In a recent post I discussed how NOS 4.5 increases the effective SSD tier capacity by performing up-migrations on only the local extent as opposed to both RF copies within the Nutanix cluster. In addition to this significant improvement in usable SSD tier, in NOS 4.5 the read performance from the SATA tier has also received lots of attention from Nutanix engineers.
What the Solutions and Performance Engineering team have discovered and been testing is how we can improve SATA performance. Now ideally the active working set for VMs will fit within the SSD tier, and the changes discussed in my previous post dramatically improve the chances of that active working set fitting within the SSD tier.
But there are situation when reads to cold data still need to be serviced by the slow SATA drives. Nutanix uses Data Locality to ensure the hot data remains close to the application to deliver the lowest latency and overheads which improve performance, but in the case of SATA drives and the fact data is infrequently accessed from SATA means that reading from remote SATA drives can improve performance especially where the number of local SATA drives is limited (in some cases to only 2 or 4 drives).
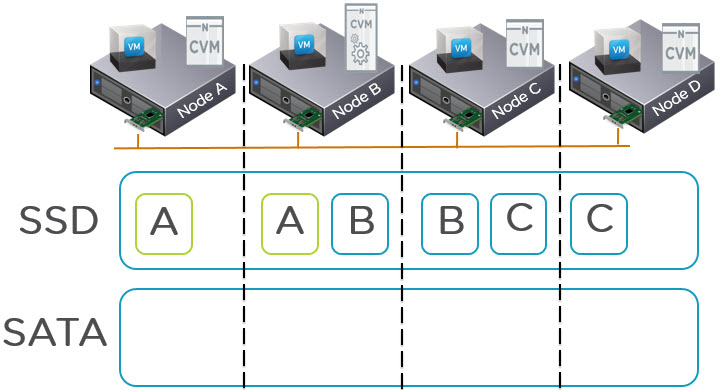
Most Nutanix nodes have 2 x SSD and 4 x SATA so best case you will only see a few hundred IOPS from SATA as that is all they are physically capable of. To get around this issue.
NOS 4.5 introduces some changes to the way in which we select a replica to read an egroup from the HDD tier. Periodically NOS (re)calculate the average IO latencies of the all the replicas of a vdisk’s (replicas which have the vdisk’s egroups). We use this information to choose a replica as follows:
- If the latency of the local replica is less than a configurable threshold, read from the local replica.
- If the latency of the local replica is more than a configurable threshold, and the latency of the remote replica is more than that of the local replica, prefer the local replica.
- If the latency of the local replica is more than a configurable threshold and the remote replica is lower than the configurable threshold OR lower than the local copy, prefer the remote replica.
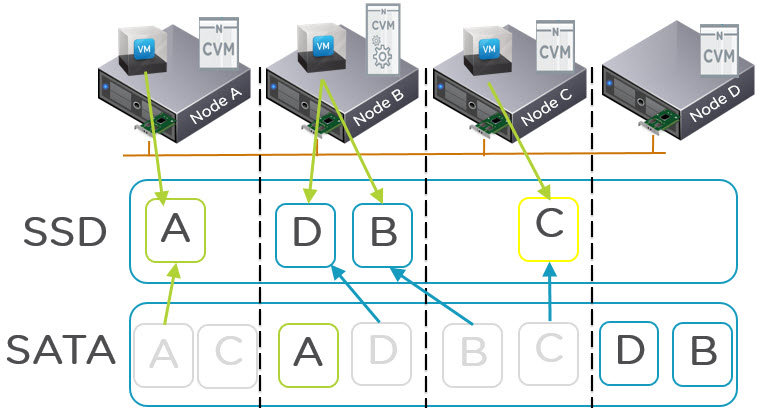
The diagram below shows an example of where the VM on Node A is performing random reads to data A and shortly thereafter data C. When requesting reads from data A the latency is below the threshold but when it requests data C, NOS detects that the latency of the local copy is higher than the remote copy and selects the remote replica to read from. As the below diagram shows, one possible outcome when reading multiple pieces of data is one read is served locally and the other is serviced remotely.

Now the obvious next question is “What about Data Locality”.
Data Locality is being maintained for the hot data which resides in SSD tier because reads from SSD are faster and have lower overheads on CPU/Network etc when read locally due to the speed of SSDs. For SATA reads which are typical >5ms the SATA drive itself is the bottleneck not the network, so by distributing the Reads across more SATA drives even if they are not local, results in better overall performance and lower latency.
Now if the SSD tier has not reached 75% all data will be within the SSD tier and will be served locally, the above feature is for situations where the SSD tier is 75% full and data is being tiered to SATA tier AND random reads are occurring to cold data OR data which will not fit in the SSD tier such as very large databases.
In addition NOS 4.5 detects if the read I/O is random or sequential, and if its sequential (which SATA performance much better at) then the up-migration of data has a higher threshold to meet before being migrated to SSD.
The result of these algorithm improvements (and the increased SSD tier effective capacity discussed earlier) and Nutanix In-line compression is higher performance over larger working sets which also exceed the capacity of the SSD tier.
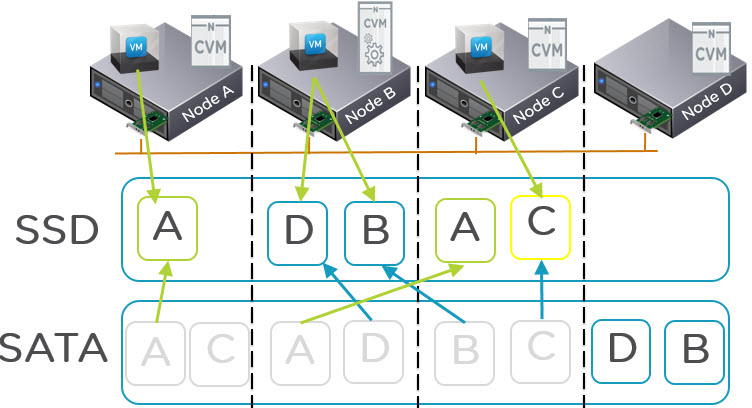
Effectively NOS 4.5 is delivering a truly scale out solution for read I/O from SATA tier which means one VM can be reading from potentially all nodes in the cluster ensuring SATA performance for things like Business Critical Applications is both high and consistent. Combine that with NX-6035C storage only nodes, this means SATA read I/O can be scaled out as shown in the below diagram without scaling compute.

As we can see above, the Storage only Nodes (NX-6035C) are delivering additional performance for read I/O from the SATA tier (as well as from the SSD tier).