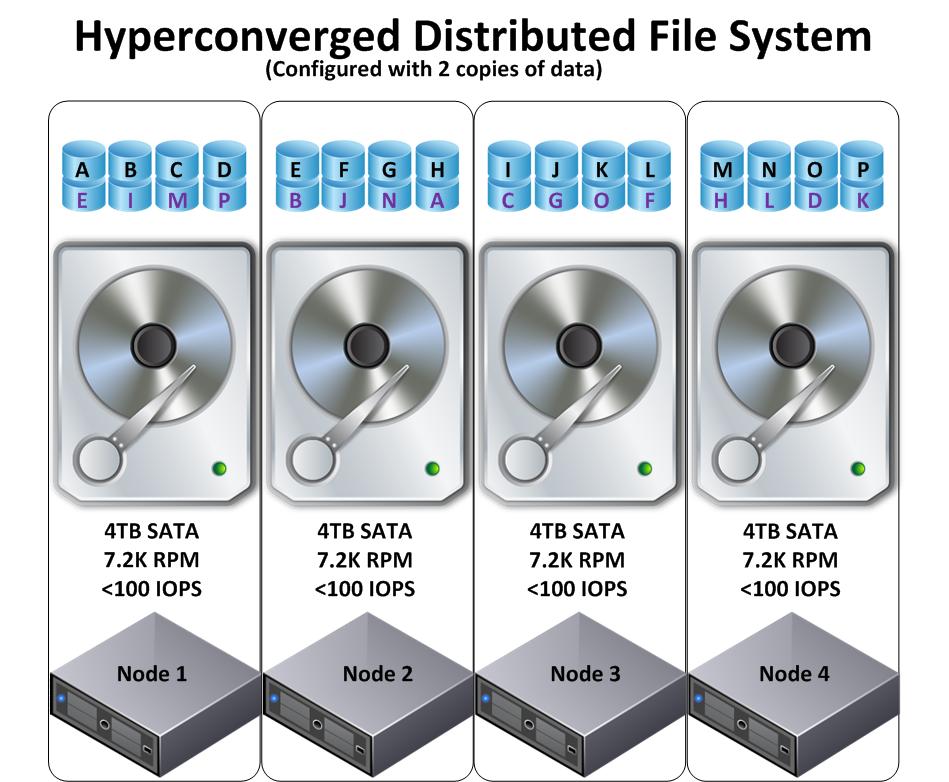
I get this question a lot, What if my VM exceeds the capacity of the node its running on. The answer is simple, the storage available to a VM is the entire storage pool which is made up of all nodes within the cluster and is not limited to the capacity of any single node.
Let’s take an extreme example, a single VM is running on Node B (shown below) and all other nodes have no workloads. Regardless of if the nodes are “Storage only” such as NX-6035C or any Nutanix node capable of running VMs e.g.: NX3060-G4 the SSD and SATA tiers are shared.
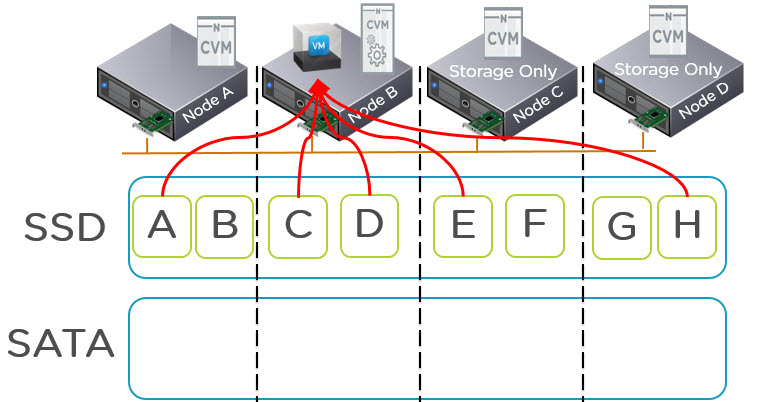
The VM will write data to the SSD tier and only once the entire SSD tier (i.e.: All SSD in all nodes) reaches 75% capacity will ILM tier the coldest data off the to SATA tier. So if the SSD tier never reaches 75% you will have all data in SSD tier both local and remote.
This means multiple CVMs (Nutanix Controller VM) will service the I/O which allows for single VMs to achieve scale up type performance where required.
As the SSD tier exceeds 75% data is tiered down to SATA but active data will still reside in SSD tier across the cluster and be serviced with all flash performance.
The below shows there is a lot of data in the SATA tier but ILM is intelligent enough to ensure hot data remains in the SSD tier.
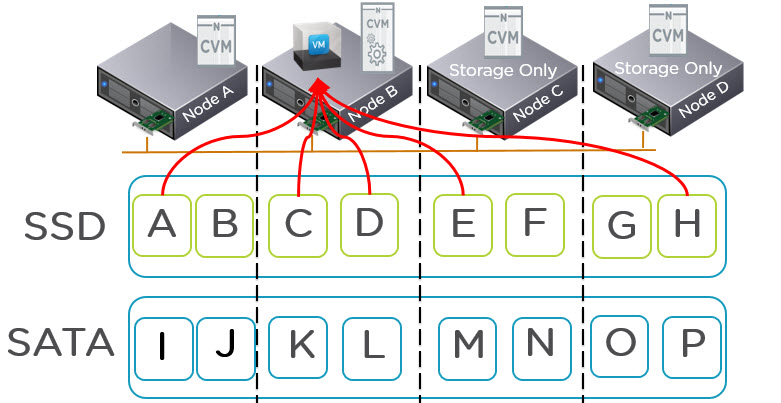
Now what about Data Locality, Data Locality is maintained where possible to ensure the overheads of going across the network are minimized but simply put, if the active working set exceeds the local SSD tier Nutanix ensures maximum performance by distributing data across the shared SSD tier (not just two nodes for example) and services I/O through multiple controllers.
In the worst case where the active working set exceeds the local SSD capacity but fits within the shared SSD tier, you will have the same performance as a Centralised All Flash Array, in the best case, Data Locality will avoid the requirement to traverse the IP network and service reads locally.
If the active working set exceeds the shared SSD tier, Nutanix also distributes data across the shared SATA tier and services I/O from all nodes within the cluster as explained in a recent post “NOS 4.5 Delivers Increased Read Performance from SATA“.
Ideally I recommend sizing the Active working set of VMs to fit within the local SSD tier but this is not always possible. If you’re running Nutanix you can find out what the active working set of a VM is via PRISM (See post here) and if you’re looking to size for a Nutanix solution, use my rule of thumb for sizing for storage performance in the new world.