I was recently discussing the Nutanix solution with a friend of mine and fellow VCDX, Michael Webster (@vcdxnz001) and he asked what the recommended Host Isolation Response is for Nutanix.
At this stage I must advise there is no formal recommendation, but an Official vSphere on Nutanix Best Practice guide is in the works and will be released asap.
Back to my conversation with Michael, Being that Nutanix is an IP Storage solution, my initial feeling is that Host isolation Response should be set to “Shutdown”, but I didn’t go into any more detail with Michael, so I thought it best to post a quick explanation.
This post also assumes basic knowledge of vSphere as well as the Nutanix platform, for those of you who are not familiar with Nutanix please review the following links prior to reading the remainder of this post.
About Nutanix | How Nutanix Works | 8 Strategies for a Modern Datacenter
So back on topic, in other posts I have written for IP Storage, such as (Example Architectural Decision – Host Isolation Response for IP Storage) I have concluded that “Shutdown” was the most suitable setting and recommended specifying isolation addresses of the NAS controllers.
But as Nutanix changes the game and has one virtual storage controller per ESXi host, so does this change the recommendation?
In short, No, but for those who are interested, here is why.
If we leave the default isolation address, (being the default gateway for ESXi Management), in the event the gateway is down, it will trigger an isolation response even if the rest of the network is operating fine, thus an unnecessary outage would occur.
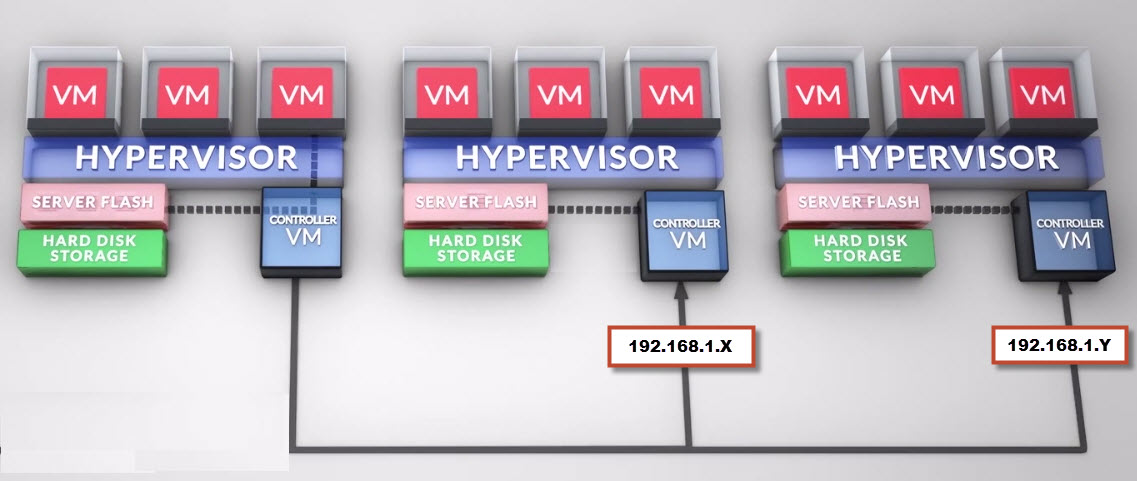
If we configure das.isolationaddress1 & 2 with the Management IP address of any two Nutanix Controller VMs (192.168.1.x , 192.168.1.y in my below diagram) then an isolation response will only be triggered if both Nutanix Controller VMs (CVMs) are not responding, in which case, the VMs should be Shutdown as the Nutanix cluster may not be function properly with two Controllers offline concurrently as its configured by default for N+1 (or replication factor of “2” in Nutanix speak).
The below is a high level example of the above configuration.
Related Articles
1. Example Architectural Decision – Host Isolation Response for a Nutanix Environment
2. Storage DRS and Nutanix – To use, or not to use, that is the question?