
Back in 2015 I wrote a series titled “Why Nutanix Acropolis Hypervisor (AHV) is the next generation hypervisor” which covered off many reasons why AHV was and would become a force to be reckoned with.
In short, AHV is the only purpose built hypervisor for hyper-converged infrastructure (HCI) and it has continued to evolve in terms of functionality and maturity while becoming a popular choice for customers.
How popular you ask? Nutanix officially reported 23% adoption as a percentage of nodes sold in our recent third quarter fiscal year 2017 financial highlights.
Over the last couple of years I have personally worked with numerous customers who have adopted AHV especially when it comes to business critical applications such as MS SQL, MS Exchange.
One such example is Shinsegae who is a major retailer running 50,000 MS Exchange mailboxes on Nutanix using AHV as the hypervisor. Shinsegae also runs MS SQL workloads on the same platform which has now become the standard platform for all workloads.
This is just one example of AHV proven in the field and at scale to have the functionality, resiliency and performance to support business critical workloads.
But at Nutanix we’re always striving to deliver more value to our customers, and one area where there is a lot of confusion and misinformation is around the efficiency of the storage I/O path for Nutanix.
The Nutanix Controller VM (CVM) runs on top of multiple hypervisors and delivers excellent performance, but there is always room for improvement. With our extensive experience with in-kernel and virtual machine based storage solutions, we quickly learned that the biggest bottleneck is the hypervisor itself.
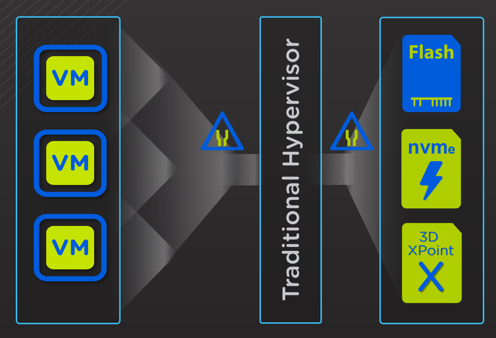
With technology such as NVMe becoming mainstream and 3D XPoint not far behind, we looked for a way to give customers the best value from these premium storage technologies.
That’s where AHV Turbo mode comes into play.
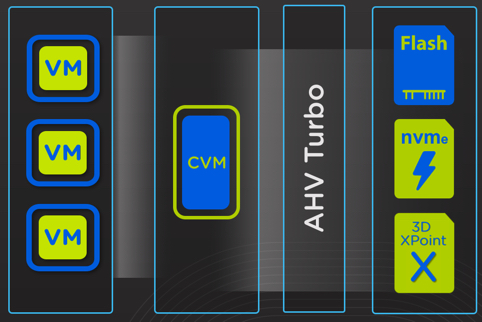
AHV Turbo mode is a highly optimised I/O path (shortened and widened) between the User VM (UVM) and Nutanix stargate (I/O engine).
These optimisation have been achieved by moving the I/O path in-kernel.
V
V
V
V
V
V
V
V
V
V
V
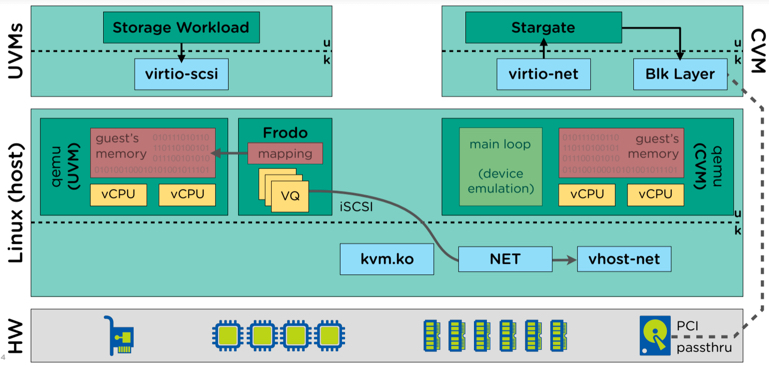
Just kidding! In-kernel being better for performance is just a myth, Nutanix has achieved major performance improvements by doing the heavy lifting of the I/O data path in User Space, which is the opposite of the much hyped “In-kernel”.
The below diagram show the UVM’s I/O path now goes via Frodo (a.k.a Turbo Mode) which runs in User Space (not In-kernel) and onto stargate within the Controller VM).
Another benefit of AHV and Turbo mode is that it eliminates the requirement for administrators to configure multiple PVSCSI adapters and spread virtual disks across those controllers. When adding virtual disks to an AHV virtual machine, disks automatically benefit from Nutanix SCSI and block multi-queue ensuring enhanced I/O performance for both reads and writes.
The multi-queue I/O flow is handled by multiple frodo threads (Turbo mode) threads and passed onto stargate.
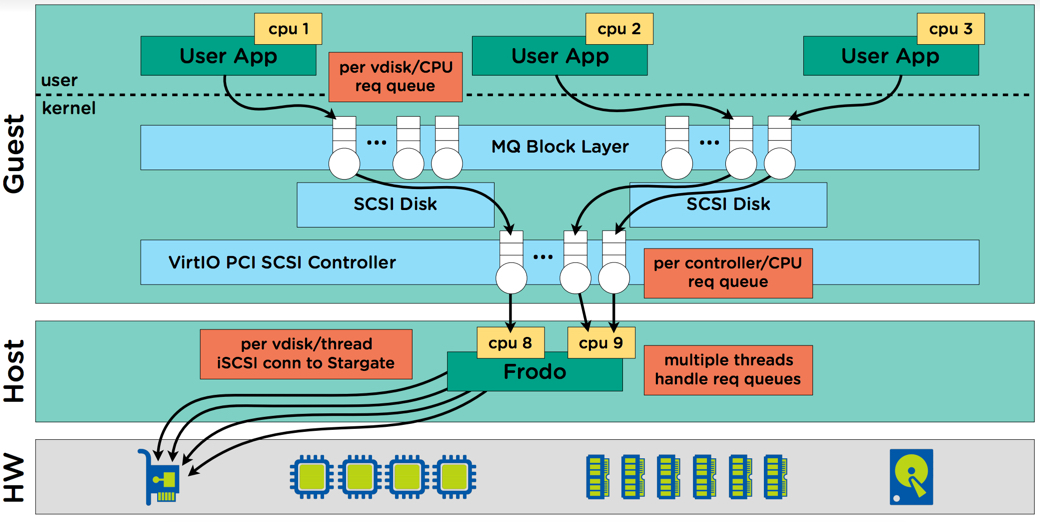
As the above diagram shows, Nutanix with Turbo mode eliminates the bottlenecks associated with legacy hypervisors, one such example is VMFS datastores which required VAAI Atomic Test and Set (ATS) to minimise the impact of locking when the numbers of VMs per datastore increased (e.g. >25). With AHV and Turbo mode, every vdisk has always had it’s own queue (not one per datastore or container) but frodo enhances this by adding a per-vcpu queue at the virtual controller level.
How much performance improvement you ask? Well I ran a quick test which showed amazing performance improvements even on a more than four year old IVB NX3450 which only has 2 x SATA SSDs per node and with the memory read cache disabled (i.e.: No reads from RAM).
A quick summary of the findings were:
- 25% lower CPU usage for the similar sequential write performance (2929MBps vs 2964MBps)
- 27.5% higher sequential read performance (9512MBps vs 7207MBps)
- A 62.52% increase in random read IOPS (510121 vs 261265)
- A 33.75% increase in random write IOPS (336326 vs 239193)
So with Turbo Mode, Nutanix is using less CPU and RAM to drive higher IOPS & throughput and doing so in user space.
Intel published “Code Sample: Hello World with Storage Performance Development Kit and NVMe Driver” which states “When comparing the SPDK userspace NVMe driver to an approach using the Linux Kernel, the overhead latency is up to 10x lower”.
This is just one of many examples which shows userspace is clearly not the bottleneck that some people/vendors have tried to claim with the “in-kernel” is faster nonsense I have previously written about.
With Turbo mode, AHV is the highest performance (throughput / IOPS) and lowest latency hypervisor supported by Nutanix!
But wait there’s more! Not only is AHV now the highest performing hypervisor, it’s also used by our largest customer who has more than 1750 nodes running 100% AHV!


