In Part 1 of this series, we discussed how Nutanix “Extent Cache” dramatically improves read performance in not only Horizon View environments, but all Virtual machines.
In Part 2, we will discuss how Nutanix further enhances Horizon View performance using a Nutanix feature which is known as “Shadow Clone”.
So the first question is “What is a Shadow Clone” and “How does it improve performance”?
To answer this question, lets first discuss the issue.
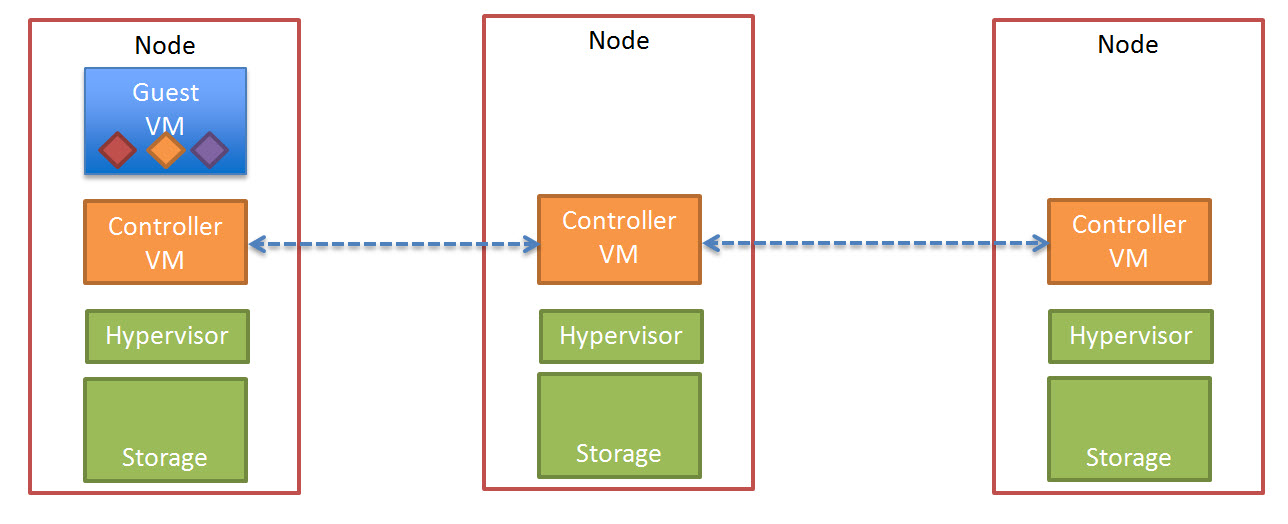
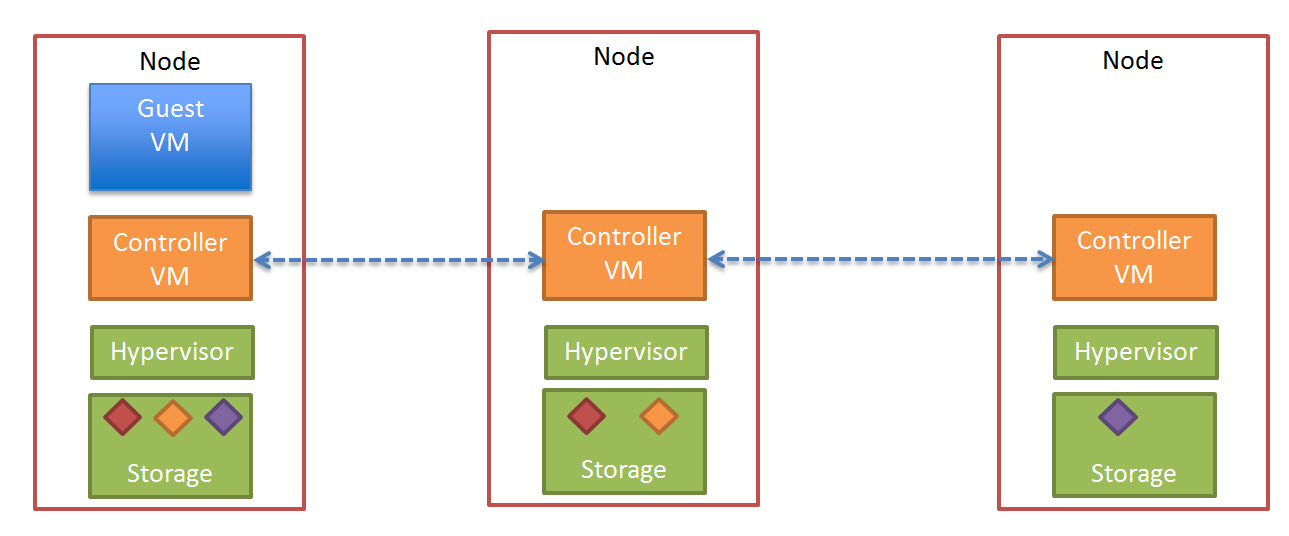
All the Linked Clones in a desktop pool access a shared “replica” disk. This creates large amounts of read I/O to the shared storage.
The below diagram shows what this looks like in a traditional storage architecture.

So when a Virtual Desktop in a Desktop Pool using Linked Clones needs to read data it has to exit the ESXi host, traverse the Storage Network, go via a Storage Controller and access the “replica” from either disk or cache.
As we discussed in Part 1, VMware have helped address this problem with CBRC, but not all the replica can fit within the CBRC which is limited to 2GB,.
Enter Nutanix with “Extent Cache” and the size of the Extent cache can be configured to any size thus ensuring the maximum amount of the “replica” can be served via Cache. So why do we need “Shadow Clones”?
The only issue with Extent Cache is that it is RAM assigned to the CVM, so the bigger the Extent Cache, the more RAM is being used on the ESXi host, so you want to aim for a balance between Cache capacity (and therefore % of cache hits) and Virtual Machine consolidation ratio on the ESXi host.
Enter Shadow Clones and we have the best of both worlds, 100% of the replica Read I/O will be served locally, via either Extent Cache or Shadow Clones.
Show how does “Shadow Clones” work?
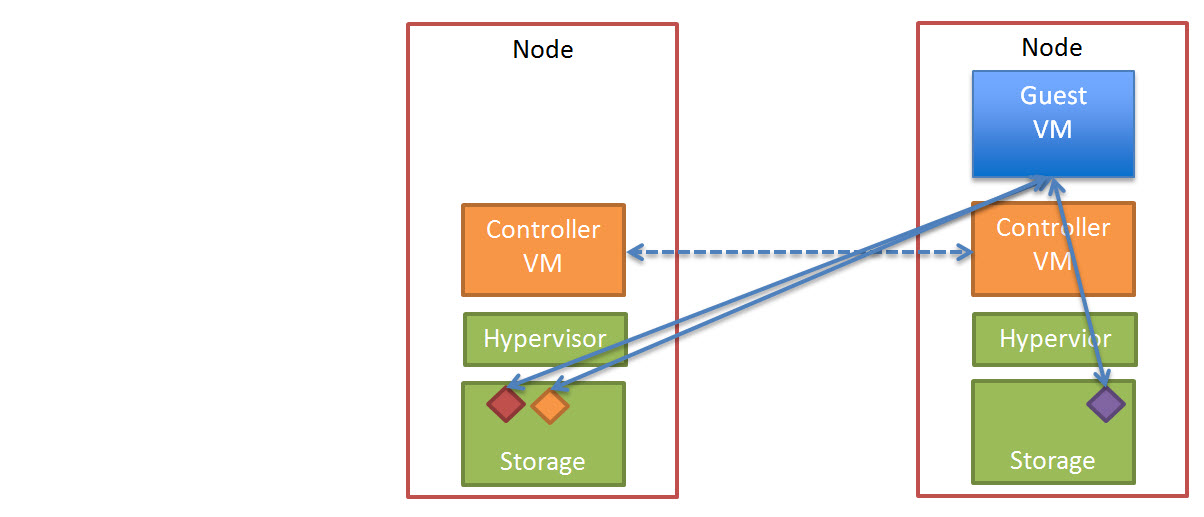
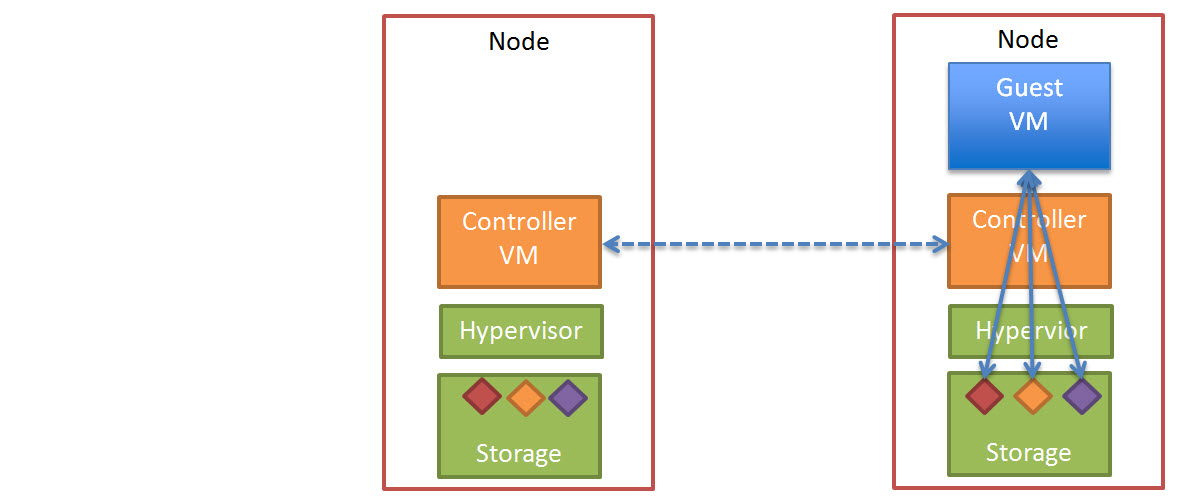
What it does is intelligently analyse the I/O access pattern at the storage layer to identify what files are a shared read only disk (ie: Linked Clone Replica).
When a 100% read only disk is discovered, Nutanix will take a snapshot at the storage layer on each Controller VM (CVM) and redirect all read I/O to the local copy.
The below diagram shows what Shadow Clones looks like

The above is a dramatically simpler and more scalable solution than tradition architecture, as the solution will scale indefinitely without degrading performance.
Some of the benefits of Nutanix Shadow Clones are
1. Replica data is always served locally ot the ESXi host (via Extent Cache and Shadow Clones)
2. Does not require the use of CBRC and is not limited to 2GB
3. Reduced overhead on the Storage Network (IP Network) as read I/O is serviced locally
4. During boot storms, login storms and antivirus scans all replica data can be served locally and NO read I/O is forced to be served by a single storage controller. This not only improves Read performance but makes more I/O available for Write operations which are generally >=65% in VDI environments
6. The solution can scale while maintaining linear performance (Performance does not taper off at scale)
7. When the base image is updated, Nutanix detects the file has been written to an automatically creates a new snapshot which is replicated out to all nodes.
8. Feature is enabled once and does not require ongoing configuration or maintenance
Back to Part 1
A special Thank you to Jason Langone VCDX#54 (@langonej) for reviewing this post and Tabrez Memon one of the brilliant Engineers at Nutanix who has worked on features discussed in this post and provided valuable input into this series.