Virtualization and Storage always seem to be a hot topics in regards to Exchange deployments and many of you would have seen my post Virtualizing Exchange on vSphere with NFS backed storage a while back.
This post was motivated by a tweet from fellow VCDX which stated:
#XtremIO dedupe not supported for Exchange, no we can’t turn it off.
Later in the twitter conversation he went on to say
To be clear not an MS employee, another integrator MS “master” certified. It’s the whole NFS thing again
I have heard similar over the years and for me the disappointing thing is the support statement is unclear as are the motivations behind support statements for Exchange in general. e.g.: Support for VMDK on NFS
The only support statement I am aware of regarding Exchange and deduplication is in the technet article “Exchange 2013 storage configuration options” under the section “Volume configurations for the Exchange 2013 Mailbox server role” at it states:

In the above statement which specifically refers to “a new technique to optimize storage utilization for Windows Server 2012” is states that for Stand-alone or High availability solutions de-duplication is not supported for Exchange database file unless the DB files are completely offline and used for backup or archives.
So the first question is “Is array level deduplication supported”?
There is nothing that says that it isn’t supported that I am aware of, so if you are aware of such a statement please let me know in the comments and I will update this post.
My interpretation of the support statement is that array level deduplication is supported and MS have simply called out that the deduplication in Windows 2012 is not. Regardless of if you agree or disagree with my interpretation, I think its safe to say the support statement should be clarified with justification.
The next question I would like to discuss is “Should deduplication be used with Exchange”?
Firstly we should discuss the fact Exchange can be deployed with Database Availability Groups (DAGs) which creates multiple copies of Exchange databases across up to 16 Exchange Mailbox (or Multi-Role) servers.
The purpose of a DAG is to provide high availability for the application and data.
So if the application is by design making duplicate copies, should the storage be undoing this work?
Before I give my opinion on deduplicating DAG copies, I want to be clear on two things:
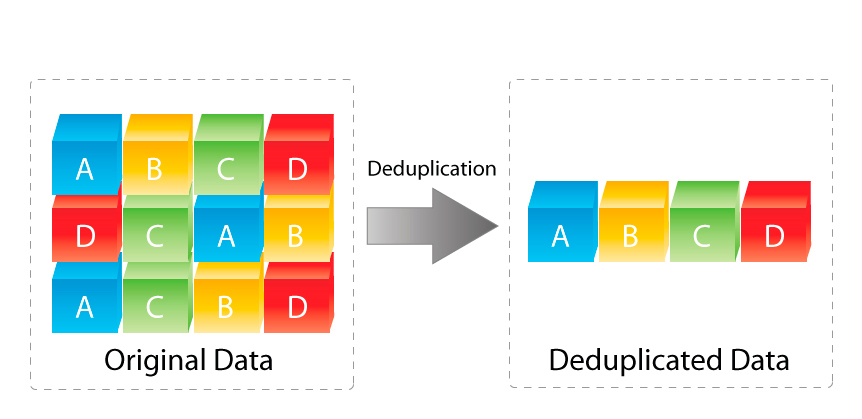
1. Deduplication is a well proven technology which many different vendors implement either in-line or post process or in some cases both.
2. As array level deduplication is abstracted from the Guest OS and Application, there is no risk to the application such as data corruption or anything like that.
So back to deduplicating DAG copies.
I work for Nutanix and I wrote our best practice guide for Exchange which can be found below. In the guide, I recommended Compression but not deduplication. In an upcoming update of the document the recommendation remains to use compression but adds a further recommendation to use Erasure coding (EC-X) for data reduction.
Nutanix Best Practices Guide: Virtualizing Microsoft Exchange on Web-Scale Converged Infrastructure.
The reason for these recommendations is three fold:
1. Compression + EC-X give excellent data reduction savings for Exchange which generally result in usable capacity higher than RAW capacity while still providing data protection at the storage layer.
2. Deduplicating data which is deliberately written multiple times is a huge overhead on any infrastructure as data is still processed multiple times by the Guest OS, Storage Network and storage controller even if deplicate copies are not written to disk. To be clear, the Guest OS (CPU) and Storage network overhead are not eliminated by dedupe.
3. Nutanix recommends the use of hybrid nodes for Exchange with a small percentage of capacity provided by SSD (for all write I/O and hot data) and a large percentage of capacity provided by SATA. As a result the bulk of the data is stored on low cost SATA so the commercial benefit ($ per GB) of deduplication is minimal especially after compression and EC-X.
In my opinion deduplicating everything regardless of its profile is not the answer, so data reduction such as deduplication, compression and Erasure Coding should be able to be turned off for workloads which give minimal benefit.
For Exchange DAGs, deduplication should give excellent data reduction results in line with the number of DAG copies. So if an Exchange DAG has 4 copies, then approx 4:1 data reduction should be achieved right off the bat. Now this sounds great but when running a DAG on highly available shared storage (SAN/NAS/HCI) it is unnessasary to have 4 copies of data.
In reality, I recommend 2 copies when running on Nutanix because the shared storage provided by Nutanix keeps at least 1 additional copy (if using EC-X) or where using RF2 or RF3, 2 or 3 copies of data meaning in the event of a drive or node failure, the data is still available to the application without requiring a DAG failover. Similar is true when running Exchange on SAN/NAS/HCI solutions with some form of RAID or replication for data protection.
So the benefit of deduplication would therefore reduce to from possibly 4:1 down to 2:1 because only 2 DAG copies are really required if the storage is highly available.
Considering the data reduction from compression and storage solutions supporting Erasure Coding, I think deduplication is only commercially viable/required when using expensive all flash storage which lets face it, is not required for Exchange.
If you have chosen an all flash solution and you want to run all workloads on it and eliminate having silos of infrastructure for different workloads, then by all means deduplicate Exchange DAGs otherwise it will be a super expensive solution. But, in my opinion hybrid is still the best solution overall with the only real advantage of all flash being potentially higher and more consistent performance depending on many factors.
Summary:
I hope that Microsoft clarify their position regarding support for array level data reduction technologies including deduplication with detailed justifications.
I would be disappointed to see Microsoft come out and update the support policy stating deduplication (for array’s) is not supported as there is not technical reason it should not be supported (Happy to be corrected if credible evidence can be provided) regardless of if you think its a good idea or not.
Having worked in the storage industry for a long time, I have seen many different deduplication solutions used successfully with MS Exchange and I am yet to see any evidence that it is not a totally viable and enterprise grade option for Exchange databases.
The question which remains is, do you need to deduplicate Exchange databases? – My thinking is only where your using all flash systems and need to lower cost per GB.
My position being the better solution would be choose a hybrid solution when eliminating silos which gives you the best of all worlds and applications requiring all flash can have all flash and other workloads can use flash for hot data and lower cost SATA for cold storage or data which doesn’t require SSD (like Exchange).