In recent weeks I have been presenting at a number of Nutanix .NEXT roadshow events and I was asked a good question about Erasure Coding (EC-X) at the Melbourne event which I felt justified a quick post.
The question was along the lines of:
How does Erasure Coding affect Write intensive workloads?
The question came following a statement I made which was to the effect of enabling RF3 + Erasure Coding may prove to be an excellent default container configuration when talking about resiliency and capacity optimization.
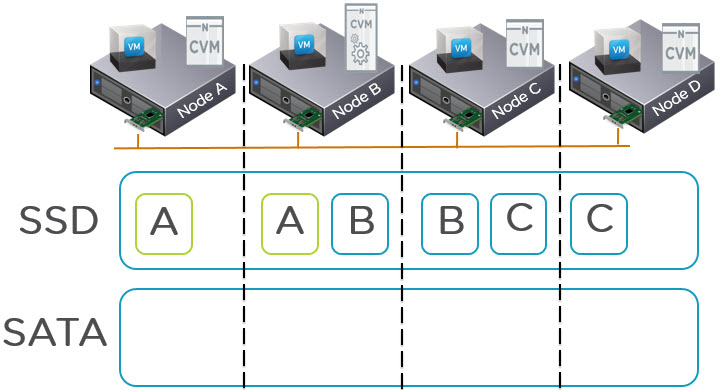
So let’s take a look at the Write path for a Nutanix XCP environment with EC-X enabled:

Step 1: Confirm the data resiliency being RF2 or RF3 (FTT1 / FTT2 in other vendor speak)
Step 2: Is the I/O random or sequential
Step 3: Is the Data Write Hot?
This is where we start talking about EC-X and one of the areas where Nutanix patent pending algorithm shines. The XCP monitors the data and when the data is write hot, EC-X will not be performed on that data and the blocks (or “extents” in Nutanix Distributed File System speak) will remain in the SSD tier.
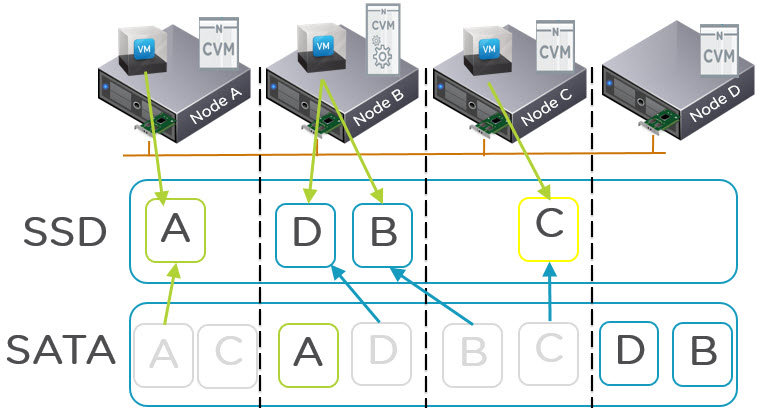
Step 4: If the data is not Write Hot, perform EC-X on the data.
Step 5: Is the data Read hot?
What do I mean by read hot? Basically is the data being read frequently (but not overwritten). If it is Read Hot, the data will remain in the SSD tier having previously been striped by EC-X.
As a result, more data can now fit into the SSD tier giving better overall performance for a larger working set.
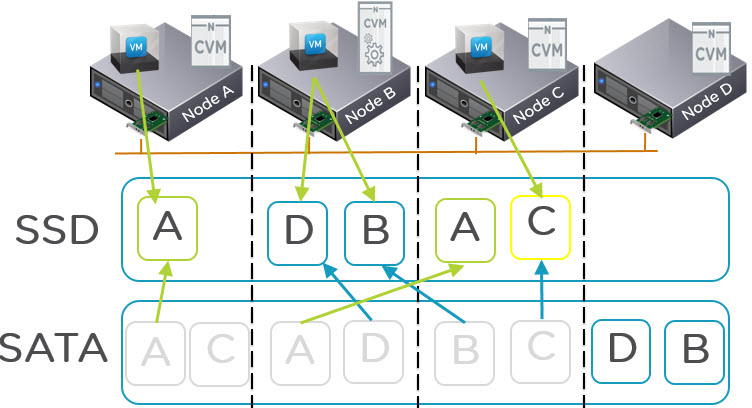
Step 6: If the data is not Read Hot (and not write hot) it will be a candidate for migration to the low cost SATA tier via Nutanix ILM (Intelligent Life-cycle Management) process which runs in real time (not on a scheduled basis).
So will a write intensive workloads performance be degraded if EC-X is enabled?
Short answer: No
If the container where the write intensive workload is running is configured with EC-X, the data which is write intensive will simply not be subject to EC-X as the platform understands and monitors the data and only applied EC-X if the data becomes write cold.
So the good news is, even if you enable EC-X it will not impact write intensive workloads, but it will provide capacity savings and an effective increase in usable SSD tier for the data which is Write Cold, Read Hot/Cold.