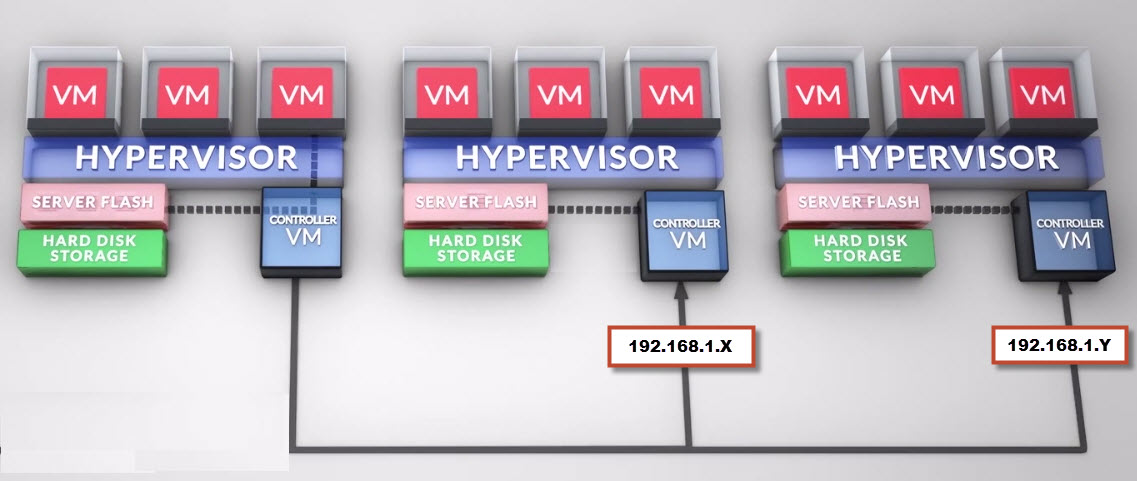
Problem Statement
When Virtualizing Exchange 2013 (which is considered by the customer as a Business Critical Application) in a vSphere cluster shared with other production workloads of varying sizes and performance requirements, should Hyper Threading (HT) be used?
Assumptions
1. vSphere 5.0 or greater
2. Exchange Servers are correctly sized day one or are subsequently “Right Sized”
3. Cluster average CPU overcommitment of 3:1
Motivation
1. Ensure Optimal performance for BCAs (Exchange)
2. Ensure Optimal performance for other Virtual servers in the shared vSphere cluster
Architectural Decision
Enable Hyper Threading (HT)
Alternatives
1. Disable Hyper Threading (HT)
2. Enable Hyper Threading but configure Exchange Virtual machine/s with Advanced CPU, HT Sharing Mode of “None” to ensure Exchange is always scheduled onto physical CPU cores
3. Split off a limited number of ESXi hosts and form a dedicated BCA cluster w/ <= 2:1 overcommitment and disable HT
4. Disable HT on a number of nodes within the cluster but leave HT enabled on other nodes and use DRS rules to pin Exchange VMs to non HT hosts
Justification
1. Enabling Hyper Threading (HT) improves the efficiency of the CPU scheduler, which will minimize the possibility of CPU Ready for the Exchange server/s and other virtual machines on the host where a low level of overcommitment exists (<2:1)
2. For optimal performance, DRS “Should” rules will be used to keep Exchange (BCA) workloads on specific ESXi hosts within the cluster where <=2:1 CPU overcommitment is maintained
3. Configuring Advanced CPU, HT Sharing Mode to “None” (to guarantee only pCore’s are used) may result in increased CPU Ready as the CPU scheduler is forced to find (and wait) for available pCore’s which may result in degraded or inconsistent performance.
4. Sizing for the Exchange solution was completed taking into account only pCore’s (Not HT cores) to simplify sizing
5. As the cluster where Exchange is virtualized is shared with other server workloads with varying levels of importance and performance, HT benefits the vast majority of workloads and results in a higher consolidation ratio and better performance for the vSphere cluster as a whole.
6. In physical servers, enabling Hyper Threading on Exchange servers resulted in wasted or excessive RAM usage for .NET garbage collection due to memory for .NET being allocated based on logical cores. This does not impact “Right Sized” Virtual Machines as only the required number of vCPUs are assigned to the VM, and therefore available to the Guest OS. This avoids the issue of memory being wasted for HT cores.
7. The CPU scheduler in vSphere 5.0 or later is very efficient and can intelligently schedule workload on a hyper-thread or a physical core depending on the VMs CPU demand. While the Exchange server will at some point be scheduled onto a HT thread, this is not likely to be for any extended duration or have any significant impact on performance.
8. Splitting the cluster into BCA’s and server workloads would increase the HA overhead, and effective reduce the usable compute capacity of the infrastructure.
9. Having a cluster with varying configurations (eg: HT enabled on some hosts and not others) is not advisable as it may lead to inconsistent performance and adds unnecessary complexity to the environment
Implications
1. In the event the vCPU to pCore ratio is > 2:1 for any reason (including HA event & Virtual Server Sprawl) the number of users supported and/or the performance of the Exchange environment may be impacted
2. DRS “Should” rules will need to be created to keep Exchange workloads on hosts with <2:1 vCPU to pCore ratio