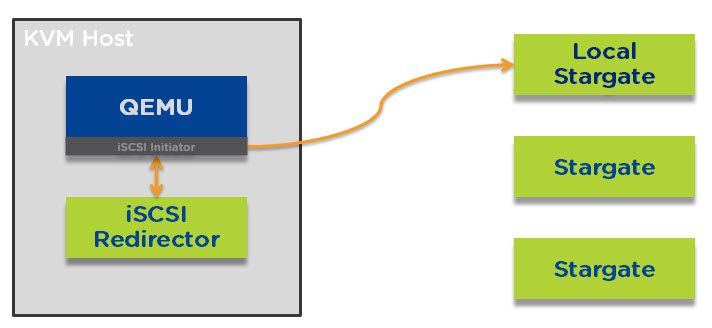
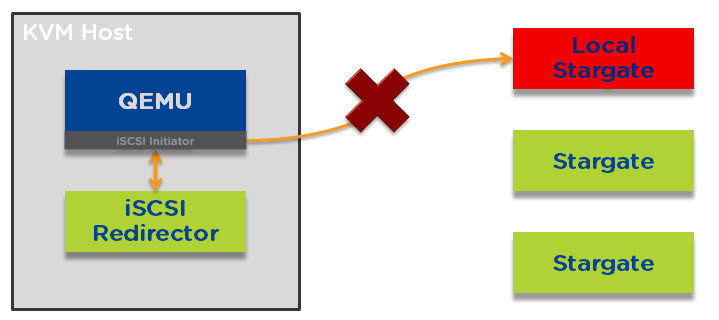
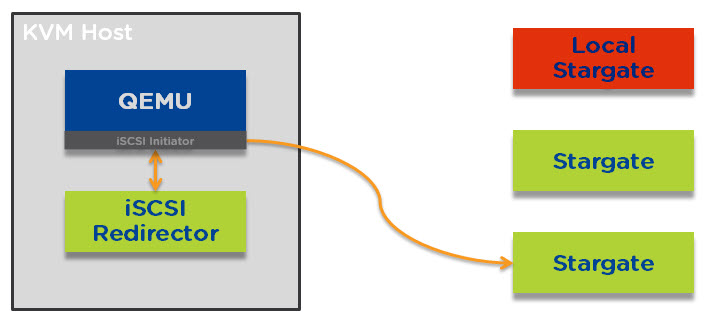
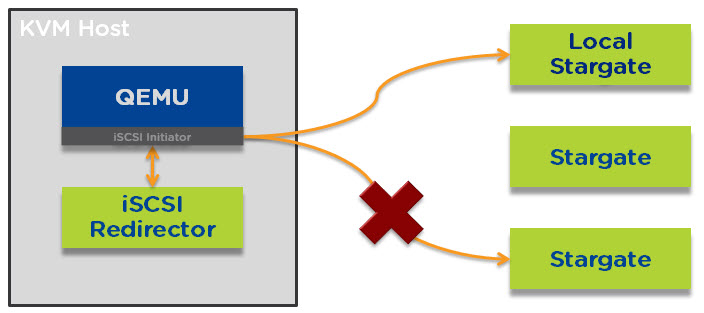
I have had several prospective and existing customers say how much they like the One Click upgrade PRISM provides for NOS, Hypervisor’s, Firmware and NCC. These customers typically also ask questions about what happens if they perform a One Click upgrade and the cluster is for any reason degraded such as from a drive, node, block failure.
Before starting a One Click upgrade, NOS always performs Pre-Upgrade checks to ensure the cluster is healthy. In the event the cluster is not fully resilient the upgrade process will be aborted as shown below:
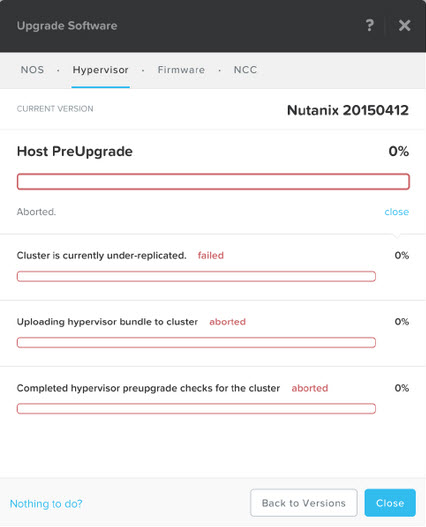
In the above case, the cause of the cluster being “under-replicated” (meaning the configured Resiliency Factor of 2 or 3 was not in compliance) was due to the fact NOS had just be upgraded on the cluster and one of the nodes had not yet come back online when the One Click Upgrade for the Acropolis hypervisor (AHV) was started.
Other situations where the cluster may be under replication is following a HDD, SSD, Node or Block failure. In all these cases, the Nutanix Distributed File System (NDFS) will restore resiliency assuming sufficient rebuilt capacity is available in the Storage Pool. This is why Nutanix always recommends clusters be designed with at least N+1 available capacity to ensure rebuild capacity exists and the cluster can automatically self heal.
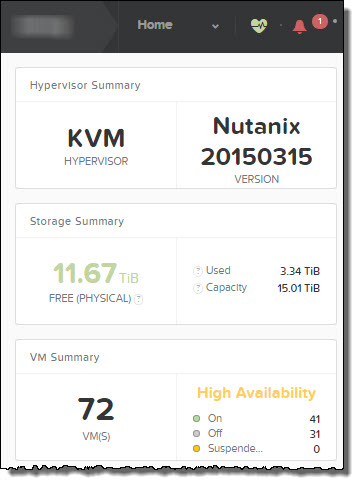
As a general rule it is recommended to wait for approx 10 mins between NOS and Hypervisor upgrades to avoid these kind of issues, or you can simply check the Home screen of PRISM and ensure the Heath status is Good as shown below:
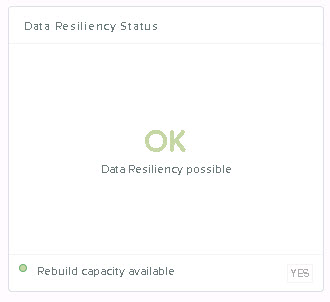
and that the Data Resiliency Status is “OK” as shown below.
Both the Health and Data Resiliency status are Hypervisor agnostic and appear on the Home screen of all Nutanix deployments.
If both the Health Status and Data Resiliency are good then you can go ahead and start the upgrade and it should complete successfully.
Summary:
PRISM will not start an upgrade of NOS or the Hypervisor if the cluster is degraded, so you can rest assured that even if you attempt an upgrade by accident when the cluster is degraded, NOS will protect you.
Related Posts:
1. Scaling Hyper-converged solutions – Compute only.
2. Acropolis Hypervisor (AHV) I/O Failover & Load Balancing
3. Advanced Storage Performance Monitoring with Nutanix
4. Nutanix – Improving Resiliency of Large Clusters with Erasure Coding (EC-X)
5. Nutanix – Erasure Coding (EC-X) Deep Dive