With all the choice in the compute/storage market at the moment, choosing new infrastructure for your next project is not an easy task.
In my experience most customers (and many architects) think about the infrastructure coming up for replacement and look to do a “like for like” replacement with newer/faster technology.
An example of this would be a customer with a FC SAN running Oracle workloads where the customer or architect replaces the end of life Hybrid FC SAN with an All Flash FC SAN and continues running Oracle “as-is”.
Now I’m not saying there is anything wrong with that, however if we consider more than just the one workload, we may be able to achieve our business requirements with a more standardized and cost effective approach than having dedicated infrastructure for specific workloads.
So in this post, I am inviting you to consider the bigger picture.
If we take an example customer has the following workload requirements:
- Virtual Desktop (VDI)
- Virtualized Business Critical Applications (e.g.: SQL / Exchange)
- Long Term Archive (High Capacity, low IOPS)
- Business Continuity and Disaster Recovery
It is unlikely any one solution from any vendor is going to be the “best” in all areas as every solution has its pros and cons.
Regarding VDI, I would say most people would agree Hyperconverged Infrastructure (HCI) / Scale out type architectures are strong for VDI, however VDI can be successfully deployed on a traditional SAN/NAS solutions or using non shared local storage in the case of non-persistent desktops.
For vBCA, some people believe physical servers with JBOD storage is best for workloads like Exchange, and Physical + local SSD are best for Databases while many people are realising the benefits of virtualization of vBCA with shared storage such as SAN/NAS or on HCI.
For long term archive, cost per GB is generally one of if not the most critical factor where lots of trays of SATA storage connected to a small dual controller setup may be the most cost effective, whereas an All Flash array would be less likely considered in this use case.
For BC/DR, features such as a Storage Replication Adapter (SRA) for VMware Site Recovery Manager, a stretched cluster capability and some form of snapshot capability and replication would be typical requirements. Some newer technology can do per VM snapshots, whereas older style SAN/NAS technology may be per LUN, so newer technology would have an advantage here, but again, this doesn’t mean one tech should not be considered.
So what product do we choose for each workload type? The best of breed right?
Well, maybe not. Lets have a look at why you might not want to do that.
The below graph shows an example of 3 vendors being compared across the 4 categories I mentioned above being VDI, vBCA, Long Term Archive and BC/DR.
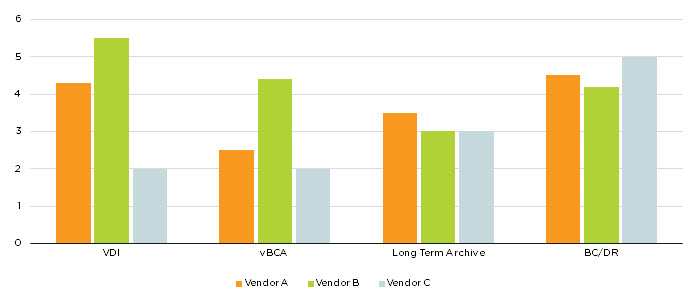
The customer has determined that a score of 3 is required to meet their requirements so a solution failing to achieve a 3 or higher will not be considered (at least for that workload).
As we can see, for VDI Vendor B is the strongest, Vendor A second and Vendor C third, but when we compare BC/DR Vendor C is strongest followed by Vendor A and lastly Vendor B.
We can see for Long Term Archive Vendor A is the strongest with Vendor B and C tied for second place and finally for vBCA Vendor B is the strongest, Vendor A second and Vendor C third.
So if we chose the best vendor for each workload type (or the “Best of breed” solution) we would end up with three different vendors equipment.
- VDI: Vendor B
- Long Term Archive: Vendor A
- BC/DR: Vendor C
- vBCA: Vendor B
Is this a problem? Not necessarily but I would suggest that there are several things to consider including:
1. Having 3 different platforms to design/install/maintain
This means 3 different sets of requirements, constraints, risks, implications need to be considered.
Some large organisations may not consider this a problem, because they have a team for each area, but isn’t the fact the customer has to have multiple teams to manage infrastructure a problem in itself? Sounds like a significant (and potentially unnecessary) OPEX to me.
2. The best BC/DR solution does not meet the minimum requirements for the vBCA workloads.
In this example, the best BC/DR solution (Vendor C) is also the lowest rated for vBCA. As a result, Vendor C is not suitable for vBCA which means it should not be considered for BC/DR of vBCA. If Vendor C was used for BC/DR of the other workloads, then another product would need to be used for vBCA adding further cost/complexity to the environment.
3. Vendor A is the strongest at Long Term Archive, but has no interoperability with Vendor B and C
Due to the lack of interoperability, while Vendor A has the strongest Archiving solution, it is not suitable for this environment. In this example, the difference between the strongest Long Term Archive solution and the weakest is very small so Vendor B and C also meet the customers requirements.
4. Multiple Silos of infrastructure may lead to inefficient use.
Just like in the days before Virtualization, we had the bulk of our servers CPU/RAM running at low utilization levels, we had our storage capacity carved up where we had lots of free space in one RAID pack but very little free space in others and we spent lots of time migrating workloads from LUN 1 to LUN 2 to free up capacity for new or existing workloads.
If we have 3 solutions, we may have many TB of available capacity in the VDI environment but be unable to share it with the Long Term Archiving. Or we may have lots of spare compute in VDI and be unable to share it with vBCA.
Now getting back to the graph, the below is the raw data.
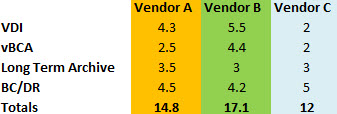
What we can see is:
- Vendor B has the highest total (17.1)
- Vendor A has the second highest total (14.8)
- Vendor C has the lowest total (12)
- Vendor C failed to meet the minimum requirements for VDI & vBCA
- Vendor A and B met the minimum requirements for all areas
Let’s consider the impact of choosing Vendor B for all 4 workload types.
VDI – It was the highest rated, met the minimum requirements for the customer and is best of breed, so in this case Vendor B would be a solid choice.
vBCA – Again Vendor B was the highest rated, met the minimum requirements for the customer and is best of breed, so Vendor B would be a solid choice.
Long Term Archiving: Vendor B was equal last, but importantly met the customer requirements. Vendor A’s solution may have more features and higher performance, but as Vendor B met the requirements, the additional features and/or performance of Vendor A are not required. The difference between Vendor A (Best of Breed) and Vendor B was also minimal (0.5 rating difference) so Vendor B is again a solid choice.
BC/DR: Vendor B was the lowest rated solution for BC/DR, but again focusing on the customers requirements, the solution exceeded the minimum requirement of 3 comfortably with a rating of 4.2. Choosing Vendor B meets the requirements and likely avoids any interoperability and/or support issues, meaning a simpler overall solution.
Let’s think about some of the advantages for a customer choosing a standard platform for all workloads in the event a platform meets all requirements.
1. Lower Risk
Having a standard platform minimizes the chance of interoperability and support issues.
2. Eliminating Silos
As long as you can ensure performance meets requirements for all workloads (which can be difficult on centralized SAN/NAS deployments) then using a standard platform will likely lead to better utilization and higher return on investment (ROI).
3. Reduced complexity / Single Pane of Glass Management
Having one platform means not having to have SMEs in multiple technologies, or in larger organisations multiple SMEs per technology (for redundancy and/or workload) meaning reduced complexity, lower operational costs and possibly centralized management.
4. Lower CAPEX
This will largely depend on the vendor and quantity of infrastructure purchased, however many customers I have worked with have excellent pricing from a vendor as a result of standardizing.
Summary:
I am in no way saying “One size fits all” or that “every problem is a Nail” and recommending you buy a hammer. What I am saying is when considering infrastructure for your environment (or your customers), avoid tunnel vision and consider the other workloads or existing infrastructure in the environment.
In many cases the “Best of Breed” solution is not required and in fact implementing that solution may have significant implications in other areas of the environment.
In other cases, workloads may be so mission critical, that a best of breed solution may be the only way to meet the business requirements, in which case, a using a standard platform that may not meet the requirements would not be advised.
However if you can meet all the customer requirements with a standard platform while working within constraints such as budget, power, cooling, rack space and time to value, then I would suggest your doing yourself (or your customer) a dis-service by not considering using a standard platform for your workloads.
Related Articles:
1. Enterprise Architecture & Avoiding tunnel vision.
2. Peak Performance vs Real World Performance









