Let me start by asking, What’s all this “In-Kernel verses Virtual Storage Appliance” debate all about?
It seems to me to be total nonsense yet it is the focus of so called competitive intelligence and twitter debates. From an architectural perspective I just don’t get why it’s such a huge focus when there are so many other critical areas to focus on, like the benefit of Hyper-Converged vs SAN/NAS!!!
Saying In-Kernel or VSA is faster than the other (just because of where the software runs) is like saying my car with 18″ wheels is faster than your car with 17″ wheels. In reality there are so many other factors to consider, the wheel size is almost irrelevant, as is whether or not storage is provided “In-Kernel” or via a “Virtual Appliance”.
If something is In-Kernel, it doesn’t mean it’s efficient, it could be In-Kernel and really inefficient code, therefore being much worse than a VSA solution, or a VSA could be really inefficient and an In-Kernel solution could be more efficient.
In addition to this, Hyper-converged solutions are by design scale-out solutions, as a result the performance capabilities are the sum of all the nodes, not one individual node.
As long as a solution can provide enough performance (IOPS) per node for individual (or scaled up) VMs and enough scale-out to support all the customers VMs, it doesn’t matter if Solution A is In-Kernel or VSA, or that the solution can do 20% or even 100% more IOPS per node compared to solution B. The only thing that matters is the customers requirements are met/exceeded.
Let’s shift focus for a moment and talk about the performance capabilities of the ESX/ESXi hypervisor as this seems to be argued as an significant overhead which prevents a VSA from being high performance. In my experience , ESXi has never been a significant I/O bottleneck, even for large customers with business critical applications as the focus on Biz Critical Apps really took off around the VI3 days or later where the hypervisor could deliver ~100K IOPS per host.
The below is a chart showing VMware’s tested capabilities from ESX 1, through to vSphere 5 which was released in July 2011.
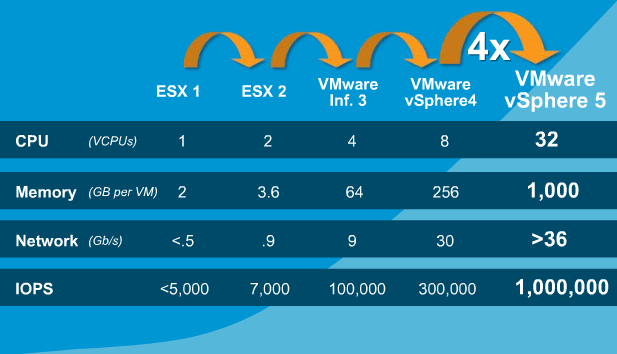
What we can clearly see is vSphere 5.0 can achieve 1 Million IOPS (per host), and even back in the VI3 days, 100,000 IOPS.
In 2011, VMware wrote a great article “Achieving a Million I/O Operations per Second from a Single VMware vSphere® 5.0 Host” which shows how the 1 million IOPS claim has been validated.
In 2012 VMware published “1 million IOPS On 1VM” which showed not only could vSphere achieve a million IOPS, but it could do it from 1 VM.
I don’t know about you, but it’s pretty impressive VMware has optimized the hypervisor to the point where a single VM can get 1 million IOPS, and that was back in 2012!
Now in both the articles, the 1 million IOPS was achieved using a traditional centralised SAN, the first article was with an EMC VMAX with 8 engines and I have summarized the setup below.
- 4 quad-core processors and 128GB of memory per engine
- 64 front-end 8Gbps Fibre Channel (FC) ports
- 64 back-end 4Gbps FC ports
- 960 * 15K RPM, 450GB FC drives
The IO profile for this test was 8K , 100% read, 100% random.
For the second 1 million IOPS per VM test, the setup used 2 x Violin Memory 6616 Flash Memory Arrays with the below setup.
- Hypervisor: vSphere 5.1
- Server: HP DL380 Gen8
CPU: 2 x Intel Xeon E5-2690, HyperThreading disabled
Memory: 256GB
- HBAs: 5 x QLE2562
- Storage: 2 x Violin Memory 6616 Flash Memory Arrays
- VM: Windows Server 2008 R2, 8 vCPUs and 48GB.
Iometer Config: 4K IO size w/ 16 workers
For both configurations, all I/O needs to traverse from the VM, through the hypervisor, out HBAs/NICs, across a storage area network, through central controllers and then make the return journey back to the VM.
There is so many places where additional latency or contention can be introduced in the storage stack it’s amazing VMs can produce the level of storage performance they do, especially back 3 years ago.
Chad Sakac wrote a great article back in 2009 called “VMware I/O Queues, Microbursting and Multipathing“, which has the below representation of the path I/O takes between a VM and a centralized SAN.
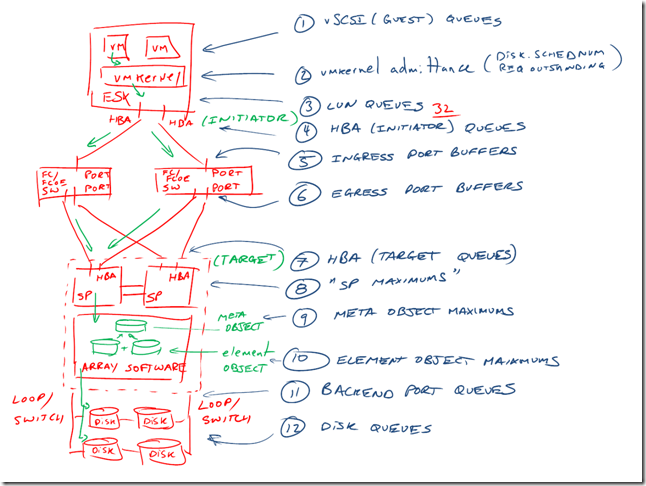
As we can see, Chad shows 12 steps for I/O to get to the disk queues, and once the I/O is completed, the I/O needs to traverse all the way back to the VM, so all in all you could argue it’s a 24 step round trip for EVERY I/O!
The reason I am pointing this out is because the argument around “In-kernel” verses “Virtual Storage Appliance” is only about 1 step in the I/O path, when Hyper-Converged solutions like Nutanix (which uses a VSA) eliminate 3/4’s of the steps in an overcomplicated I/O path which has been proven to achieve 1 million IOPS per VM.
Andre Leibovici recently wrote the article “Nutanix Traffic Routing: Setting the story straight” where he shows the I/O path for VMs using Nutanix.
The below diagram which Andre created shows the I/O path (for Read I/O) goes from the VM, across the ESXi hypervisor to the Controller VM (CVM) which then using DirectPath I/O to directly access the locally attached SSD and SATA drives.
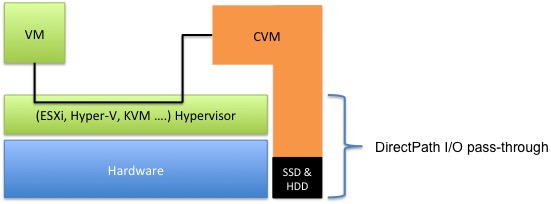
Consider if the VM in the above diagram was a Web Server and the CVM was a database server and they were running in an environment with a SAN/NAS. The Web Server would be communicating to the DB server over the network (via the hypervisor) but the DB Server would have to access it’s data (that the Web Server requested) from the centralized SAN, so in the vast majority of environments today (which are using SAN/NAS) the data is travelling a much longer path than it would compared to a VSA solution and in many cases traversing from one VM to another across the hypervisor before going to the SAN/NAS and back through a VM to be served to the VM requesting the data.
Now back to the diagram, For Nutanix the Read I/O under normal circumstances will be served locally around 95% of the time, this is thanks to data locality and how Write I/O happens.
For Write I/Os, one copy of each piece of data is written locally where the VM is running which means all subsequent Read I/O can be served locally (and freshly written data is also typically “Active data”), and the 2nd copy is replicated throughout the Nutanix cluster. This means even though half the Write I/O (of the two copies) needs to traverse the LAN, it doesn’t hit a choke point like a traditional SAN, because Nutanix scales out controllers on a 1:1 ratio with ESXi hosts and writes are distributed throughout the cluster in 1MB extents.
So if we look back to Chad’s (awesome!) diagram, Hyper-converged solutions like Nutanix and VSAN are only concerned with Steps 1,2,3,12 (4 total) for Read I/O and 1,2,3,12 as well as 1 step for the NIC at the source & 1 step for the NIC at the destination host.
So overall it’s 4 steps for Read, 6 steps for Write, compared to 12 for Read and 12 for Write for a traditional SAN.
So Hyper-converged solutions regardless of In-Kernel or VSA based remove many of the potential points of failure and contention compare to a traditional SANNAS and as a result, have MUCH more efficient data paths.
On twitter recently, I responded to a tweet where the person claims “Hyperconverged is about software, not hardware”.
I disagree, Hyper-converged to me (and the folk at Nutanix) is all about the customer experience. It should be simple to deploy, manage, scale etc, all of which constitute the customers experience. Everything in the datacenter runs on HW, so I don’t get the fuss on the Software only vs Appliance / OEM software only solution debate either, but this is a topic for another post.
I agree doing things in software is a great idea, and that is what Nutanix and VSAN do, provide a solution in software which combines with commodity hardware to create a Hyper-converged solution.
Summary:
A great customer experience (which is what I believe matters) along with high performance (1M+ IOPS) solution can be delivered both In-Kernel or via a VSA, it’s simple as that. We are long past the days where a VM was a significant bottleneck (circa 2004 w/ ESX 2.x).
I’m glad VMware has led the market in pushing customers to virtualize Business Critical Apps, because it works really really well and delivers lots of value to customers.
As a result of countless best practice guides, white papers, case studies from VMware and VMware Storage Partners such as Nutanix, we know highly compute / network & storage intensive applications can easily be virtualized, so anyone saying a Virtual Storage Appliance can’t (or shouldn’t) be, simply doesn’t understand how efficient the ESXi hypervisor is and/or he/she hasn’t had the industry experience deploying storage intensive Business Critical Applications.
To all Hyper-converged vendors: Can we stop this ridiculous debate and get on with the business of delivering a great customer experience and focus on the business at hand of taking down traditional SAN/NAS? I don’t know about you, but that’s what I’ll be doing.


