Following on from Part 1, this post will discuss hyper-converged Distributed File Systems (i.e,: Nutanix) and compare with traditional SAN/NAS RAID and hyper-converged solutions using Object storage for data protection.
The below diagram shows a 4 node hyper-converged solution using a Distributed File System with the same 4 x 4TB SATA drives with data protection using replication with 2 copies. (Nutanix calls this Resiliency Factor 2)
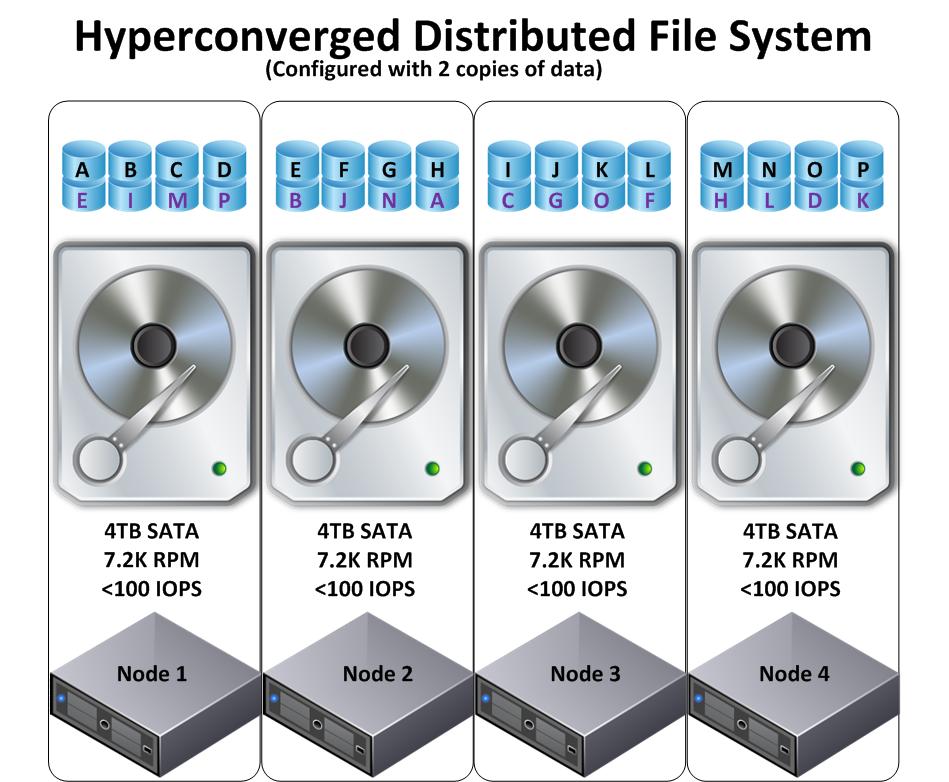
The first difference you may have noticed, is the data is much more granular than the Hyper-Converged Object store example in Part 1.
The second less obvious difference is the replicated copies of the data (i.e.: The data with Purple letters) on node 1 do not reside on a single other node, but are distributed throughout the cluster.
Now lets look at a drive failure example:
Here we see Node 1 has lost a Drive hosting 8 granular pieces of data 1MB in size each.

Now the Distributed File System detects that the data represented by A,B,C,D,E,I,M,P has only a single copy within the cluster and starts the restoration process.
Lets walk through each step although these steps are completed concurrently.
1. Data “A” is replicated from Node 2 to Node 3
2. Data “B” is replicated from Node 2 to Node 4
3. Data “C” is replicated from Node 3 to Node 2
4. Data “D” is replicated from Node 4 to Node 2
5. Data “E” is replicated from Node 2 to Node 4
6. Data “I” is replicated from Node 3 to Node 2
7. Data “M” is replicated from Node 4 to Node 3
8. Data “P” is replicated from Node 4 to Node 3
Now the cluster has restored resiliency.
So what was the impact on each node?
The above table shows a simplified representation of the workload of restoring resiliency to the cluster. As we can see, the workload (being 8 granular pieces of data being replicated) was distributed across the nodes very evenly.
Next lets look at the advantages of a Hyper-Converged Solution with a Distributed File System (which Nutanix uses).
- Highly granular distribution using 1MB extents not large Objects.
- The work required to restore resiliency after one drive (or node) failure was distributed across all drives and nodes in the Cluster leveraging all drives/nodes capability. (i.e.: Not constrained to the <100 IOPS of a single drive)
- The restoration rebuild is a low impact activity as the workload is distributed across the cluster and not dependant on source/destination pair of drives or nodes
- The rebuild has a low impact on the virtual machines running on the distributed file system and consistent performance is maintained.
- The larger the cluster the quicker and lower impact the rebuild is as the workload is distributed across a higher number of drives/nodes for the same size (Gb) worth of restoration.
- With Nutanix SSDs are used not only for Read/Write cache but as a persistent storage tier, meaning the recovering data will be written to SSD and where the data being recovered is not in cache (Memory or SSD tiers) it is still possible the data will be in the persistent SSD tier which will dramatically improve the performance of the recovery.
Summary:
As discussed in Part 1, Traditional RAID used by SAN/NAS and Hyper-converged solutions using Object based storage both suffer similar issues when recovering from drive or node failure.
Where as Nutanix Hyper-converged solution using the Nutanix Distributed File System (NDFS) can restore resiliency following a drive or node failure faster and with lower impact thanks to its highly granular and distributed architecture, meaning more consistent performance for virtual machines.