In Part 1, the example provided showed usable capacity for a SAN/NAS using a combination of RAID 10, RAID 5 and RAID 6 along with the various sizing considerations resulted in 35.68TB usable capacity or approx 1/3rd of the RAW 100TB.
In Part 2 we will discuss the misconception that Nutanix (a Hyper-converged platform) provides lower effective usable capacity compared to SAN or NAS solutions.
At a high level, Nutanix uses Replication Factor 2 (RF2) which has the same overhead as RAID 1 so straight away a lot of people jump to the conclusion that the usable capacity is less that a traditional SAN/NAS because *insert your favourite RAID level here* has less overhead.
Let’s say we have a Nutanix cluster with 100TB Raw storage using the most common node type, the NX3050.
Now let’s address the same points as we did in Part 1 for the SAN/NAS example:
So starting with the same 100TB RAW as we did for the SAN/NAS example and see where things end up on Nutanix.
1. Deducting hot spare drives
Nutanix does not use hot spare drives, data is balanced across all drives in the “Storage Pool”. To cater for failure, it is recommended to size for N+1 for Resiliency Factor 2 (RF2) deployments. If we we’re using NX3050 nodes (the most popular Nutanix node) then the overhead of N+1 would be ~4.8TB RAW.
100TB – N+1 Node (4.8TB RAW) = 95.2TB
2. RAID Overhead
Nutanix doesn’t use RAID, but the Replication Factor 2 has an overhead is 50% (the same as RAID10).
95.2TB – 50% (RF2) = 47.6TB remaining
3. Free Space on the platform required to ensure performance
For Nutanix all write I/O goes to either the Extent Storage or Oplog, both of which are housed on the SSD tier. All random writes are serviced by the Oplog until it reaches 95% capacity at which point the oplog is bypassed.
As such, performance remains high until 95% capacity. Therefore only 5% free capacity is required to ensure high performance.
47.6TB – 5% (Free space for performance) = 45.2TB
FYI: Nutanix Performance and Engineering team members including myself typically conduct benchmarks at greater than 90% cluster capacity.
4. Free space per LUN
Nutanix does not use LUNs. Nutanix presents containers to the hypervisor. All containers are thin provisioned and all containers can use all available space in the storage pool. Meaning free space only needs to be managed at the Storage Pool layer, not at each individual container.
As we have already taken into account the 5% free space there is no need to take another 5% of space therefore we remain at 45.2TB usable.
5. Free space per VMDK
As with physical servers and SAN/NAS environments, we don’t want our VMs drives running out of capacity, as a result it is common to size VMDKs well above what is strictly required to make capacity management (operational tasks) easier.
As mentioned in Part 1, I typically see architects recommending upwards of 10-20% free space per VMDK over and above what is required to account for unexpected growth, OS patching etc. This makes perfect sense for the same reason as we have free space per LUN because if space runs out for a VM, it’s another bad day for I.T.
For this example, I will assume the same 10% free space per VMDK as I did for SAN/NAS example, the difference with Nutanix is performance remains the same regardless of the VMDK being Thick or Thin provisioned, so with every VM Thin Provisioned, no capacity is required to be reserved for free space within VMDK files as it would be for traditional environments requiring Eager Zero Thick VMDKs for performance..
So we’re still at 45.2TB usable.
Now where are we at?
So far, the first 5 points are fairly easy to calculate.
Next we will look at various factors which further reduce usable capacity for SAN/NAS and see how they apply to Nutanix.
6. Silos for Performance
Nutanix does not require nor recommend silos being created for performance reasons. All VMs can reside in a single container therefore no capacity is unusable as a result of performance requirements.
As no silos are required for maximum performance, we are still at 45.2TB usable.
7. Silos of (or Fragmented) Usable Capacity
Nutanix does not configure usable capacity to containers, a container can use all the available storage in the underlying Storage Pool. Where multiple containers are provisioned, each container can see the total capacity of the storage pool while providing logical separation of the VMs within the containers. This avoids the issue of fragmented free capacity.
The diagram below shows 5 containers hosted by an example Nutanix cluster (Storage Pool) with 100TB total capacity, each container has a capacity of 100TB and 25TB free space in alignment with the underlying storage pool.

In this case, when creating a new VM, or adding or expanding VMDKs for existing VMs, it does not matter which container we place the VM, as long as it is less than the 25TB available in the pool, it makes no difference to capacity.
This removes the requirement for complex capacity management, or using Storage DRS and Storage vMotion.
So we’re still at 45.2TB usable.
Other factors which reduce usable capacity?
8. LUN Provisioning Type
In many cases, especially when talking about high performance applications, storage vendors recommend using Thick Provisioned LUNs and as mentioned in Part 1, It’s anyone’s guess how much space is wasted as a result.
But with Nutanix, all containers are Thin Provisioned so no capacity is wasted on Thick Provisioning and performance is optimal
9. Wasted Capacity from using SSDs as Cache
Nutanix does not use SSDs as Cache! The SSD’s form part of the Extent Store which is for persistent data storage. The OpLog which is also on SSD is also persistent and not a “cache”. As such, no capacity is being reduced as a result of caching.
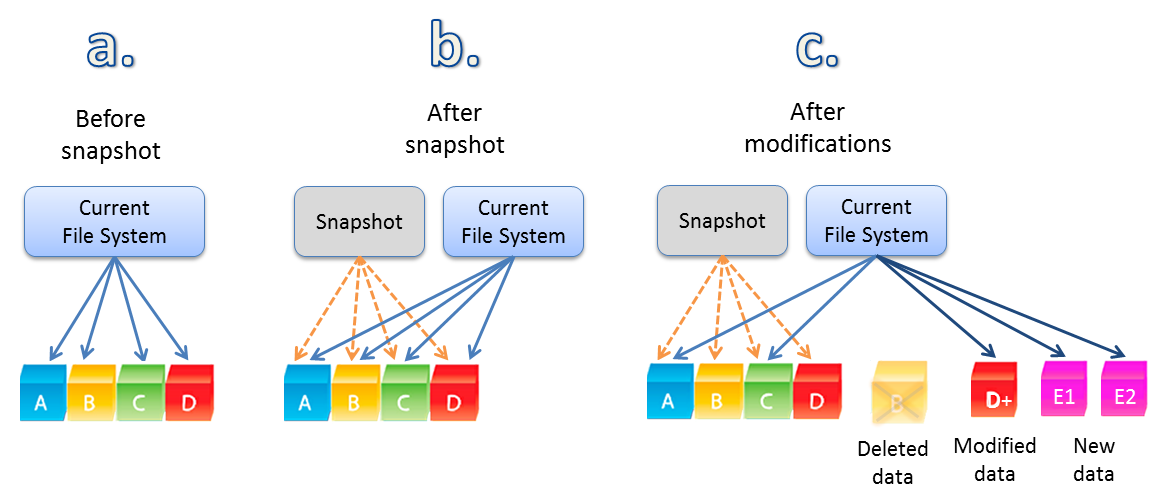
10. Snapshot Reserves
Nutanix does not use reserve capacity for snapshots. Snapshots simply use available capacity in the storage pool. If you don’t use snapshots, no space is wasted, if you do use snapshots, then the delta changes are stored. Simple as that.
Summary:
From the 100TB RAW factoring in what is a realistic Nutanix configuration including N+1 to tolerate a node failure and support the cluster being able to fully self heal the effective usable capacity is 45.2TB which is just under 50% of 100TB RAW.
This is a very simple configuration to manage from both a performance and capacity perspective, and one which is easily calculated and repeatable.
If the Resiliency Factor was 3 (which IMO is rarely if ever required) across the entire environment (which again would be extremely unusual as VMs which require RF3 can be configured in an RF3 container) then the usable capacity would be ~30TB which is only sightly below the SAN/NAS example and RF3 delivers higher resiliency.
In reality, >95% of workloads should be deployed on RF2, with a very small number of VMs possibly using RF3. In reality RF2 is extremely resilient and self healing so IMO RF3 is rarely required.
So in conclusion, Nutanix usable capacity is ~50% of RAW capacity, the difference between Nutanix and traditional SAN/NAS is you actually can use almost all the “usable” capacity and maintain optimal performance with little/no complexity.
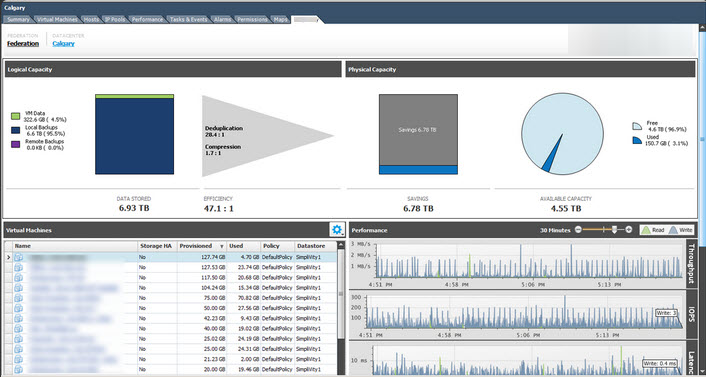
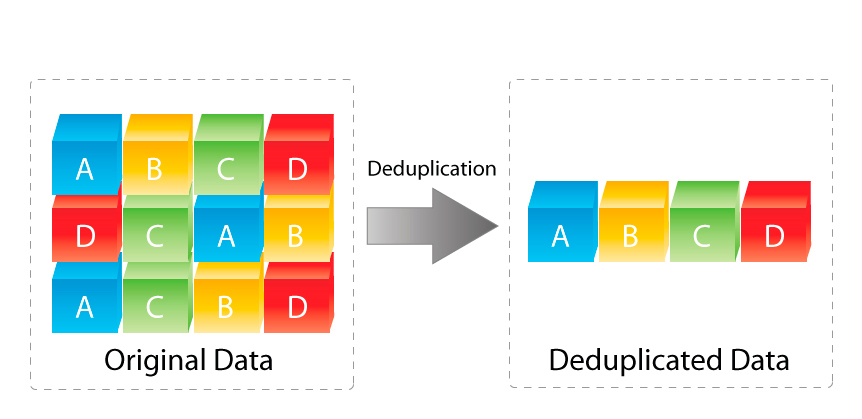
Nutanix also has data reduction technologies such as Compression and De-duplication, along with intelligent cloning to increase the effective capacity of the storage pool.
While I believe Nutanix’ usable capacity today is excellent especially when considering how resilient RF2 is and comparing usable capacity to many products on the market, Nutanix has the advantage of not being constrained by legacy technologies such as RAID, so I’ll leave you with a little teaser:
Usable capacity will be improving significantly in upcoming releases of Nutanix Operating System. 🙂