
At this stage of the series the cluster has been converted from RF2 to RF3, now the customer want’s to get some capacity efficiency without impacting resiliency. We will now look at the process and speed of enabling Erasure Coding (EC-X).
As discussed in , Nutanix EC-X is performed as a background task and only on Write Cold data meaning the configured RF is completed as normal and then as a post process EC-X is performed to ensure the write process is not potentially slowed by requiring numerous nodes within the cluster to participate in the initial write I/O.
For more detailed information on Nutanix EC-X implimentation, see my Nutanix – Erasure Coding (EC-X) Deep Dive.
What I/O will Nutanix Erasure coding (EC-X) take effect on? Good question, only Write cold data. As such, EC-X savings are realised over time as data becomes cold and as Nutanix ADSF curator scans to perform the background conversion as a low priority task.
How fast does ADSF convert RF2/3 to EC-X stripes? In short, we can do this as fast as the underlying drives can handle as shown in earlier parts of this series, but as EC-X is a space saving technology, it does not make sense to drive it as fast as say a node or drive failure operation as no data is at risk.
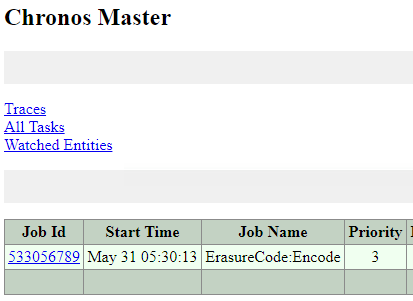
So under the covers the “ErasureCode:Encode” task is a Priority 3 as shown below, whereas a node/disk failure task is priority 1.
In cases where a customer wishes to encode their data as fast as possible this can be achieved in many way, including by enabling “curator maintenance mode” which basically removes soft limits and allows curator to drive as much background I/O as the cluster can handle, but this should only be used under supervision of Nutanix support so I won’t be sharing how to do this publicly.
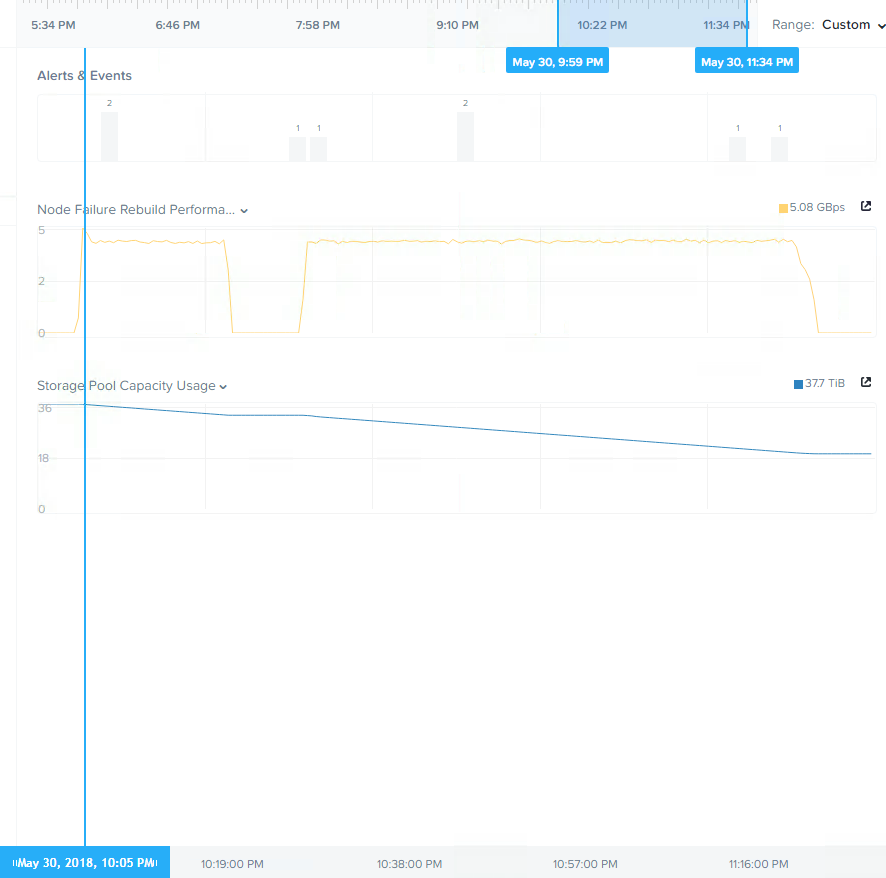
Below is the throughput and storage pool usage after applying EC-X. The reason for the dip in the middle is because I enabled EC-X part way through a background curator scan which meant only some data was converted and then I manually trigged another curator full scan which completed the job at a very high and consistent rate of >5GBps.
The below is the resulting capacity optimisation of 1.97:1 which is almost the theoretical maximum of 2:1. The reason EC-X was able to achieve near the maximum is there is no active workload on the cluster during this testing and as a result all the data is “write cold” and available for EC-X to stripe.
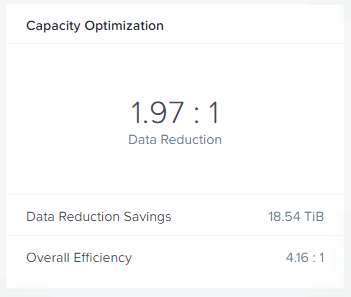
So we have read the entire dataset of around 37.7TB and re-written the data in 4+2 EC-X stripes (4 data, 2 parity) which used around 18TB of space. This resulted in a saving of 18.54TB of physical storage.
If we do some simple math, we have 37.7TB of data read by ADSF and 18TB of EC-X stripes written for a total of approx 56TB of IO serviced by ADSF in less than 90mins.
Summary:
- Nutanix EC-X has no additional write penalty compared to RF3 ensuring optimal write performance while providing up to 2x capacity efficiency at the same resiliency level.
- ADSF uses it’s distributed storage fabric to efficiently stripe data
- Background EC-X striping is a low priority task to minimise the impact on front end virtual machine IO
- ADSF can sustain very high throughput during EC-X (background) operations
- Using RF3 and EC-X ensures maximum resiliency and capacity efficiency resulting in up to 66% usable capacity of RAW storage (up to 2:1 efficiency over RF3)
Index:
Part 1 – Node failure rebuild performance
Part 2 – Converting from RF2 to RF3
Part 3 – Node failure rebuild performance with RF3
Part 4 – Converting RF3 to Erasure Coding (EC-X)
Part 5 – Read I/O during CVM maintenance or failures
Part 6 – Write I/O during CVM maintenance or failures
Part 7 – Read & Write I/O during Hypervisor upgrades
Part 8 – Node failure rebuild performance with RF3 & Erasure Coding (EC-X)
Part 9 – Self healing
Part 10: Nutanix Resiliency – Part 10 – Disk Scrubbing / Checksums