
In 2014, Nutanix introduced Metro Availability which allows Virtual Machines to have mobility between sites as well as to provide failover in the event of a site failure.
The goal of the Metro Availability (MA) Witness is to automate failovers in case of inter-site network failures or site failures. By the virtue of running the Witness in a different location than the two Metro Sites, it provides the ‘outside’ view that can determine whether a site is actually down or whether the network connection between the two sites is down, avoiding a split-brain scenario that can occur without an external Witness.
The main functions of a Witness include:
- Making failover decision in the event of site or inter-site network failure
- Avoiding split brain where the same container is active on both sites
- Design to handle situations where a single storage or network domain fails
For example, in the case of a Metro Availability (MA) relationship between clusters, a Witness residing in a separate failure domain (e.g.: 3rd site) decides which site should be activated when a split brain occurs due to a WAN failure, or in the situation where a site goes down. For that reason, it is a requirement that there are independent network connections for inter-site connectivity *and* for connections to the witness.
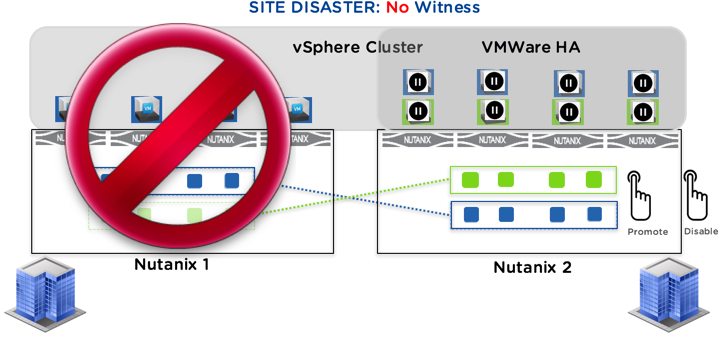
How Metro works without a Witness:
In the event of the primary site failure (the site where the Metro container is currently active) or the links between the sites going offline, the Nutanix administrator is required to manually Disable Metro Availability and Promote the Container to Active on the site where VMs are desired to be ran. This is a quick and simple process, but it is not automated which may impact the Recovery Time Objective (RTO).
In case of a communication failure with the secondary site (either due to the site going down or the network link between the sites going down), the Nutanix administrator can configure the system in two ways:
- Automatic: the system will automatically disable Metro Availability on the container on the primary site after a short pause if the secondary site connection doesn’t recover within that time
- Manual: wait for the administrator to manually take action
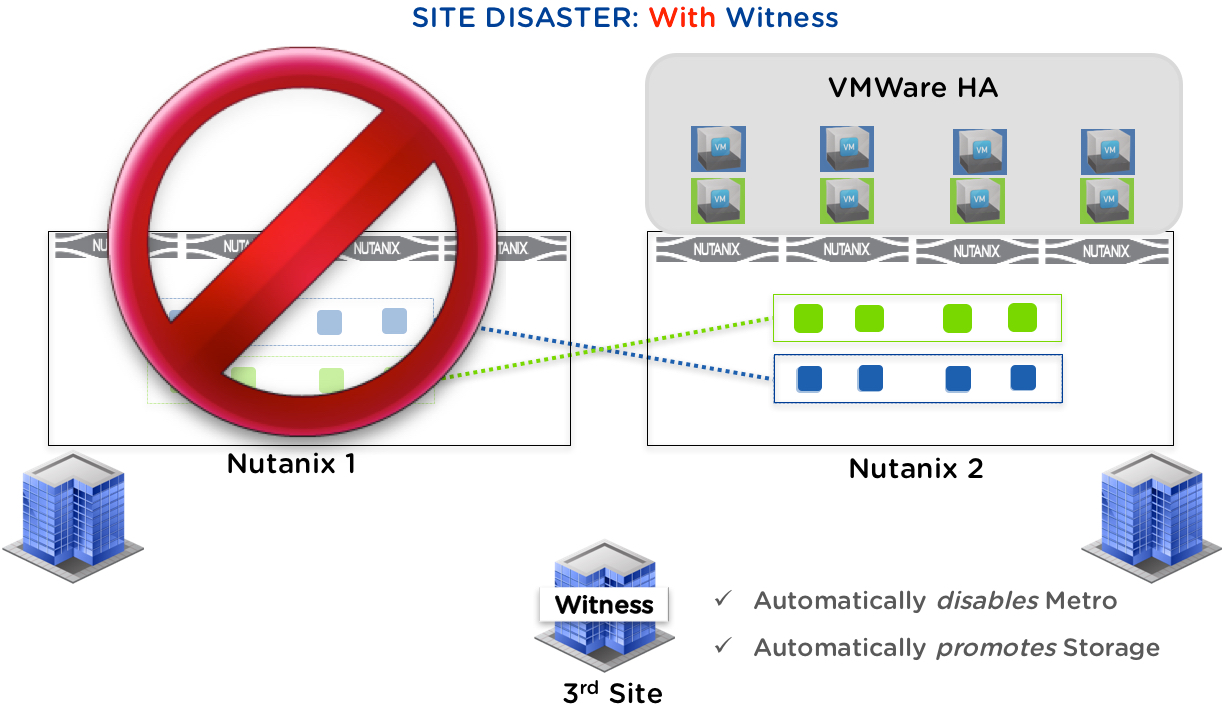
How Metro Availability (MA) works with the witness:
With the new Witness capability, the process of disabling Metro Availability and Promoting the Container in case of a site outage or a network failure is fully automated which ensures the fastest possible RTO. The Witness functionality is only used in case of a failure, meaning a Witness failure itself will not affect VMs running on either site.
Failure Scenarios Addressed by MA Witness.
There are a number of scenarios which can occur and Metro Availability responds differently depending on if MA is configured in “Witness mode”, “Automatic Resume mode” or in “Manual mode”.
The following table details the scenarios and the behaviour based on the configuration of Metro Availability.
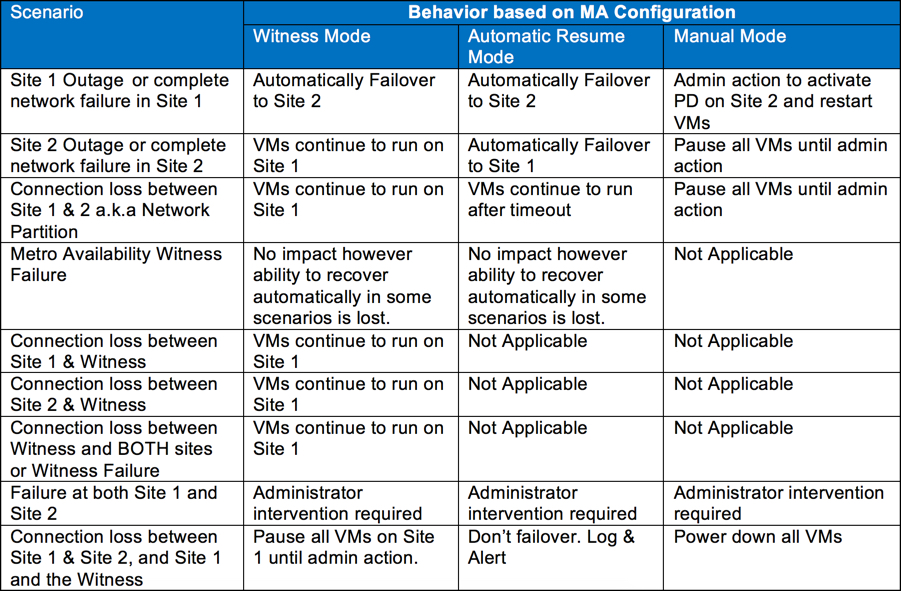
In all cases except a failure at both Site 1 and Site 2, the MA Witness automatically handles the situation and ensures the fastest possible RTO.
The following videos show how each of the above scenarios function.
- Failure Scenario 1 – Site 1 Failure
- Failure Scenario 2 – Site 2 Failure
- Failure Scenario 3 – Network Partition
- Failure Scenario 4 – Witness Failure
- Failure Scenario 5 – Network Outage Site 1
- Failure Scenario 6 – Network Outage Site 2
- Failure Scenario 7 – Complete Network outage
- Failure Scenario 8 – Site 1 Network outage to Witness
- Failure Scenario 9 – Network Partition + Site Failure
Deployment of the Metro Availability (MA) Witness:
The Witness capability is deployed as a stand-alone Virtual Machine, that can be imported on any hypervisor in a separate failure domain, typically a 3rd site. This VM can run on non-Nutanix hardware. This site is expected to have dedicated network connections to Site 1 and Site 2 to avoid a single point of failure.
As a result, MA Witness is quick and easy to deploy, resulting in lower complexity and risk compared to other solutions on the market.
Summary:
The Nutanix Metro Witness completes the Nutanix Metro Availability functionality by providing completely automatic failover in case of site or networking failures.
Related .NEXT 2016 Posts
- What’s .NEXT 2016 – All Flash Everywhere!
- What’s .NEXT 2016 – Acropolis File Services
- What’s .NEXT 2016 – Acropolis X-Fit
- What’s .NEXT 2016 – Any node can be storage only
- What’s .NEXT 2016 – Metro Availability Witness
- What’s .NEXT 2016 – PRISM integrated Network configuration for AHV
- What’s .NEXT 2016 – Enhanced & Adaptive Compression
- What’s .NEXT 2016 – Acropolis Block Services
- What’s .NEXT 2016 – Self Service Restore



