In Part 5 we covered how Read I/O is serviced during CVM maintenance or failure so now we need to cover the arguably more difficult and critical task of servicing write I/O during the same maintenance or failure scenarios.
For those of you who read Part 5, this next section will look familiar. For those who have not read Part 5 I would ask that you please do so but let’s quickly cover off again the basics of how Nutanix ADSF writes and protects data.
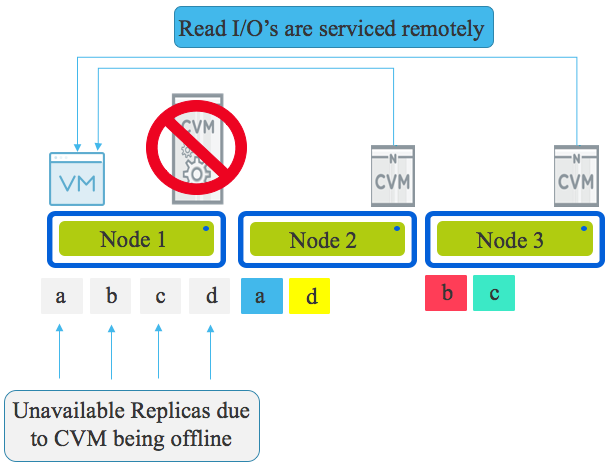
Looking an the following diagram we see a three node cluster with a single Virtual Machine. The VM has written some data represented by a,b,c & d & under normal circumstances all writes will have one replica written to the host running the VM (in this case Node 1) and the other replica (or replicas in the case of RF3) are distributed throughput the cluster based on disk fitness values. The disk fitness values (or what I call “Intelligent replica placement”) ensure data is placed in the most optimal place the first time based on capacity and performance.
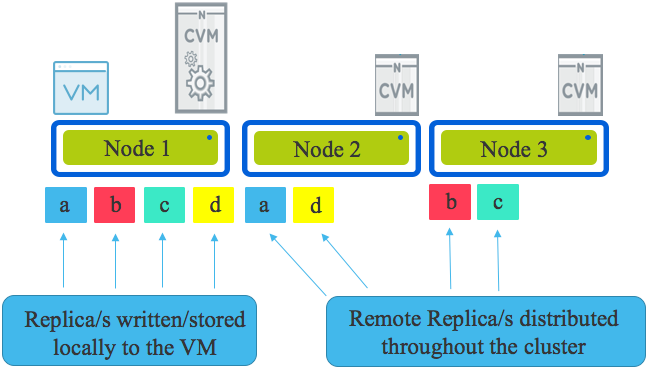
If one or more nodes are added to the cluster, the Intelligent replica placement will send proportionally more replicas to those nodes until the cluster is in a balanced state. In the very unlikely even no new writes are occurring, ADSF has a background disk balancing process which will balance the cluster as a low priority.
Now that we know the basics of how Nutanix protects data using multiple replicas (called “Resiliency Factor”) let’s talk about what happens during a Nutanix ADSF storage layer upgrade.
Upgrades are initiated by a one-click process and performed in rolling style one controller VM (CVM) at a time regardless of the configured Resiliency Factor and if Erasure Coding (EC-X) is used or not. The rolling upgrade put simply takes one CVM offline at a time, performs the upgrade, performs and self check and then rejoins the cluster and then repeats the process on the next CVM.
One of the many advantages of Nutanix decoupling the storage from the hypervisor (i.e.: not embedding storage into the kernel) is that upgrades and even storage layer failures do not impact the running Virtual machines.
VMs do not need to be restarted (i.e.: Like a HA event) nor do they need to migrate (e.g.: vMotion) to another node. VMs continue without interruption to storage traffic even when the local controller is offline for any reason.
If the local CVM is down for maintenance or due to failure, the write I/O is dynamically re-directed throughout the cluster.
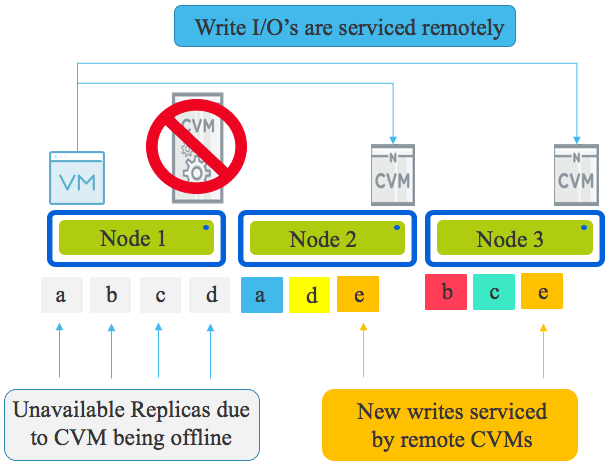
Let’s look at a Write I/O when the CVM local to a VM is offline (for any reason).
The local CVM being offline means the physical drives (NVMe, SSD, HDD etc) are not available meaning the local data (replicas) is unavailable.
All write I/O will be continue to function and remain in compliance with the configured Resiliency Factor (RF), however rather than one replica being written locally, it will be written to a remote CVM over the network as will the other replica/s.
In the example below, we have a three node cluster so the VM on Node 1 is writing both replicas for “E” over the network to Node 2 and 3. This is how new data is serviced.
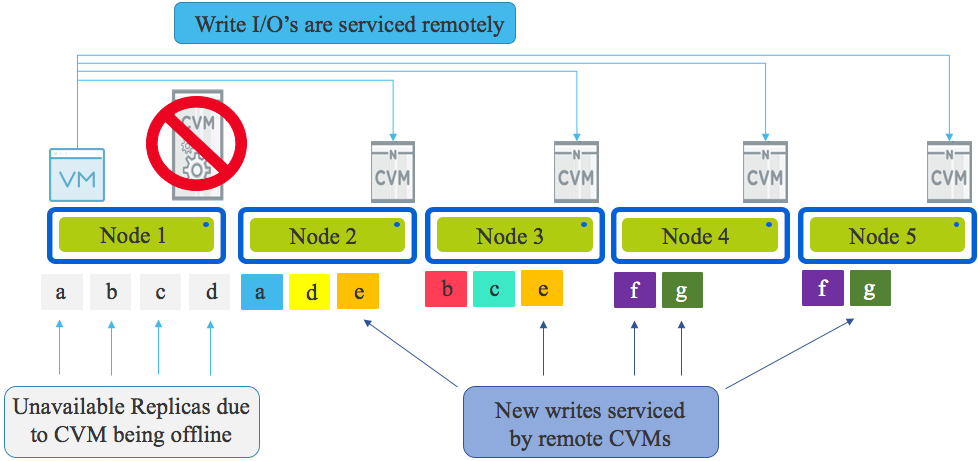
If more nodes existed in the cluster, the write traffic would be distributed evenly using Intelligent Replica Placement across all nodes within the cluster as shown below.
In the event data is being overwritten (as opposed to net new data) and the local replica is unavailable due to the CVM being offline, Nutanix ensures data integrity is maintained by overwriting the available replica and writing a second (or third for RF3) copy on another node in the cluster.
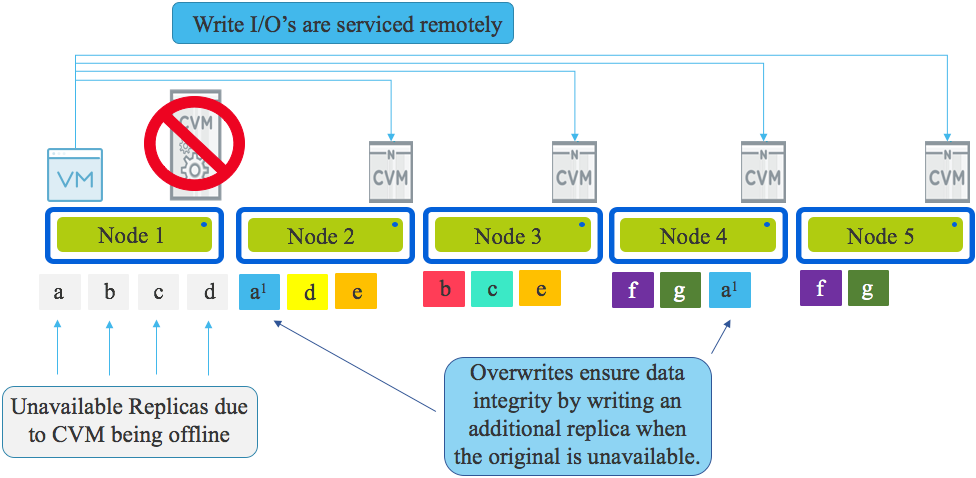
This is critical because if data is not always kept in compliance with it’s resiliency factor (FTT for VMware vSAN) a subsequent drive or node failure would cause data loss.
A major resiliency advantage Nutanix has over vSAN is the fact we always remain in compliance with the configured Resiliency Factor including during all failure and maintenance scenarios. vSAN however does not maintain it’s configured FTT level during all host maintenance and failure scenarios. For VMs on vSAN configured with FTT=1, in the event the host hosting one vSAN disk “object” is offline for maintenance, new overwrites are not protected so a single drive failure can result in data loss.
Chief Technologist at VMware, Duncan Epping recently posted an article titled: “VSAN 6.2 : Why going forward FTT=2 should be your new default” where he recommended FTT=2 as the new default for vSAN customers.
I have to agree with Duncan, but I wouldn’t say vSAN should be set to FTT=2, I would say it MUST be set to FTT=2 as FTT=1 creates a single point of failure for over-writes during maintenance or failures and this is unacceptable for most production workloads with VDI being one of a potential few exceptions in some cases.
Nutanix on the other hand does not have the same architectural flaw as vSAN and as such, RF2 is extremely resilient and suitable for even the most critical environments as explained in this series.
That and the fact ADSF is able to restore resiliency in such a timely manner, RF2 has far superior resiliency compared to vSAN FTT=1.
In the next part we will cover the critically important topic of how VMs are impacted during hypervisor (ESXi, Hyper-V, XenServer and AHV) upgrades.
Summary:
- Write I/O continues uninterrupted if the local CVM is offline
- Write I/O is distributed throughout the cluster evenly thanks to Intelligent Replica Placement
- All new data is written in compliance with the configured Resiliency Factor
- Overwrites of existing data is always written in compliance with the configured Resiliency Factor by writing a new replica where the original replica is not available.
- Data integrity is ALWAYS maintained regardless of a CVM being under maintenance or failure.
- Nutanix RF2 is more resilient than vSAN FTT=1 despite each claiming to maintain two copies of data.
Index:
Part 1 – Node failure rebuild performance
Part 2 – Converting from RF2 to RF3
Part 3 – Node failure rebuild performance with RF3
Part 4 – Converting RF3 to Erasure Coding (EC-X)
Part 5 – Read I/O during CVM maintenance or failures
Part 6 – Write I/O during CVM maintenance or failures
Part 7 – Read & Write I/O during Hypervisor upgrades
Part 8 – Node failure rebuild performance with RF3 & Erasure Coding (EC-X)
Part 9 – Self healing
Part 10: Nutanix Resiliency – Part 10 – Disk Scrubbing / Checksums