
Many customers and partners have expressed interest in Acropolis since it was officially launched at .NEXT in June earlier this year, and since then lots of questions have been asked around resiliency/availability etc.
In this post I will cover how I/O failover occurs and how AHV load balances in the event of I/O failover to ensure optimal performance.
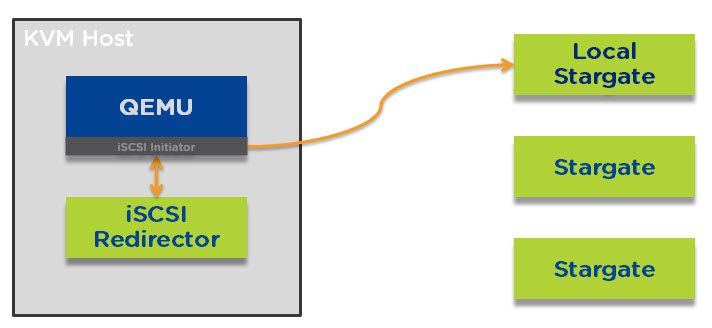
Let’s start with an Acropolis node under normal circumstances. The iSCSI initiator for QEMU connects to the iSCSI redirector which directs all I/O to the local stargate instance which runs within the Nutanix Controller VM (CVM) as shown below.
I/O will always be serviced by the local stargate unless a CVM upgrade, shutdown or failure occurs. In the event one of the above occurs QEMU will loose connection to the local stargate as shown below.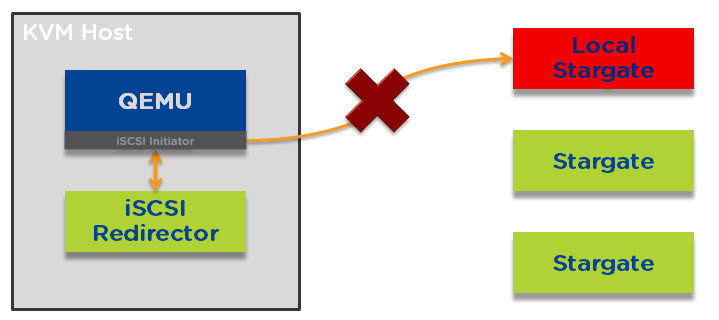
When this loss of connectivity to stargare occurs, QEMU reconnects to the iSCSI redirector and establishes a connection to a remote stargate as shown below.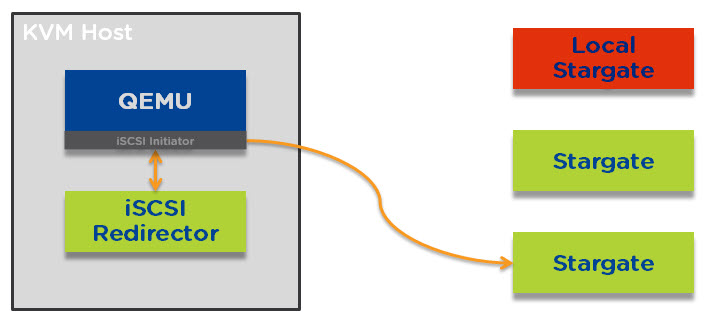
The process of re-establishing an iSCSI connection is near instant and you will likely not even notice this has occurred.
Once the local stargate is back online (and stable for 300 seconds) I/O will be redirected back locally to ensure optimal performance.
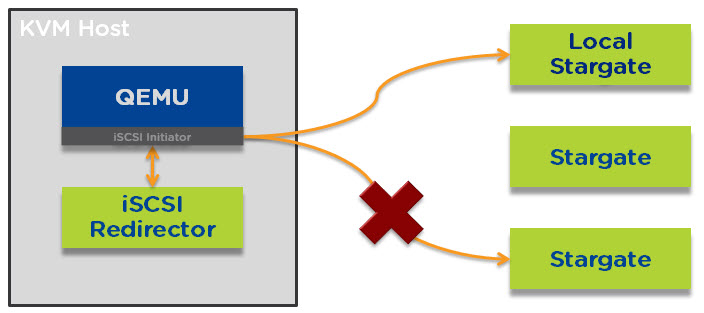
In the unlikely event that the remote stargate goes down before the local stargate is back online then the iSCSI redirector will redirect traffic to another remote stargate.
Next lets talk about Load Balancing.
Unlike traditional 3-tier infrastructure (i.e.: SAN/NAS) Nutanix solutions do not require multi-pathing as all I/O is serviced by the local controller. As a result, there is no multi-pathing policy to choose which removes another layer of complexity and potential point of failure.
However in the event of the local CVM being unavailable for any reason we need to service I/O for all the VMs on the node in the most efficient manner. Acropolis does this by redirecting I/O on a per vDisk level to a random remote stargate instance as shown below.

Acropolis can do this because every vdisk is presented via iSCSI and is its own target/LUN which means it has its own TCP connection. What this means is a business critical application such as MS SQL / Exchange or Oracle with multiple vDisks will be serviced by multiple controllers concurrently.
As a result all VM I/O is load balanced across the entire Acropolis cluster which ensures no single CVM becomes a bottleneck and VMs enjoy excellent performance even in a failure or maintenance scenario.
As i’m sure you can now see, Acropolis provides excellent resiliency and performance even during maintenance or failure scenarios.
Related Posts:
1. Scaling Hyper-converged solutions – Compute only.
2. Advanced Storage Performance Monitoring with Nutanix
3. Nutanix – Improving Resiliency of Large Clusters with Erasure Coding (EC-X)
4. Nutanix – Erasure Coding (EC-X) Deep Dive