
In response to the recent community post “Support for Exchange Databases running within VMDKs on NFS datastores” , the co-authors and I have received lots of feedback, of which the vast majority has been constructive and positive.
Of the feedback received which does not fall into the categories of constructive and positive, it appears to me as if this is as a result of the issue is not being properly understood for whatever reason/s.
So in an attempt to help clear up the issue, I will show exactly what the community post is talking about, with regards to running Exchange in a VMDK on an NFS datastore.
1. Exchange nor the Guest OS is not exposed in any way to the NFS protocol
Lets make this very clear, Windows or Exchange has NOTHING to do with NFS.
The configuration being proposed to be supported is as follows
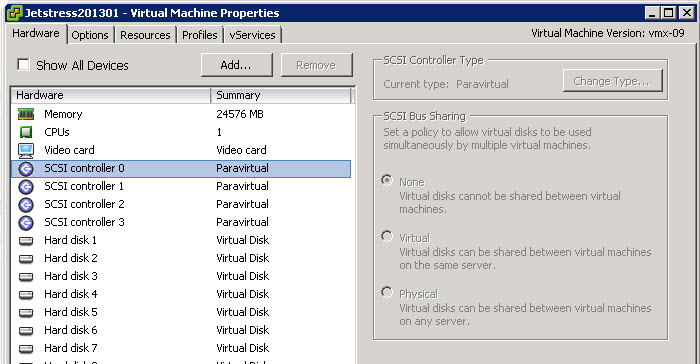
1. A vSphere Virtual Machine with a Virtual SCSI Controller
In the below screen shot from my test lab, the highlighted SCSI Controller 0 is one of 4 virtual SCSI controllers assigned to this Virtual machine. While there are other types of virtual controllers which should also be supported, Paravirtual is in my opinion the most suitable for an application such as Exchange due to its high performance and low latency.
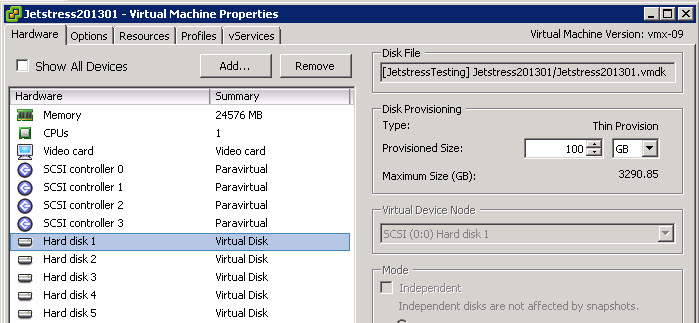
2. A Virtual SCSI disk is presented to the vSphere Virtual Machine via a Virtual SCSI Controller
The below shows a Virtual disk (or VMDK) presented to the Virtual machine. This is a SCSI device (ie: Block Storage – which is what Exchange requires)
Note: The below shows the Virtual Disk as “Thin Provisioned” but this could also be “Thick Provisioned” although this has minimal to no performance benefit with modern storage solutions.
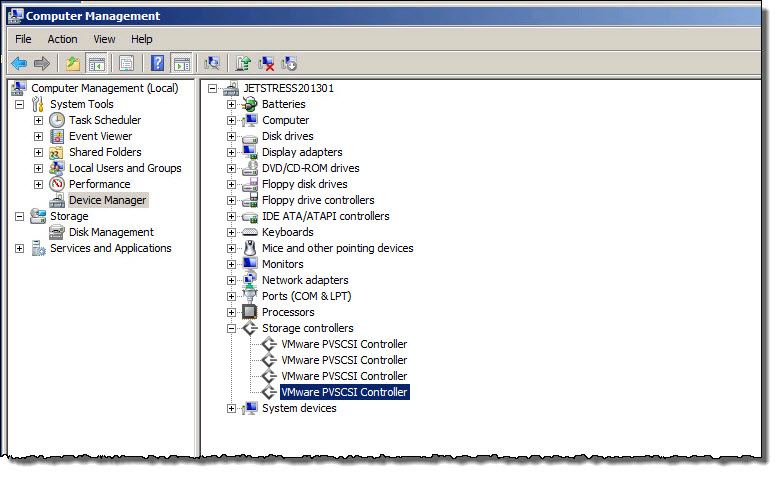
So now that we have covered what the underlying Virtual machine looks like, lets see what this presents to a Windows 2008 guest OS.
In Computer Management, under Device Manager we can see the expanded “Storage Controllers” section showing 4 “VMware PVSCSI Controllers”.
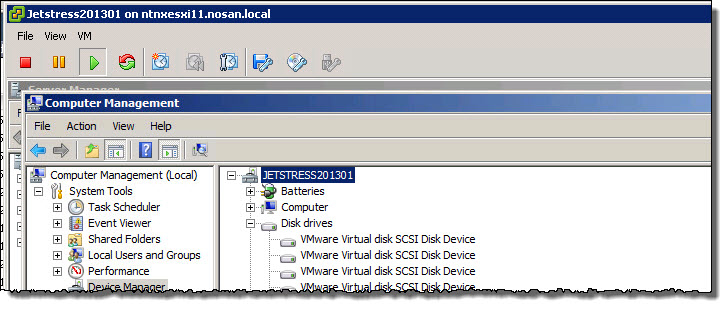
Next, still In Computer Management, under Device Manager we can see the expanded “Disk Drives” section showing a number of “VMware Virtual disk SCSI Disk Devices” which each represent a VMDK.
Next we open “My Computer” to see how the VMDKs appear.
As you can see below, the VMDKs appear as normal drive letters to Windows.
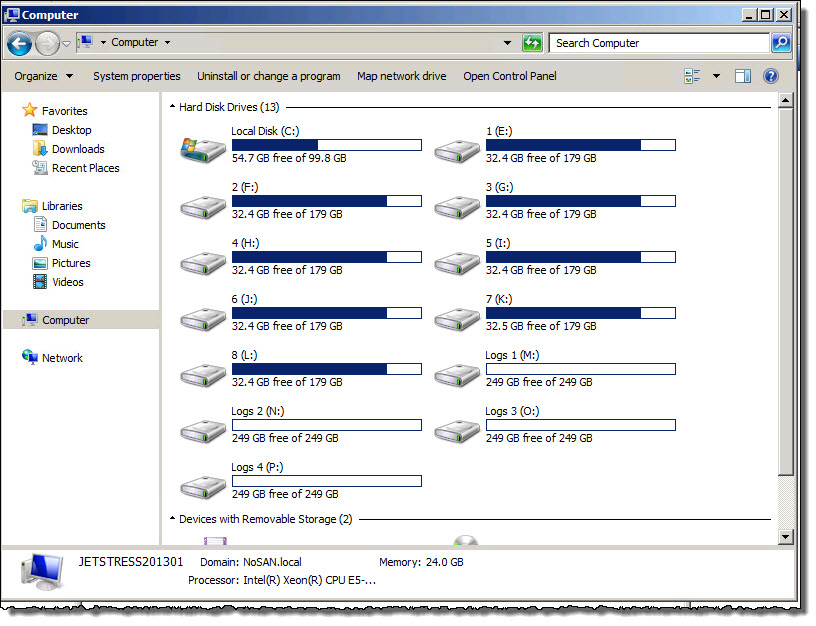
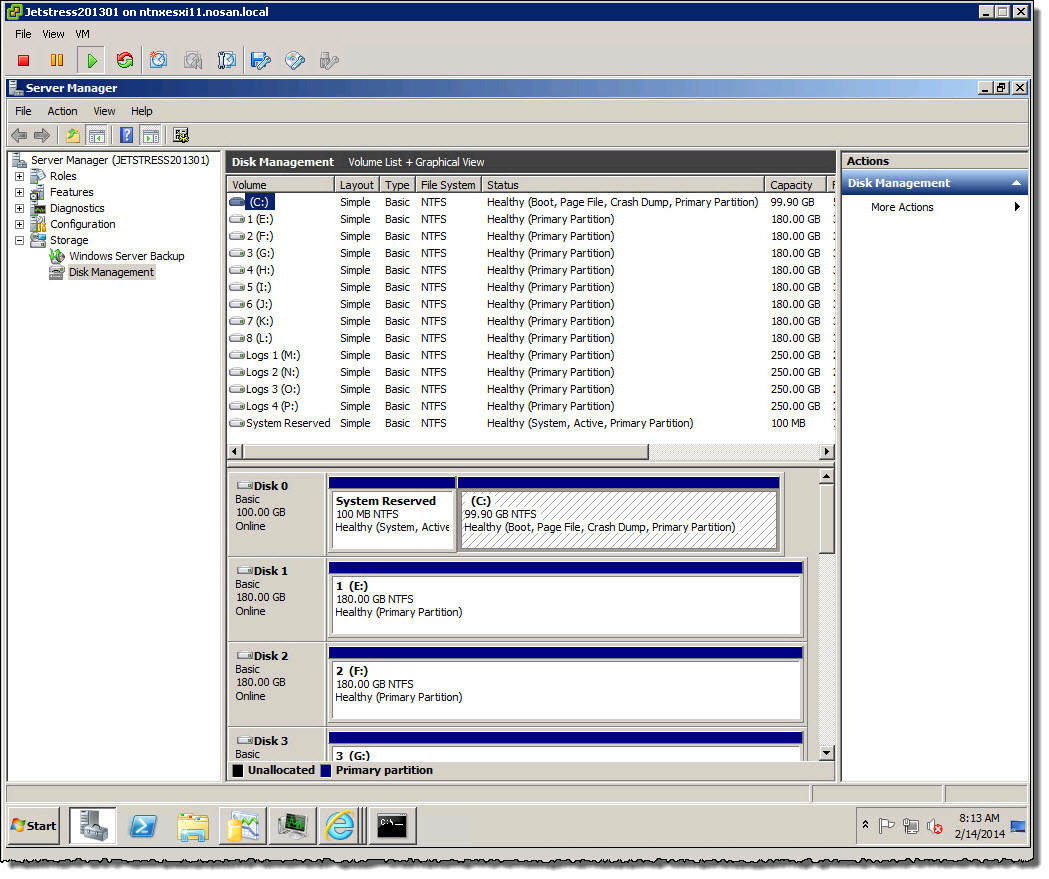
Lets dive down further, In “Server manager” we can see each of the VMDKs showing as an NTFS file system, again a Block storage device.
Looking into one of the Drives, in this case, Drive F:\, we can see the Jetstress *.EDB file is sitting inside the NTFS file system which as shown in the “Properties” window is detected as a “Local disk”.

So, we have a Virtual SCSI Controller, Virtual SCSI Disk, appearing to Windows as a local SCSI device formatted with NTFS.
So what’s the issue? Well as the community post explains, and this post shows, there isn’t one! This configuration should be supported!
The Guest OS and Exchange has access to block storage which meets all the requirements outlined my Microsoft, but for some reason, the fact the VMDK sits on a NFS datastore (shown below) people (including Microsoft it seems) mistakenly assume that Exchange is being serviced by NFS which it is NOT!

I hope this helps clear up what the community is asking for, and if anyone has any questions on the above please let me know and I will clarify.
Related Articles
1. “Support for Exchange Databases running within VMDKs on NFS datastores”
2. Microsoft Exchange Improvements Suggestions Forum – Exchange on NFS/SMB

