
Up to now, Nutanix has used a concept known as “Replication Factor” or “RF” to provide storage layer data protection as opposed to older RAID technologies.
RF allows customers to configure either 2 or 3 copies of data depending on how critical the data is.
When using RF2, the usable capacity of RAW is 50% (RAW divide 2).
When using RF3, the usable capacity of RAW is 33% (RAW divide 3).
While these sound like large overheads, but in reality, they are comparable to traditional SAN/NAS deployments as explain in the two part post – Calculating Actual Usable capacity? It’s not as simple as you might think!
But enough on existing features, lets talk about an exciting new feature, Erasure coding!
Erasure coding (EC) is a technology which significantly increases the usable capacity in a Nutanix environment compared to RF2.
The overhead for EC depends on the cluster size but for clusters of 6 nodes or more it results in only a 1.25x overhead compared to 2x for RF2 and 3x for RF3.
For clusters of 3 to 4 nodes, the overhead is 1.5 and for clusters of 5 nodes 1.33.
The following shows a comparison between RF2 and EC for various cluster sizes.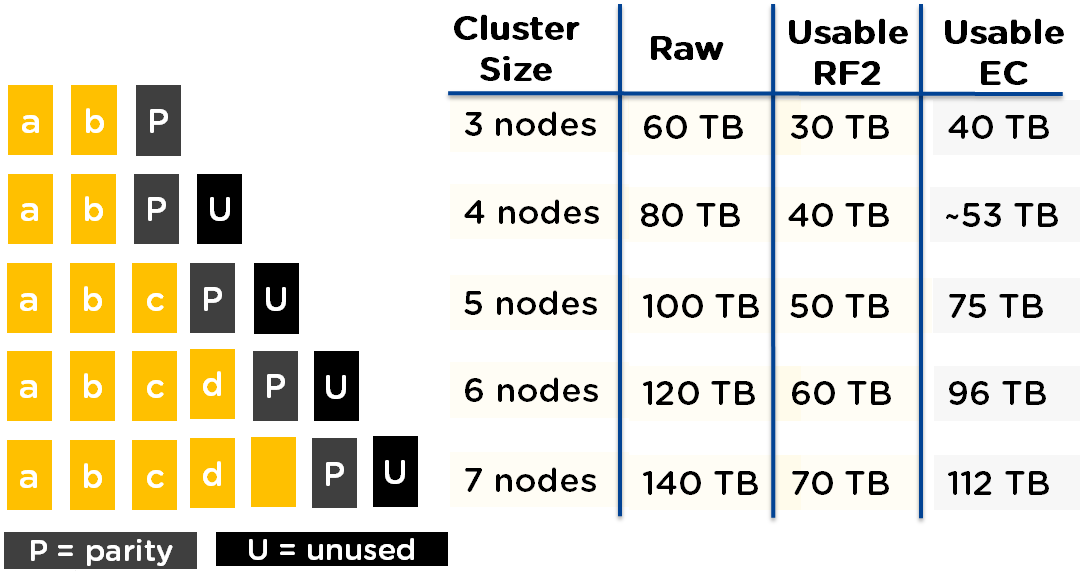 As you can see, the usable capacity is significantly increased when using Erasure Coding.
As you can see, the usable capacity is significantly increased when using Erasure Coding.
Now for more good news, in-line with Nutanix Uncompromisingly Simple philosophy, Erasure Coding can be enabled on existing Nutanix containers on the fly without downtime or the requirement to migrate data.
This means with a simple One-click upgrade to NOS 4.5, customers can get up to a 60% increase in usable capacity in addition to existing data reduction savings. e.g.: Compression.
So there you have it, more usable capacity for Nutanix customers with a non disruptive one click software upgrade…. (your welcome!).
For customers considering Nutanix, your cost per GB just dropped significantly!
Want more? Check out how to scale storage capacity separately from compute with Nutanix!
Related Articles:


