Every now and again you will see one vendor put out information/statements about other vendors technology. 9 times out of 10 its either outdated , incorrect or a deliberate attempt to spread Fear Uncertainty and Doubt (FUD).
Today I discovered something on LinkedIn I thought I would respond too, especially as it was mostly by two sales guys (One Sales Engineer & One Sales Director) from one vendor and two other individuals from other vendors trying to spread FUD.
Two of these vendors according to Gartner, are niche players and the other vendor didn’t even make the quadrant shown below.
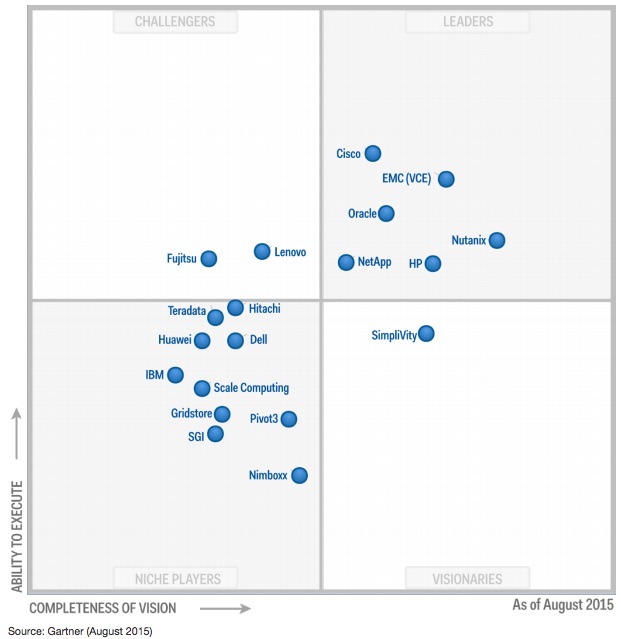
Had the sales director simple googled Nutanix Erasure Coding he would have found the following articles which covers all of his questions and provides links to further articles on the topic. But hey, doing that would prevent him being able to spread FUD.
Nutanix – Erasure Coding (EC-X) Deep Dive
The above article refers to the below article which explains what data Nutanix EC-X will take effect on and discussed performance impact.
What I/O will Nutanix Erasure coding (EC-X) take effect on?
But let’s quickly address each point and correct the mis-information:
The “problems” the sales director has with the technical implementation of Nutanix EC-X are as follows, I will respond in-line.
-
Nutanix gets to decide if the data is hot or cold.
Not sure how this is a problem, would he prefer customers have to manually select data to be considered cold? I think the distributed file system tracking what data hasn’t been written too is a very simple, accurate and totally automated way to decide what data to apply . After all Nutanix is making infrastructure invisible, so yes, We’ll put the engineering work in so the customers can just wear the Nutanix grin. (sorry that was cheesy!)
-
What happens when I need that data back in production…. I can’t read it natively, so I am going to have to completely rehydrate it to read it again?
EC-X does not remove the data from production! Data which has EC-X applied is not moved to a LUN (lol!). Data remains accessible in the same way it was prior to EC-X taking effect. On read I/O data is not rehydrated, EC-X is simply a more space efficient method of storing data while proving resiliency of N+1 or N+2. EC-X and RF are applied on the same container so the data is not moved when EC-X is applied.
-
I still have to buy enough storage to size my environment correctly the first time around, with no dedupe,no compression, no nothing… so I’m only making my storage last a bit longer to eke a little more life out of it. It is not solving the problem!
Firstly, without stating what “the problem” is, the statement has no context and is pointless FUD. However I can confirm EC-X works in addition to compression & dedupe both of which can be in-line or post process. All three data reduction technologies also apply to both the SSD and SATA tiers, just to get in-front of any future FUD.
Nutanix recommends customers start small and scale as required since our platform scales so gracefully, but if a customer wants to size for 3-5 years up front (we would help them avoid this BTW) we make assumptions (like every vendor, BTW) as to typical data reduction savings based on the information we have about the customer workload, and size with suitable capacity for at least N+1 to enable fully automated self healing from a node failure.
-
I can only erasure code very certain, specific workloads. This could be a very small amount of data.
Nutanix EC-X can apply to ANY data stored on the Nutanix Distributed Storage Fabric. As per the Deep Dive post (which this guy clearly didn’t read), Nutanix chooses to apply EC-X to data which is write cold for 60 mins to avoid the inefficiencies of striping data across nodes then having to re-stripe it shortly after following a subsequent write I/O. RF2 (or RF3) is more efficient for write intensive workloads and because Nutanix understands this, we only apply EC-X to non write intensive I/O.
-
I have a known high overhead on Nutanix anyway, so by using erasure coding, post process, I am reducing even further the amount of resources available to VMs.
Another baseless statement, But lets talk about the amount of resources available to VMs. The CVM size does not increase when EC-X is enabled, and the fact EC-X increases the effective capacity of the SSD tier, it means more data can be served out of SSD. What this results in is lower latency for a larger working set which REDUCES the CPU WAIT for the CVM and for all VMs performing I/O. Less data being stored (up to 2x less with RF3) means less metadata needs to be maintained, so the overheads on the CVM in many ways are reduced.
If Erasure Coding is applied in-line (which BTW Nutanix can do with a simple toggle of a setting, but chooses not too), it means that for write intensive workloads, stripes need to be recalculated frequently which is a high CPU overhead compared to, in Nutanix case RF2 or RF3.
Oh did I mention with EC-X the parity data is stored in the SATA tier, freeing up the SSD tier for even more data to be served with flash performance, this is another example of the increased efficiencies when using EC-X.
-
I’m still only doing this on a local basis, not globally, those inefficiencies continue to abound.
Ah, just plain wrong! EC-X is applied globally across the entire cluster with only one part of any EC-X stripe per node, ensuring maximum efficiency & resiliency.
Now to reply to one of the funnier comments:
-
I agree with Alan. IMO, any HCI vendor that offers erasure coding is essentially saying they cannot do in-line deduplication and compression at-speed. So they have to give you an alternative to get storage efficiency using a post-process like erasure coding. However, they still take the storage performance “hit” of having to read-in all the data, perform the calculations, and write it all back out again. This reminds me of how NetApp did post-process deduplication. Customers didn’t like the performance hit, you could only run so many jobs at any given time, and dedup jobs would constantly run-over their schedule and impact the following morning’s performance. Many customers would simply forgo the deduplication process to avoid the resulting headaches.HCI vendors who can perform the data efficiency in-line & at-speed – thus bypassing the need for any kind of post-process – will have a clear advantage over their competition.
So this guy is also saying In-line is best for Erasure Coding as well as dedupe and compression. Well since Nutanix can and does in many cases recommend In-Line dedupe and compression its a bit of a moot point?
Erasure Coding on the other hand, I believe post process based on I/O profile is a more efficient way, as described in What I/O will Nutanix Erasure coding (EC-X) take effect on?
Sure there is an overhead of doing post process, but there is also an overhead on doing in-line which this guy seems to be forgetting. The overhead of in-line is 100% of the I/O suffers the overhead (since its in-line), with post-process applied only to suitable data (being write cold data) the overhead only applies to write cold data, which dramatically reduces the overheads because only the most suitable data for EC-X get processed.
If a customer had 100% Write Once Read Many data, In-line would be more efficient, and Nutanix would configure EC-X in-line. If however data is write hot for the business day, then becomes cold and read only overnight, post process would be orders of magnitude more efficient as the stripes would only be calculated once, as opposed to “N” times depending on how write intensive the data was during he day.
Long story short, In-line and Post-Process both have their use cases, in my experience, most production workloads suit post process erasure coding which is why Nutanix default is post process for write cold data >60mins.
Comparing Nutanix, a HCI distributed platform to Netapp which is a centralised non HCI filer is a bit ridiculous as what does/doesn’t work well for Netapp has nothing to do with Nutanix.
Summary:
The methods the Sales Director is using to spread completely incorrect information in an attempt to create FUD are just a little bit __________ (insert here).
I’d recommend customers/prospects ignore any comments from any vendor being made about another vendor period. If a vendor is spending there time talking about another vendor, politely ask them to leave and invite the vendor being spoken about to come and present as that technology is probably pretty good if other vendors feel the need to talk about it!
For the record, as the LinkedIn thread may “disappear” as a result of this post, the screen shots are below: