In my opinion there are three key areas for a solution such as the Nutanix platform to deliver consistent successful business outcomes.
They are of course Scalability, Resiliency and Performance.
 If a product is strong in just one of these areas and weak in the other two, put simply it’s very unlikely to be a minimally viable product.
If a product is strong in just one of these areas and weak in the other two, put simply it’s very unlikely to be a minimally viable product.
Even two out of three isn’t enough, you need a product which delivers all three to a high standard if you want to have a successful business outcome.
For example, if you have a product which performs well, but doesn’t scale then a customer who has the potential of growth should not consider that product. If a product is very scalable but isn’t resilient is unlikely to be suitable for any production workloads and if a solution is resilient but not scalable, then again we have major constraints which make it unattractive in most if not all scenarios.
I’ve previously written about “Things to consider when choosing infrastructure” where I discussed avoiding silos and by combining workloads on a modern platform like Nutanix, the environment can be more performant, resilient and obviously scalable.
When you have a product or product/s which have all three of these qualities, you are very likely to be able to deliver a great business outcome.
I’ve previously compared “peak” performance with “real world” performance where I concluded among other things that “Peak performance is rarely a significant factor for a storage solution” and even though it’s very common when doing proof of concepts (POCs), “Do not waste time performing absurd testing of “Peak performance”.
The purpose of this series is to demonstrate how the Nutanix platform performs in all three areas and to show examples to help prospective customers make informed decisions.
These three areas are my primary focus day to day in my role as Principal Architect at Nutanix and I am working to ensure the core of the Nutanix platform continues to improve equally in all areas.
Readers of this series will notice that many of the posts will refer to back to each other and in many cases cover similar areas. This is deliberate as Scalability, Resiliency and Performance are tied together and essential for an enterprise grade solution.
This series will continue to be updated as new capabilities, enhancements etc are released.
I hope this series is informative and helps existing/prospective customers as well as industry analysts learn more about the evolving Nutanix platform.
Scalability
Part 1 – Storage Capacity
Part 2 – Compute (CPU/RAM)
Part 3 – Storage Performance for a single Virtual Machine
Part 4 – Storage Performance for Monster VMs with AHV!
Part 5 – Scaling Storage Performance for Physical Machines
More coming soon.
Resiliency
Index:
Part 1 – Node failure rebuild performance
Part 2 – Converting from RF2 to RF3
Part 3 – Node failure rebuild performance with RF3
Part 4 – Converting RF3 to Erasure Coding (EC-X)
Part 5 – Read I/O during CVM maintenance or failures
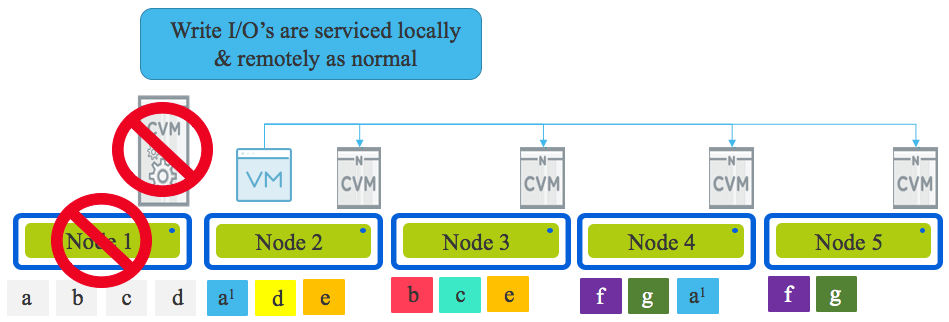
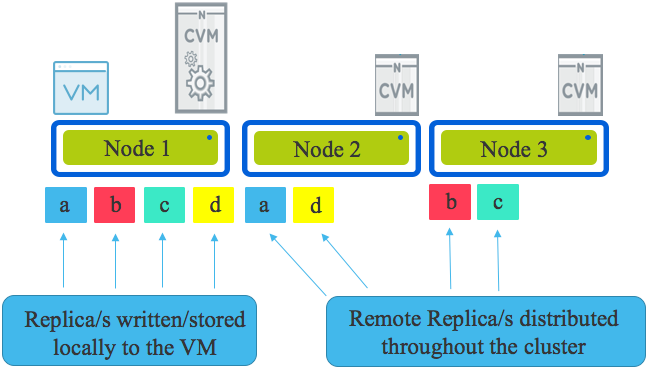
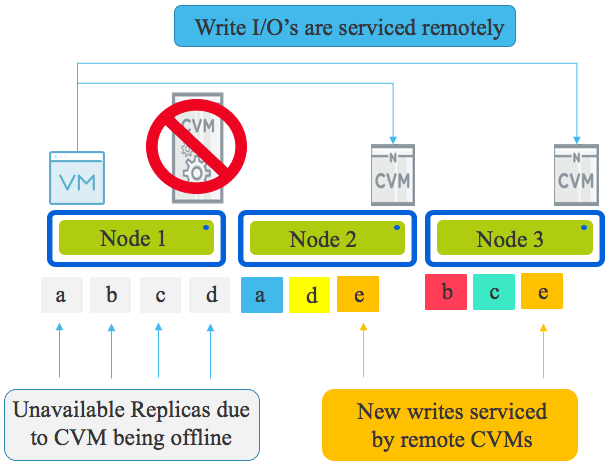
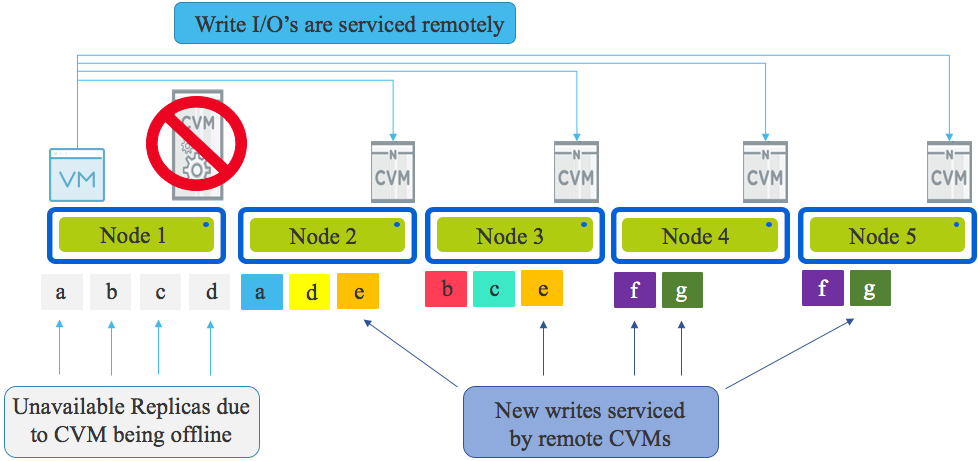
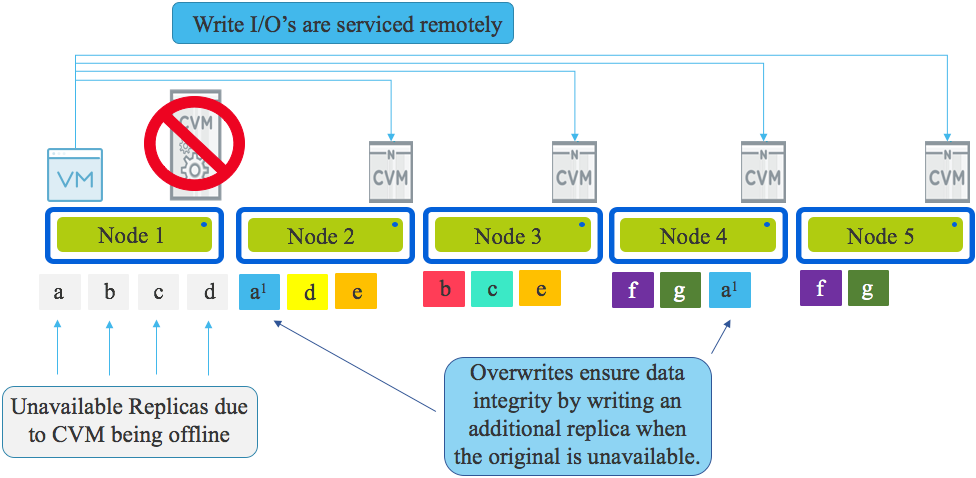
Part 6 – Write I/O during CVM maintenance or failures
Part 7 – Read & Write I/O during Hypervisor upgrades
Part 8 – Node failure rebuild performance with RF3 & Erasure Coding (EC-X)
Part 9 – Self healing
Part 10: Nutanix Resiliency – Part 10 – Disk Scrubbing / Checksums
Bonus: Sizing Nutanix for Resiliency with Design Brews
More coming soon.
Performance
Part 1 – Coming soon.
Referenced Posts:
Things to consider when choosing infrastructure
Enterprise Architecture & Avoiding tunnel vision
Peak performance vs Real World Performance