I regularly get asked to compare the resiliency of traditional centralized storage with converged as well as newer technologies such as hyper-converged.
So this post will discuss the problems with RAID and newer hyper-converged solutions using Object based storage for data protection.
This post will discuss two examples below, with Part 2 discussing Hyper-converged solutions using Distributed File Systems.
1. Traditional RAID
2. Hyper-converged Object Based Storage
Starting with Traditional shared storage, and the most common RAID level in my experience, RAID 5.
The below diagram shows a 3 x 4TB SATA drives in a RAID 5 with a Hot Spare.

Now lets look a drive failure scenario. We now have the Hot Spare activate and start rebuilding as shown below.

So this all sounds fine, we’ve had a drive failure, and a spare drive has automatically taken its place and started rebuilding the data.
The problem now is that even in this simplified/small example we have 2 drives (or say 200 IOPS of drives) trying to rebuild onto just a single drive. So the maximum rate at which the RAID 5 can restore resiliency is limited to that of a single drive or 100 IOPS.
If this was a 8 disk RAID 5, we would have 7 drives (or 700 IOPS) trying to rebuild again to only a single drive or 100 IOPS.
There are multiple issues with this architecture.
- The restoration of resiliency of the entire RAID is constrained by the destination drive, in this case a SATA drive which can sustain less than 100 IOPS
- A single subsequent HDD failure within the RAID will cause data loss.
- The RAID rebuild is a high impact activity on the storage controllers which can impact all storage
- The RAID rebuild is an especially high impact activity on the virtual machines running on the RAID.
- The larger the RAID or the capacity drives in the RAID, the longer the rebuild takes and the higher the performance impact and chance of subsequent failures leading to data loss.
Now I’m sure most of you understand this concept, and have felt the pain of a RAID rebuild taking many hours or even days, but with new hyper converged technology this issue is no longer a problem, right?
Wrong!
It entirely depends on how data is recovered in the event of a drive failure. Lets look at an example of an hyper-converged solution using an object store.The below shows a simplified example of a Hyper-converged Object Based Storage with 4 objects represented by Object A,B,C and D in Black, and the 2nd replicated copy of the object represented Object A,B,C and D in Purple.
Note: Each object in the Object Store can be hundreds of GB in size.
Let’s take a look what happens in a disk failure scenario.

From the above diagram we can see a drive has failed on Node 1, which means Object A and Object D’s replica have been lost. The object store will then replicate a copy of Object A to Node 4, and a replica of Object D to Node 2 to restore resiliency.
There are multiple issues with this architecture.
- Object based storage can lack granularity as Objects can be 200Gb+.
- The restoration of resiliency of any single object is constrained by the source drive or node.
- The restoration of resiliency of any single object is also constrained by the destination drive or node.
- The restoration of multiple objects (such as Object A & D in the above example) is constrained by the same drive or node which will result in contention and slow the process of restoring resiliency to both objects.
- The impact of the recovery is High on virtual machines running on the source and destination nodes.
- The recovery of an Object is constrained by the source and destination node per object.
- Object stores generally require a witness, which is stored on another node in the cluster. (Not illustrated above)
It should be pointed out, where SSDs are used for a write cache, this can help reduce the impact and speed up recovery in some cases, but where data needs to be recovered from outside of cache, i.e.: A SAS or SATA drive, the fact writes go to SSD makes no difference as the writes are constrained by the read performance.
Summary:
Traditional RAID used by SAN/NAS and newer Hyper-converged Object based storage both suffer similar issue when recovering from drive or node failures which include:
- The restoration of resiliency is constrained by the source drive or node
- The restoration of resiliency is constrained by the destination drive or node
- The restoration is high impact on the desination
- The recovery of one object is constrained by the network connectivity between just two nodes.
- The impact of the recovery is High on any data (such as virtual machines) running on the RAID or source/destination node/s
- The recovery of RAID or an Object is constrained by a single part of the infrastructure being a RAID controller / drive or a single node.
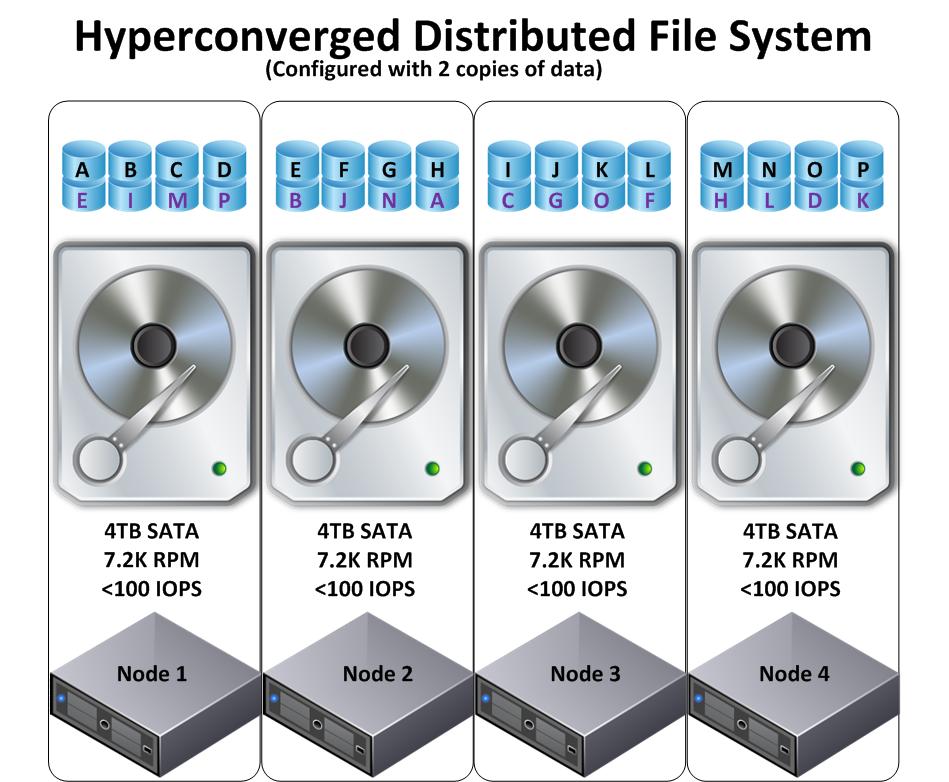
In Part 2, we will look at the Hyper-converged Distributed File Systems.