
For a long time now, VMware & EMC are leading the charge along with other vendors spreading FUD regarding the Nutanix Controller VM (CVM), making claims it uses a lot of resources to drive storage I/O and it being a Virtual Machine (a.k.a Virtual Storage Appliance / VSA) is inefficient / slower than running In-Kernel.
An recent example of the FUD comes from an article written by the President of VCE himself, Mr Chad Sakac who wrote:
… it (VxRAIL) is the also the ONLY HCIA that has a fully integrated SDS stack that is embedded into the kernel – specifically VSAN because VxRail uses vSphere. No crazy 8vCPU, 16+ GB of RAM for the storage stack (per “storage controller” or even per node in some cases with other HCIA choices!) needed.
So I thought I would put together a post covering what the Nutanix CVM provides and giving a comparison to what Chad referred to as a fully integrated SDS stack.
Let’s compare what resources are required between the Nutanix suite which is made up of the Acropolis Distributed Storage Fabric (ADSF) & Acropolis Hypervisor (AHV) and VMware’s suite made up of vCenter , ESXi , VSAN and associated components.
This should assist those not familiar with the Nutanix platform understand the capabilities and value the CVM provides and correct the FUD being spread by some competitors.
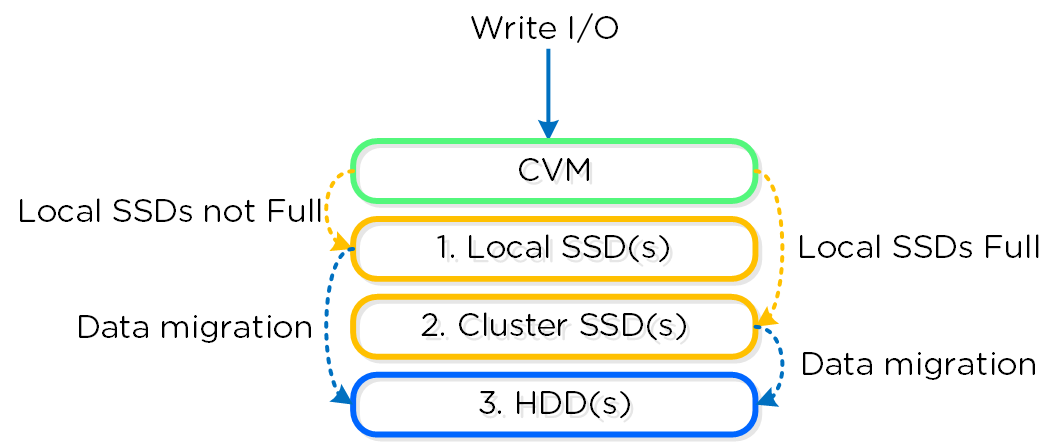
Before we begin, let’s address the default size for the Nutanix CVM.
As it stands today, The CVM by default is assigned 8 vCPUs and 16GB RAM.
What CPU resources the CVM actually uses obviously depends on the customers use case/s so if the I/O requirements are low, the CVM wont use 8 vCPU, or even 4vCPUs, but it is assigned 8vCPUs.
With the improvement in ESXi CPU scheduling over the years, the impact of having more than the required vCPUs assigned to a limited number of VMs (such as the CVM) in an environment is typically negligible, but the CVM can be right sized which is also common.
The RAM allocation is recommended to be 24Gb when using deduplication, and for workloads which are very read intensive, the RAM can be increased to provide more read cache.
However, increasing the CVM RAM for read cache (Extent Cache) is more of a legacy recommendation as the Acropolis Operating System (AOS) 4.6 release achieves outstanding performance even with the read cache disabled.
In fact, the >150K 4k random read IOPS per node which AOS 4.6 achieves on the NX-9040-G4 nodes was done without the use of in-memory read cache as part of engineering testing to see how hard the SSD drives can be pushed. As a result, even for extreme levels of performance, increasing the CVM RAM for Read Cache is no longer a requirement. As such, 24Gb RAM will be more than sufficient for the vast majority of workloads and reducing RAM levels is also on the cards.
Thought: Even if it was true in-kernel solutions provided faster outright storage performance, (which is not the case as I showed here), this is only one small part of the equation. What about management? VSAN management is done via vSphere Web Client which runs in a VM in user space (i.e.: Not “In-Kernel”) which connects to vCenter which also runs as a VM in user space which commonly leverage an SQL/Oracle database which also runs in user space.
Now think about Replication, VSAN uses vSphere Replication, which, you guessed it, runs in a VM in user space. For Capacity/Performance management, VSAN leverages vRealise Operations Manager (vROM) which also runs in user space. What about backup? The vSphere Data Protection appliance is yet another service which runs in a VM in user space.
All of these products require the data to move from kernel space into user space, So for almost every function apart from basic VM I/O, VSAN is dependant on components which are running in user space (i.e.: Not In-Kernel).
Lets take a look at the requirements for VSAN itself.
According to the VSAN design and sizing guide (Page 56) VSAN uses up to 10% of hosts CPU and requires 32GB RAM for full VSAN functionality. Now the RAM required doesn’t mean VSAN is using all 32GB and the same is true for the Nutanix CVM if it doesn’t need/use all the assigned RAM, it can be downsized although 12GB is the recommended minimum, 16GB is typical and for a node with even 192Gb RAM which is small by todays standards, 16GB is <10% which is minimal overhead for either VSAN or the Nutanix CVM.
In my testing VSAN is not limited to 10% CPU usage and this can be confirmed in VMware’s own official testing of SQL in : VMware Virtual SAN™ Performance with Microsoft SQL Server
In short, the performance testing is conducted with 3 VMs each with 4 vCPUs each on hosts contained a dual-socket Intel Xeon Processor E5-2650 v2 (16 cores, 32 threads, @2.6GHz).
So assuming the VMs were at 100% utilisation, they would only be using 75% of the total cores (12 of 16). As we can see from the graph below, the hosts were almost 100% utilized, so something other than the VMs is using the CPU. Best case, VSAN is using ~20% CPU, with the hypervisor using 5%, in reality the VMs wont be pegged at 100% so the overhead of VSAN will be higher than 20%.

Now I understand I/O requires CPU, and I don’t have a problem with VSAN using 20% or even more CPU, what I have a problem with is VMware lying to customers that it only uses 10% AND spreading FUD about other vendors virtual appliances such as the Nutanix CVM are resource hogs.
Don’t take my word for it, do your own testing and read their documents like the above which simple maths shows the claim of 10% max is a myth.
So that’s roughly 4 vCPUs (on a typical dual socket 8 core system) and up to 32GB RAM required for VSAN, but lets assume just 16GB RAM on average as not all systems are scaled to 5 disk groups.
The above testing was not on the latest VSAN 6.2, so things may have changed. One such change is the introduction of software checksums into VSAN. This actually reduces performance (as you would expect) because it provides a layer of data integrity with every I/O, as such the above performance is still a fair comparison because Nutanix has always had software checksums as this is essential for any production ready storage solution.
Now keep in mind, VSAN is really only providing the storage stack, so its using ~20% CPU under heavy load for just the storage stack, unlike the Nutanix CVM which is also providing a highly available management layer which has comparable (and in many cases better functionality/availability/scalability) to vCenter, VUM, vROM, vSphere Replication, vSphere Data Protection, vSphere Web Client, Platform Services Controller (PSC) and the supporting database platform (e.g.: SQL/Oracle/Postgress).
So I comparing VSAN CPU utilization to a Nutanix CVM is about as far from Apples/Apples as you could get, so let’s look at what all the vSphere Managements components resource requirements are and make a fairer comparison.
vCenter Server
Resource Requirements:
Small | Medium | Large
- 4vCPUs | 8vCPUs | 16vCPUs
- 16GB | 24GB | 32GG RAM
Platform Services Controller
Resource Requirements:
- 2vCPUs
- 2GB RAM
vCenter Heartbeat (Deprecated)
If we we’re to compare apples to apples, vCenter would need to be fully distributed and highly available which its not. The now deprecated vCenter Heartbeat used to be able to somewhat provide, so that’s 2x the resources of vCenter, VUM etc, but since its deprecated we’ll give VMware the benefit of the doubt and not count resources to make their management components highly available.
What about vCenter Linked Mode?
I couldn’t find its resource requirements in the documentation so let’s give VMware the benefit of the doubt and say it doesn’t add any overheads. But regardless of overheads, its another product to install/validate and maintain.
vSphere Web Client
The Web Client is required for full VSAN management/functionality and has its own resource requirements:
- 4vCPUs
- 2GB RAM (at least)
vSphere Update Manager (VUM)
VUM can be installed on the vCenter server (if you are using the Windows Installation) to save having management VM and OS to manage, if you are using the Virtual Appliance then a seperate windows instance is required.
Resource Requirements:
- 2vCPUs
- 2GB
The Nutanix CVM provides the ability to do Major and Minor patch updates for ESXi and of course for AHV.
vRealize Operations Manager (vROM)
Nutanix provides built in Analytics similar to what vROM provides in PRISM Element and centrally managed capacity planning/management and “what if” scenarios for adding nodes to the cluster, as such including vROM in the comparison is essential if we want to get close to apples/apples.
Resource Requirements:
Small | Medium | Large
- 4vCPUs | 8vCPUs | 16vCPUs
- 16GB | 32GB | 48GB
- 14GB Storage
Remote Collectors Standard | Large
- 2vCPUs | 4vCPUs
- 4GB | 16GB
vSphere Data protection
Nutanix also has built in backup/recovery/snapshotting capabilities which include application consistency via VSS. As with vROM we need to include vSphere Data Protection in any comparison to the Nutanix CVM.
vSphere Data Protection can be deployed in 0.5 to 8TB as shown below:

The minimum size is 4vCPUs and 4GB RAM but that only supports 0.5TB, for even an average size node which supports say 4TB, 4 vCPUs and 8GB is required.
So best case scenario we need to deploy one VDP appliance per 8TB, which is smaller than some Nutanix (or VSAN Ready) nodes (e.g.: NX6035 / NX8035 / NX8150) so that would potentially mean one VDP appliance per node when running VSAN since the backup capabilities are not built in like they are with Nutanix.
Now what about if I want to replicate my VMs or use Site Recovery Manager (SRM)?
vSphere Replication
As with vROM and vSphere Data protection, vSphere Replication provides VSAN functionality which Nutanix also has built into the CVM. So we also need to include vSphere Replication resources in any comparison to the CVM.
While vSphere Replication has fairly light on resource requirements, if all my replication needs to go via the appliance, it means one VSAN node will be a hotspot for storage and network traffic, potentially saturating the network/node and being a noisy neighbour to any Virtual machines on the node.
Resource Requirements:
- 2vCPUs
- 4GB RAM
- 14GB Storage
Limitations:
- 1 vSphere replication appliance per vCenter
- Limited to 2000 VMs
So scaling beyond 2000 VMs requires another vCenter, which means another VUM, another Heartbeat VM (if it was still available), potentially more databases on SQL or Oracle.
Nutanix doesn’t have this limitation, but again we’ll give VMware the benefit of the doubt for this comparison.
Supporting Databases
The size of even a small SQL server is typically at least 2vCPUs and 8GB+ RAM and if you want to compare apples/apples with Nutanix AHV/CVM you need to make the supporting database server/s highly available.
So even in a small environment we would be talking 2 VMs @ 2 vCPUs and 8GB+ RAM ea just to support the back end database requirements for vCenter, VUM, SRM etc.
As the environment grows so does the vCPU/vRAM and Storage (Capacity/IOPS) requirements, so keep this in mind.
So what are the approx. VSAN overheads for a small 4 node cluster?
The table below shows the minimum vCPU/vRAM requirements for the various components I have discussed previously to get VSAN comparable (not equivalent) functionality to what the Nutanix CVM provides.

As the above only covers the minimum requirements for a small say 4 node environment, things like vSphere Data Protection will require multiple instances, SQL should be made highly available using an Always on Availability group (AAG) which requires a 2nd SQL server and as the environment grows, so do the vCPU/vRAM requirements for vCenter, vRealize Operations Manager and SQL.
A Nutanix AHV environment on the other hand looks like this:

So just 32 vCPUs and 64GB RAM for a 4 node cluster which is 8vCPU and 54GB RAM LESS than the comparable vSphere/VSAN 4 node solution.
If we add Nutanix Scale out File Server functionality into the mix (which is optionally enabled) this increases to 48vCPUs and 100GB RAM. Just 8vCPUs more and still 18GB RAM LESS than vSphere/VSAN while Nutanix provides MORE functionality (e.g.: Scale out File Services) and comes out of the box with a fully distributed, highly available, self healing FULLY INTEGRATED management stack.
The Nutanix vCPU count assumes all vCPUs are in use which is VERY rarely the case. So this comparison is well and truely in favour of VSAN while still showing vSphere/VSAN having higher overheads for a typical/comparable solution with Nutanix providing additional built in features such as Scale out File Server (another distributed and highly available solution) for only a small amount more resources than vSphere/VSAN which does not provide comparable native file serving functionality.
What about if you don’t use all those vSphere/VSAN features and therefore don’t deploy all those management VMs. VSAN overheads are lower, right?
It is a fair argument to say not all vSphere/VSAN features need to be deployed, so this will reduce the vSphere/VSAN requirements (or overheads).
The same however is true for the Nutanix Controller VM.
Its not uncommon where customers don’t run all features and/or have lower I/O requirements for the CVM to be downsized to 6vCPUs. I personally did this earlier this week for a customer running SQL/Exchange this week and the CVM is still only running at ~75% or approx ~4 vCPUs and that’s running vBCA with in-line compression.
So the overheads depend on the workloads, and the default sizes can be changed for both vSphere/VSAN components and the Nutanix CVM.
Now back to the whole In-Kernel nonsense.
VMware also like to spread FUD that their own hypervisor has such high overheads, its crazy to run any storage through it. I’ve always found this funny since VMware have been telling the market for years the hypervisor has a low overhead (which it does), but they change their tune like the weather to suit their latest slideware.
One such example of this FUD comes from VMware’s Chief Technologist, Duncan Epping who tweeted:

The tweet is trying to imply that going through the hypervisor to another Virtual Machine (in this case a Nutanix CVM) is inefficient, which is interesting for a few reasons:
- If going from one VM to another via the kernel has such high overheads, why do VMware themselves recommend virtualizing business critical high I/O applications which have applications access data between VMs (and ESXi hosts) all the time? e.g.: When a Web Server VM accesses an Application Server VM which accesses data from a Database. All this is in one VM, through the kernel and into another VM.
- Because for VSAN has to do exactly this to leverage many of the features it advertises such as:
- Replication (via vSphere Replication)
- vRealize Operations Manager (vROM)
- vSphere Data Protection (vDP)
- vCenter and supporting components
Another example of FUD from VMware, in this case Principal Engineer, Jad El-Zein is implying VSAN has low(er) overheads compared to Nutanix (Blocks = Nutanix “Blocks”):

I guess he forgot about the large number of VMs (and resources) required to provide VSAN functionality and basic vSphere management. Any advantage of being In-Kernel (assuming you still believe it is in fact any advantage) are well and truely eliminated by the constant traffic across the hypervisor to and from the management VMs all of which are not In-Kernel as shown below.

I’d say its #AHVisTheOnlyWay and #GoNutanix since the overheads of AHV are lower than vSphere/VSAN!
Summary:
- The Nutanix CVM provides a fully integrated, preconfigured and highly available, self healing management stack. vSphere/VSAN requires numerous appliances and/or software to be installed.
- The Nutanix AHV Management stack (provided by the CVM) using just 8vCPUs and typically 16GB RAM provides functionality which in many cases exceeds the capabilities of vSphere/VSAN which requires vastly more resources and VMs/Appliances to provide comparable (but in many cases not equivalent) functionality.
- The Nutanix CVM provides these capabilities built in (with the exception of PRISM Central which is a seperate Virtual Appliance) rather than being dependant on multiple virtual appliances, VMs and/or 3rd party database products for various functionality.
- The Nutanix management stack is also more resilient/highly available that competing products such as all VMware management components and comes this way out of the box. As the cluster scales, the Acropolis management stack continues to automatically scale management capabilities to ensure linear scalability and consistent performance.
- Next time VMware/EMC try to spread FUD about the Nutanix Controller VM (CVM) being a resource hog or similar, ask them what resources are required for all functionality they are referring to. They probably haven’t even considered all the points we have discussed in this post so get them to review the above as a learning experience.
- Nutanix/AHV management is fully distributed and highly available. Ask VMware how to make all the vSphere/VSAN management components highly available and what the professional services costs will be to design/install/validate/maintain that solution.
- The next conversation to have would be “How much does VSAN cost compared to Nutanix”? Now that we understand all the resources overheads and complexity in design/implementation/validation of the VSAN/vSphere environment, not to mention most management components will not be highly available beyond vSphere HA. But cost is a topic for another post as the ELA / Licensing costs are the least of your worries.
To our friends at VMware/EMC, the Nutanix CVM says,
“Go ahead, underestimate me”.



















{kind=link}