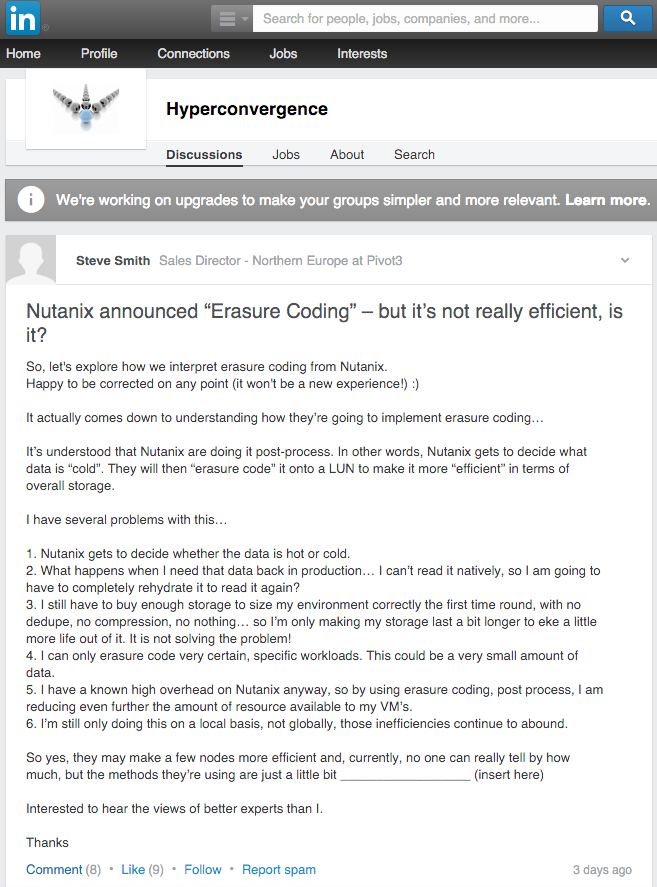
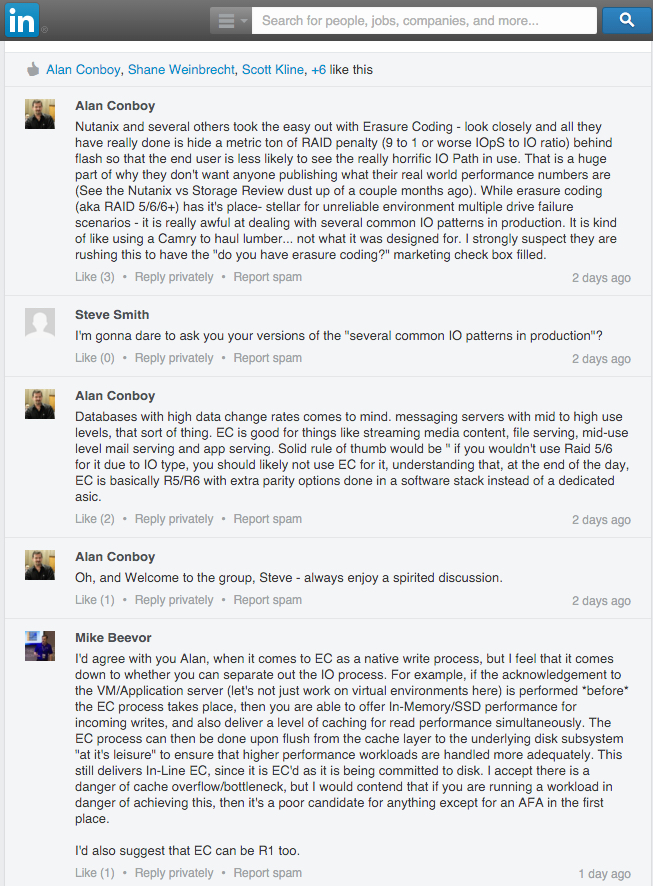
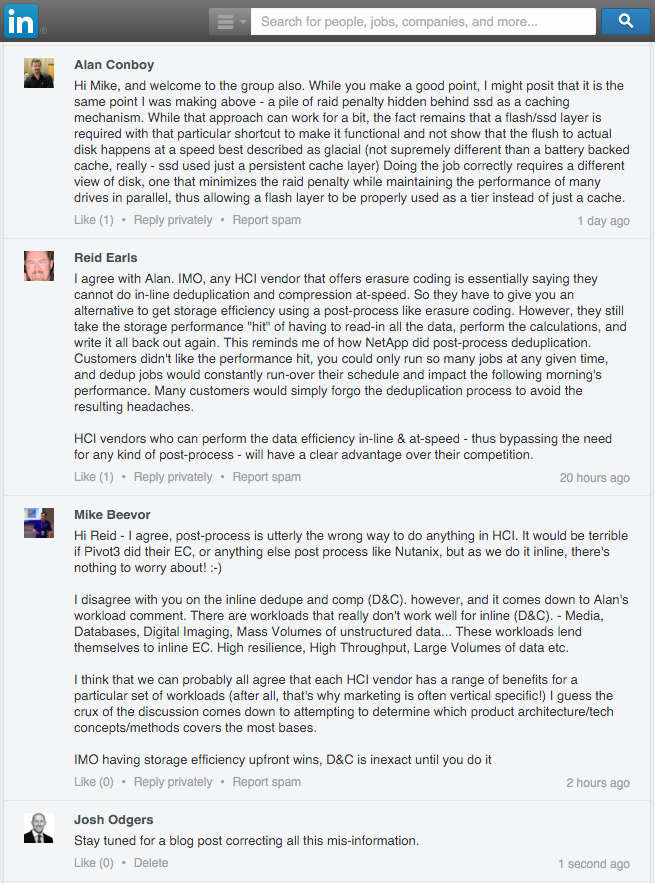
I was reading COO: VCE converged infrastructure not affected by Dell-EMC on TechTarget this morning and came across the following quote from VCE COO Todd Pavone which I found a little amusing.
One of the risks that we see in the marketplace for these appliance players is they’re trying to take that appliance that’s been architected for what I think are more single, simple, edge use cases, and they’re trying to put those into the core. We said, “Rather than trying to do that, we’re going to build an architecture for scale.” Because if you study Nutanix and <Redacted>, any of these companies that we know really well, they have scale limitations. They get to certain nodes sizes, and they break. And then, you have to cut another cluster, you have to cut another cluster.
That’s not ideal for a core data center, because now, you’re managing all of them individually — you can’t tie them into your other core systems. And so, now, you have proliferating silos, which for us is … we think that’s a big no-no. Your operational costs aren’t going to improve.
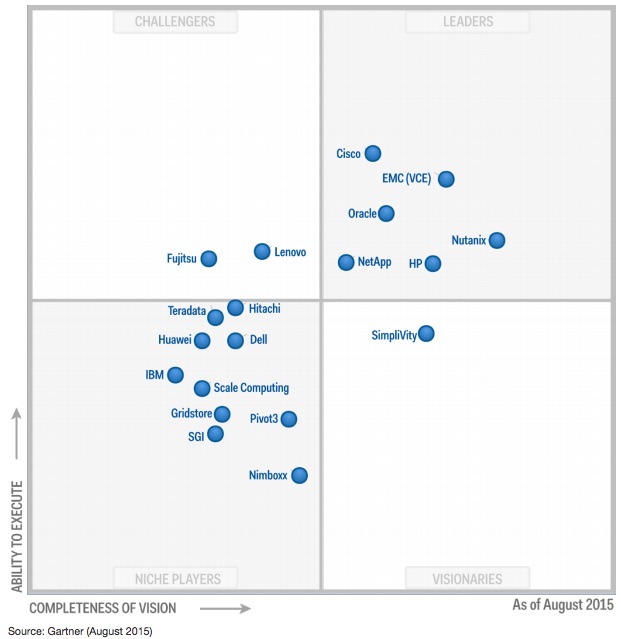
What doesn’t surprise me is how much focus Nutanix gets from other vendors, especially EMC/VCE. Its a great validation of the success of the Nutanix platform and a great indication of what will be dominant datacenter architecture (Hyperconvered/HCI) and what platform will lead the market (Nutanix XCP) in the future.
As for this post, I will only speak about Nutanix Xtreme Computing Platform (XCP) and not about the other vendor he mentioned as I don’t see the value in talking about other vendors.
The below is my summary of the points Todd has made and my thoughts:
- Todd: Nutanix has scale limitations
Josh: Nutanix has no Maximum cluster size (nodes per cluster). In fact, as the Nutanix Distributed Storage Fabric scales, the Write I/O continues to be distributed further meaning higher Write performance.
In this article (Why Nutanix Acropolis hypervisor (AHV) is the next generation hypervisor – Part 3 – Scalability) I cover all aspects of scalability including Management, Performance, Capacity, Resiliency and how scaling effects Operational aspects.
While the above post is focusing on Acropolis Hypervisor (AHV), the scalability is also true when using other supported Hypervisors such as ESXi and Hyper-V within the limitations of those hypervisors.
I wonder if Todd would say vSphere has “Scale limitations” being they support clusters of 64? Probably not, he wouldn’t want to FUD VMware.
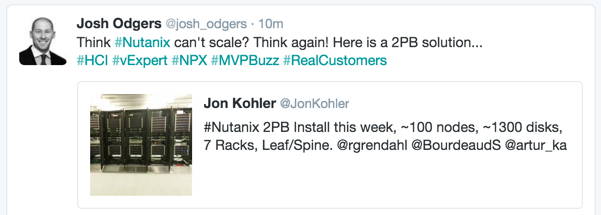
Update: Pretty timely claim by Todd when Nutanix has just delivered a >100 node, 2PB solution used for mixed workloads such as eDiscovery for Legal, High Performance SQL, MS Exchange and more.
- Todd: They get the certain node sizes and they break?
Josh: I believe Todd may have been referring to “Cluster sizes” as opposed to “Node sizes” but as he is unfamiliar with Nutanix technology he is using incorrect terminology.
The first point covers “cluster” sizing, now I’ll cover nodes sizing. Nutanix along with Dell and Lenovo has numerous different node configurations which range from one to four CPU sockets and up to 768G RAM with various SSD/HDD combinations including All-Flash.
There is not a node size maximum for the Acropolis Base Software (formally known as NOS), its simply a matter of practicality. Nutanix is a distributed platform, not a legacy monolithic centralised platform. As such, scaling out is by design to improve things like resiliency and performance.
Nutanix also recommends against scaling up as this increases the impact in the event of a single node failure. e.g.: A 3 node cluster has an impact of 33% with one node failure, but an 8 node cluster has only a 12.5% impact with one failure.
- Todd: They get to certain nodes sizes, and they break. And then, you have to cut another cluster, you have to cut another cluster.
Josh: Apart from repeating himself and using the term “node” incorrectly (again), Todd is implying Nutanix forces you to create new clusters at a given scale (which he fails to mention). As I mentioned earlier, Nutanix has no Maximum cluster size (nodes per cluster).
But as any good architect knows, there are considerations such as failure domains, security and constraints where having multiple clusters may be required or simply advantageous. One of the many great things about Nutanix XCP is multiple clusters (even with different hypervisors) can be managed centrally with PRISM central.
That brings us nicely to Todd’s next point:
- Todd: That’s not ideal for a core data center, because now, you’re managing all of them individually
Josh: This statement is the last part of the quoted section, and again Todd is talking management of “nodes” as opposed to clusters. So first point, Nutanix XCP requires 3 nodes to form a cluster and that cluster managed via PRISM Element. Where multiple clusters exist, PRISM central is then used as a single pane of glass to manage all clusters.
The below is a video showing PRISM Element for two clusters then joining them to a PRISM central instance for central management. Note: This is a fairly old video (posted September 22, 2014) as Nutanix has been doing this for a long time, as such, PRISM Element and Central have been enhanced since this was created.
Here is an example of scaling Nutanix VDI for 20K to 200K+ Power User Desktops. It is a good example showing a real world design with Management clusters and VDI clusters which takes into consideration failure domains. This also follows well proven and accepted best practices for VMware Horizon View deployments, where the scale limitations are at the vSphere/Horizon layer, not the Nutanix layer.
Summary:
This is yet another example of one vendor talking nonsense about a vendor they compete with. If its reliable information your after, speak to the vendor who makes the product/s your interested in, get them to tell you about the product then ask to speak with reference customers to validate the information you have been provided.
Competitive vendors will only focus on what they perceive to be the issues with a given competitors platform. A good vendor will focus on their product and not discuss competitors even when asked for comparisons by customers.
To quote a person I have learnt a lot from while at Nutanix, “While our competitors focus on us, We are focusing on our customers” – Dheeraj Pandey Nutanix Founder and CEO.

Fight the FUD!
Follow up posts:
- Think HCI is not an ideal way to run your mission-critical x86 workloads? Think again! Part 1
- Think HCI is not an ideal way to run your mission-critical x86 workloads? Think again! Part 2
For more information about Nutanix XCP scalability see the following posts:
1. Why Nutanix Acropolis hypervisor (AHV) is the next generation hypervisor – Part 3 – Scalability