
If you’ve not read Parts 1,2,3 and 4, we have already proven several claims by HPE Simplivity regarding Nutanix to be false, as well as explored the misleading way in which HPE SVT promote data efficiency.
The fun continues and in Part 5 we will discuss HPE’s claim that Nutanix does not have a “single screen management” (by which I assume they mean Single Pane of Glass) without extra fees or GUIs.
#HPE #HyperConverged 380 #HPEDare2Compare #Nutanix #HPEDiscover https://t.co/kn0Q1Il8l1 pic.twitter.com/5R8W6fRAlD
— Chris Purcell (@chrispman01) June 6, 2017
Unfortunately the URL was not working in the HPE tweet, I responded and made HPE aware of this so I could review specifically what they are claiming, but the link at the time of writing is still not working.
It’s funny HPE SVT mention this because Nutanix is the only HCI product which has a built in, distributed, scalable and multi hypervisor management solution.
The fact Nutanix has its own interface is a huge advantage especially because Nutanix is not dependant on any 3rd parties (e.g.: VMware vCenter) to install/configure and manage our platform. This reduces cost,complexity,risk,operational tasks and the list goes on.
Nutanix “PRISM Element” HTML 5 GUI is built into every Nutanix solution regardless of hypervisor or underlying hardware. The below screenshot shows the built in management capabilities to upgrade the Nutanix Acropolis (AOS) storage layer, the built in, scale out file server, the hypervisor (ESXi, Hyper-V or AHV) as well as upgrade Firmware, our Container support and our built in cluster imaging tool, Foundation.
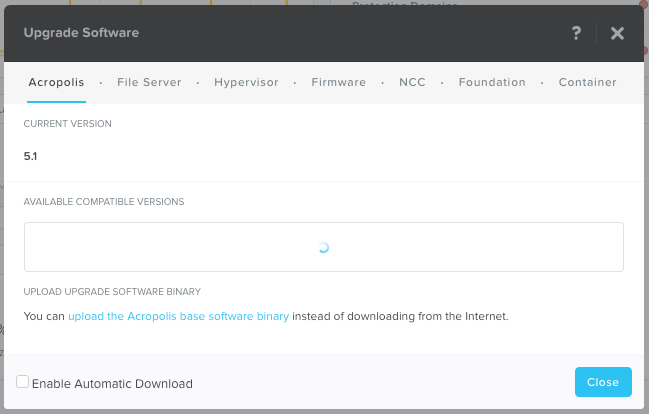
This means regardless of hypervisor, many of the critical tasks can be performed straight within PRISM and does not require the long in the tooth VMware Update Manager (VUM) which is long overdue for an overhaul. In fact, Nutanix supports four (4) hypervisors using our management tool (PRISM) whereas HPE SVT only has GA support for ESXi.
For customers using Acropolis Hypervisor (AHV), 100% of the management can be performed within PRISM Element and central management of multiple clusters is performed through PRISM Central.
AHV comes with all Nutanix solutions at no extra cost regardless of hardware choice (including HPE Proliant). This means customers enjoy the benefits of the next generation hypervisor, designed and built for HCI and Enterprise Cloud.
Unlike HPE SVT for example, Nutanix does not have a limit of 8 nodes per datacenter or 32 per “federation”, PRISM element can support a cluster of any size (currently no support limits) and PRISM central manages all the clusters.
Nutanix management is not tied to or more importantly dependant on VMware vCenter or any other hypervisor management tool, which adds to the resiliency and simplicity of the Nutanix platform. PRISM automatically scales in both performance and resiliency as a cluster expands to ensure consistent performance for system administrators. This avoids the complexity of designing/installing and maintaining a highly available vCenter solution which also uses additional compute and storage resources.
Summary:
- Nutanix PRISM Element GUI is built in and comes included with every Nutanix deployment
- Nutanix PRISM is not limited by the number of nodes it can manage
- PRISM Central is used to manage multiple Nutanix clusters centrally if required but is not mandatory.
- Nutanix provides at no cost the next generation hypervisor (AHV) which has 100% of all management performed within PRISM GUIs.
- AHV eliminates the requirement for Hypervisor licensing (e.g.: VMware vSphere) which actually reduces overall costs, this is unique to Nutanix.
- PRISM supports 4 hypervisors (ESXi , Hyper-V, AHV and XenServer) which delivers a consistent management interface for multi-hypervisor environments which are becoming more and more common.
Many of the above points are unique to Nutanix and have been designed and built to be a truly webscale platform, not a ROBO/SMB or <32 node solution. Nutanix can start small and continue to scale to any size, with the PRISM Element management stack automatically scaling to suit as nodes are added.
Return to the Dare2Compare Index:
