In the Integrity of Write I/O for VMs on NFS Datastores Series, I discussed Forced Unit Access (FUA) and Write Through in part 2 which covered a vendor agnostic view of FUA and Write through.
In this series, The goal is too explain how Nutanix can guarantee data integrity and how this is Nutanix Number #1 priority. In addition to this goal, I want to show how Nutanix supports Business Critical Applications such as MS SQL and MS Exchange which have strict storage requirements such as Write Ordering, Forced Unit Access (FUA) , SCSI abort/reset commands and to protect against Torn I/O.
Note: With Windows 2012 onwards FUA is no longer used in favour of issuing a “Flush” of the drives write cache. However this change makes no difference to Nutanix environments because regardless of FUA or a Flush being used, write I/O is not acknowledged until written to persistent media on 2 or more nodes which will be explained further later in this post.
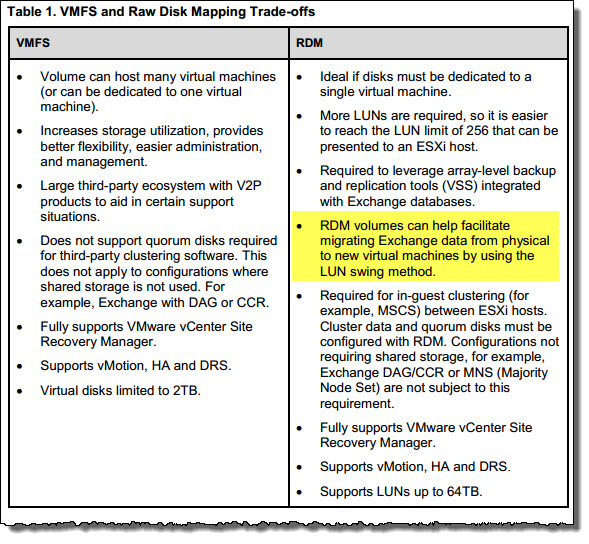
Currently MS Exchange is not supported to run in a VMDK on an NFS datastore/s although interestingly Active Directory and MS SQL servers which have the exact same storage requirements (discussed earlier) are supported. This post will show why Microsoft should allow storage vendors to certify Exchange in a VMDK on NFS datastore deployments to prove compliance with the storage requirements stated earlier.
Note: Nutanix provides support for Exchange 2010/2013 deployments in VMDKs on NFS datastores. Customers can find this support statement on http://portal.nutanix.com/ under article number 000001303.
Firstly I would like to start by stating that FUA is fully supported by VMware ESXi.
In the Microsoft article, Deploying Transactional NTFS, it states:
“The caching control mechanism used by TxF is a flag known as the Force Unit Access (FUA) function. This flag specifies that the drive should write the data to stable media storage before signaling complete.”
Nutanix meets this requirement as all writes are written to persistent media (SSD) on at least two independent nodes and no write caching is performed at any layer including the Nutanix Controller CM (CVM), Physical Storage Controller card or the physical drives themselves.
For more information on how Nutanix is compliant with this requirement click here.
The article also states:
“Some Host Bus Adapters (HBAs) and storage controllers (for example, RAID systems) have built-in battery-backed caches. Because these devices preserve cached data if a power fault occurs, any disks connected to them are not required to honor the FUA flag. Further, a disk whose power supply is protected by an uninterruptable power supply (UPS) does not need to honor the FUA flag. This is because the UPS will maintain power long enough for the disk to flush its cache to the media.”
As discussed with the previous requirement, Nutanix meets this requirement as the write acknowledgement is not given until writes are successfully commited to persistent storage on at least two nodes. As a result, even without a UPS, data integrity can be guaranteed in a Nutanix environment.
For more information on how Nutanix is compliant with this requirement click here.
Another key point in the article is:
“Disabling a drive’s write cache eliminates the requirement for the drive to honor the FUA flag.”
All physical drives (SSD and SATA) in a Nutanix nodes have their write cache disabled, therefore removing the requirement of FUA.
The article concludes with the following:
“Note For TxF to be capable of consistently protecting your data’s integrity through power faults, the system must satisfy at least one of the following criteria:
1. Use server-class disks (SCSI, Fiber Channel)
2. Make sure the disks are connected to a battery-backed caching HBA.
3. Use a storage controller (for example, RAID system) as the storage device.
4. Ensure power to the disk is protected by a UPS.
5. Ensure that the disk’s write caching feature is disabled.”
We have already discussed because Nutanix does not use a non persistent write cache there is no requirement for the OS to issue the FUA flag or the Flush command in Windows 2012 to ensure data is written to persistent media. But for fun lets see how many of the above Nutanix is compliant with.
1. YES – Nutanix uses enterprise grade Intel S3700 SSDs for all write I/O
2. N/A – There is no need for battery backed caching HBAs due to Nutanix write acknowledgement not being given until written to persistent media on two or more nodes
3. YES – Nutanix Distributed File System (NDFS) with Resiliency Factor (RF) 2 or 3
4. Recommended to ensure system uptime but not required to ensure data integrity as writes are not acknowledged until written to persistent media on two or more nodes
5. YES – All write caching features are disabled on all SSDs/HDDs
So to meet Microsoft’s FUA requirements, only one of the above is required. Nutanix meets 3 out of 5 outright, with a 4th being Recommended (but not required) and the final requirement not being applicable.
Write Cache and Write Acknowledgements.
Nutanix does not use a non persistent write cache, period.
When a I/O is issued in a Nutanix environment, if it is Random, it will be sent to the “OpLog” which is a persistent write buffer stored on SSD.
If the I/O is sequential, it is sent straight to the Extent Store which is persistent data storage, also located on SSD.
Both Random and Sequential I/O flows are shown in the below diagram from The Nutanix Bible by @StevenPoitras.

All Writes are also protected by Resiliency Factor (RF) of 2 or 3, meaning 2 or 3 copies of the data are synchronously replicated to other Nutanix nodes within the cluster prior to the write being acknowledged.
To be clear, Write acknowledgements are NOT sent until the data is written to 2 or 3 nodes OpLog or Extent Store (depending on the configured RF). What this means is the requirement for Forced Unit Access (FUA) is achieved as every write is written to persistent media before write acknowledgements are sent regardless of FUA (or Flush) being issued by the OS.
Importantly, this write acknowledgement process is the same regardless of the storage protocol (iSCSI , NFS , SMB 3.0) used to present storage to the hypervisor (ESXi , Hyper-V or KVM).
As Nutanix does not use a non persistent write cache, and does not acknowledge writes until written to persistent media on 2 or 3 nodes, that’s the end of the problem right?
Not really, as physical drives also have write caches and in the event of a power failure, its possible (albeit unlikely) data in the cache may not be written to disk even after a write acknowledgement is written.
This is why all physical SSD / SATA drives in a Nutanix environment have the disks write caching feature disabled.
This ensures there is no dependency on Uninterruptable power supplies (UPS) to ensure data is successfully written to the disk in the event of a power failure.
This means Nutanix is compliant with the “Ensure that the disk’s write caching feature is disabled” requirement specified by Microsoft.
Uninterruptible Power Supplies (UPS)
As non persistent write caching is not used either at the Nutanix Controller VM (CVM), Physical Storage Controller OR the physical SSDs/HDDs, the use of a UPS is not a requirement for a Nutanix environment to ensure data integrity, however it is still recommended to use a suitable UPS to ensure uptime of the environment. Assuming a power outage is not catastrophic (e.g.: For a single node) and the cluster is still online, write acknowledgements are still not given until data is written to the configured RF policy as Nutanix nodes are effectively stateless.
The Microsoft article quoted earlier states:
“Further, a disk whose power supply is protected by an uninterruptable power supply (UPS) does not need to honor the FUA flag. This is because the UPS will maintain power long enough for the disk to flush its cache to the media.”
Even in the case a storage solution or disk is protected by a UPS, it requires sufficient time to allow all data in the cache to be written to persistent media. This is a potential risk to data consistency as a UPS is just another link in the chain which can go wrong. This is why Nutanix does not depend on UPS for data integrity.
Another Microsoft Article, Key factors to consider when evaluating third-party file cache systems with SQL Server gives two examples of how data corruption can occur:
“Example 1: Data loss and physical or logical corruption”
“Example 2: Suspect database”
So how does Nutanix protect against these issues?
The article states
“How to configure a product providing file cache from something like non-battery backed cache is specific to the vendor implementation. A few rules, however, can be applied:
1. All writes must be completed in or on stable media before the cache indicates to the operating system that the I/O is finished.
2. Data can be cached as long as a read request serviced from the cache returns the same image as located in or on stable media.”
Regarding the first point: All write I/O is written to persistent media (as is the intention of FUA) as described earlier in this article.
For the second point, the Nutanix Distributed File System (NDFS) read I/O can happen from one of the following places:
- “Extent Cache”, located in RAM.
- “Content Cache”, located on SSD as per earlier diagram.
- “Oplog”, the persistent write cache located on SSD as per earlier diagram.
- “Extent store” located on either SSD or SATA depending on if the data is “Hot” or ‘Cold”.
- A remote nodes Extent Cache, Content Cache, OpLog or Extent Store
To ensure the Extent Cache (in RAM) is consistent with the Content Cache or Extent Store located on the persistent media, when a write I/O occurs which modifies data which has been cached in the Extent Cache (in RAM), the corresponding data is discarded from the Extent Cache and only promoted back to the Extent Cache if the data profile remains Hot (i.e.: Frequently accessed).
In Summary:
The Nutanix write path guarantees (even without the use of a UPS) writes are written to persistent media and have at least 1 redundant copy on another node in the cluster for resiliency before acknowledging the I/O back to the hypervisor and onto the guest. This is critical to ensuring data consistency/resiliency.
This is in full compliance with the storage requirements of applications such as SQL, Exchange and Active Directory.
——————————————————–
Integrity of Write I/O for VMs on NFS Datastores Series
Part 1 – Emulation of the SCSI Protocol
Part 2 – Forced Unit Access (FUA) & Write Through
Part 3 – Write Ordering
Part 4 – Torn Writes
Part 5 – Data Corruption
Nutanix Specific Articles
Part 6 – Emulation of the SCSI Protocol (Coming soon)
Part 7 – Forced Unit Access (FUA) & Write Through
Part 8 – Write Ordering (Coming soon)
Part 9 – Torn I/O Protection (Coming soon)
Part 10 – Data Corruption (Coming soon)
Related Articles
1. What does Exchange running in a VMDK on NFS datastore look like to the Guest OS?
2. Support for Exchange Databases running within VMDKs on NFS datastores (TechNet)
3. Microsoft Exchange Improvements Suggestions Forum – Exchange on NFS/SMB
4. Virtualizing Exchange on vSphere with NFS backed storage